Teradata 连接策略2025年3月17日 | 阅读 8 分钟 Teradata 连接策略由优化器使用,以选择最低成本的计划和更好的性能。 策略的选择将基于优化器可用的信息,例如表大小、PI 信息和统计信息。 Teradata 连接策略 有以下几种类型:
合并连接策略当连接基于相等条件时,会发生合并连接方法。 合并连接要求连接的行位于同一个 AMP 上。行根据它们的行哈希进行连接。 合并连接使用四种不同的合并连接策略,基于重分发,将行带到同一个 AMP。 策略 1 第一个合并连接将在连接条件中同时利用两个表的主索引。  上面的内连接侧重于返回两个表匹配时的所有行。 ON 子句至关重要,因为此连接建立了连接(相等)条件。  每个匹配的行都在 JOIN 中从 ON 子句中声明的 Emp = Emp 的地方进行连接。 EMP 是两个表的主索引。第一种合并连接类型效率极高,因为 ON 子句中的两个列都是各自表的主索引。发生这种情况时,无需将任何数据移入 spool,并且连接可以在称为 AMP LOCAL 的地方执行。 Teradata 可以快速完成此连接,并且移动的数据量较少。 策略 2 当一个表的连接基于主索引列与另一个表中的非主索引列时,将使用此策略。  两个表正在基于 DEPT 列进行连接。在部门表中,主索引列是 DEPT。 employee 表的主索引列是 EMP。主要目标是将来自每个表的行放在同一个 AMP 上。 Teradata 优化器可以选择多种选项来完成此任务,例如:
 策略 3 当两个表都不是基于任何一个表的主索引进行连接时,将使用此策略。在这种情况下,Teradata 将把两个表重新分发到 spool 中,并按哈希码对其进行排序。 当我们想要重分发并按哈希码排序时,我们只需哈希非主索引列,并将它们移动到 AMP 的 spool 中,在那里按哈希进行排序。 完成此操作后,所有 AMP 上的适当行将一起出现在 spool 中。  部门表的主索引是 DEPT,经理表的主索引是 LOC。在这种情况下,此连接相等所使用的两个列都不是主索引列。 由于 ON 子句中选择的列都不是各自表的主索引,因此需要对两个表的行进行重新哈希并重新分发到 SPOOL 中。因此,两个表都根据 ON 子句中的列进行了重分发。  此过程的下一步是重分发行并将它们定位到匹配的 AMP。 完成此操作后,两个表的行将位于两个不同的 spool 中。每个 spool 中的行将连接在一起,以返回匹配的行。 合并连接策略 4 第四种合并连接策略称为“大表-小表连接”。如果连接的表之一很小,Teradata 可能会选择将较小的表复制到所有 AMP 的计划。 此策略的关键在于,无论表是否是主索引列的一部分,Teradata 仍可以选择将表复制到所有 AMP。 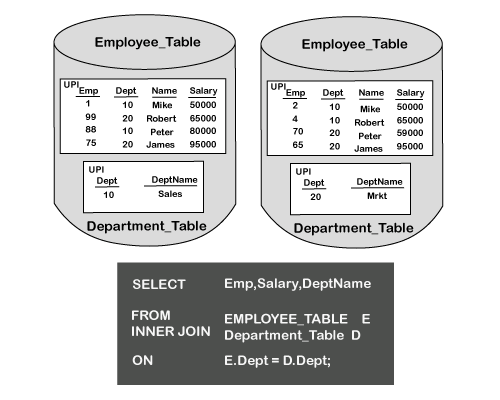 连接中涉及的两个表是 employee 表和 department 表。 Dept 列是连接两个表以进行匹配的连接相等条件。 DEPT 列是部门表中的主索引列。 employee 表的主索引列是 Emp。部门表很小。 要连接这两个表:
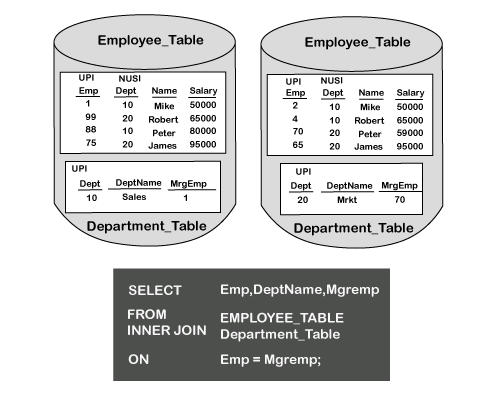
 嵌套连接嵌套连接旨在利用连接语句中一个表的唯一索引类型(唯一主索引或唯一二级索引)来检索单行。 然后,它将该行与正在连接的另一个表中的一行或多行进行匹配。  嵌套连接的连接相等(ON)条件基于 Dept 列。Dept 列是部门表的主索引列。 Dept 列是 employee 表中的二级索引列。嵌套连接可以将单行移至 spool,然后将该行与包含多个匹配项的另一个表进行匹配。 对此连接语句的分析表明,已添加了一个新子句。这被称为 WHERE 选项。 使用 WHERE 选项时,可以从表中检索单行。嵌套连接将始终使用唯一索引来隔离该单条记录,然后将该记录连接到另一个表。 另一个表可以使用索引,也可以不使用。在连接语句中使用索引将提高性能并使用更少的资源,如下方图所示。  由于部门表中只有一行匹配 department =10(基于连接语句中的 AND 选项),Teradata 优化器将选择一个路径将部门表列移至 spool 并将它们复制到所有 AMP。 完成后,匹配项将使用该单条记录(10 和 SALES)继续到未从基本 AMP 移动的第二个表。 嵌套连接因同时使用唯一和非唯一索引而在 OLTP 环境中非常有用。 行哈希连接哈希连接是合并连接的一部分。合并连接的关键在于相等条件,例如连接语句的 ON 子句中的 E.Dept = D.Dept。 只有当每个 AMP 上的一张或两张表能够完全放入 AMP 的内存中时,才可能发生哈希连接。 
 哈希连接过程是将较小的表按行哈希排序,并复制到每个 AMP。 这里的关键是要求将较小的表完全容纳在每个 AMP 的内存中。 Teradata 将使用较大表的连接列来搜索匹配项。行哈希连接效率极高,因为它消除了对较大表进行排序、重分发和复制到 spool 的过程。 复制到 AMP 内存中的行会提高性能,因为行永远不会进入 spool。进入 spool 的行总是涉及磁盘活动。 乘积连接乘积连接会将一个表中的每一行与另一个表中的每一行进行比较。它们之所以被称为乘积连接,是因为它们是将表一中的行数乘以表二中的行数。 例如,如果一个表有六行,另一个表有六行,那么乘积连接将比较 6 x 6 行,最多可能产生 36 行。 很多时候,乘积连接是一个重大的错误,因为两个表中的所有行都会被比较。 Teradata 表可能包含数百万行。如果用户意外地对两个各包含 100 万行的表执行了乘积连接。 结果集将返回一万亿行。为避免乘积连接,请检查语法,确保连接基于相等条件。 在上面的示例中,相等语句读为“WHERE EMP Like '_b%'”,因为此子句不基于两个表之间的公共域条件(e.dept = d.dept),结果就是乘积连接。 乘积连接的另一个原因是在建立别名后未对其使用。因此,首先要确保连接语法中没有缺少 WHERE 子句。 笛卡尔积连接笛卡尔积连接会将一个表中的每一行与另一个表中的每一行连接起来。唯一决定行数的是两个表中总的行数。 如果一个表有 5 行,另一个表有 10 行,那么我们将始终得到 50 行。 大多数情况下,笛卡尔积连接是一个主要问题,因为两个表中的所有行都会被连接。 为避免笛卡尔积连接,请检查语法,确保连接基于相等条件。 在上面的示例中,WHERE 子句缺失,因为此子句缺失,两个表之间的公共域条件(e.dept = d.dept)也缺失。 乘积连接的另一个原因是,在建立别名后未对其使用。 排除连接排除连接有一个主要功能:在连接时排除行。 在上面的示例中,连接使用了 NOT IN 语句。排除连接用于查找在另一个表中没有匹配行的行。 使用 NOT IN 运算符的查询是始终提供排除连接结果的查询类型。在这种情况下,此查询将查找属于部门 10 且不是经理的所有员工。 这些连接总是涉及全表扫描,因为 Teradata 需要比较每条记录来排除需要排除的行。 如果此比较中的两个表都很大,则此类型的连接可能会消耗大量资源。 排除连接的最大问题在于使用 NOT IN 语句时,因为 NULL 被视为未知,所以返回的数据将是 NULL。有两种方法可以避免此问题:
下一主题Teradata 视图 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
