机器学习教程2025年9月2日 | 阅读10分钟 本机器学习教程涵盖了机器学习的基础知识和更复杂的概念。学生和在职专业人士均可受益。 在本机器学习教程中,您将学习机器学习的各种不同方法,包括强化学习、监督学习和无监督学习。本教程还将涵盖回归和分类模型、聚类技术、隐马尔可夫模型以及各种序列模型。 什么是机器学习?机器学习是人工智能(AI)的一个子领域,它处理基于数据生成模型。机器学习没有关于如何解决问题的明确知识或指令。 机器学习模型不是遵循程序员编写的一系列规则,而是根据先前观察到的模式进行操作,从而对先前未观察到的事件进行预测或决策。 机器学习是一个快速发展的技术领域,它使计算机能够自动从以前的数据中学习。为了构建数学模型并根据历史数据或信息进行预测,机器学习采用了各种算法。目前,它被用于各种任务,包括语音识别、电子邮件过滤、Facebook上的自动标签、推荐系统和图像识别。  机器学习如何工作?机器学习系统构建预测模型,从以前的数据中学习,并在接收到新数据时预测其输出。数据量有助于构建一个更准确预测输出的模型,这反过来又影响了预测输出的准确性。 假设我们有一个复杂的预测问题。我们不需要编写代码,只需将数据输入通用算法,这些算法会根据数据构建逻辑并预测输出。机器学习改变了我们对这个问题的看法。以下框图描绘了机器学习算法的操作方式:  机器学习的特点
为什么选择机器学习?机器学习之所以重要,是因为它使计算机无需编程即可从数据中学习。它能轻松识别模式、进行预测和自动化任务。它还能处理大型复杂数据集。 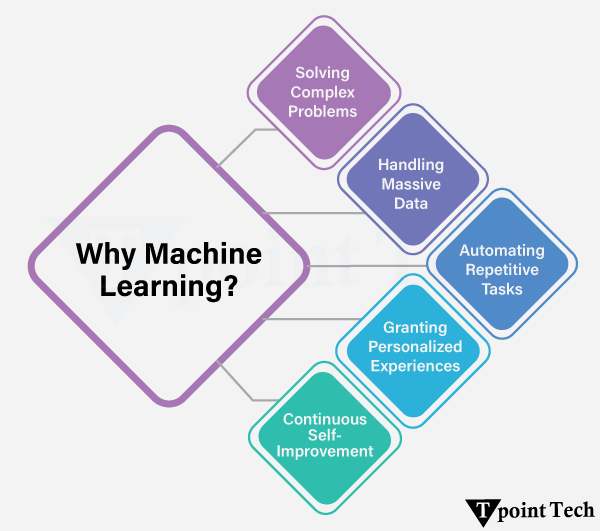 此外,它还提供了多种工具来处理大数据、提高效率、做出更明智的决策并创造新的机会。现在,让我们探讨机器学习在多个行业中的主要重要性。 解决复杂问题许多当代挑战——例如自然语言处理和医学诊断——严重超出了基于规则的编程所能实现的范围。机器学习从数据中获取洞察力,并能提供精确的预测或分类。 示例
处理海量数据随着数字数据激增,手动分析根本不切实际。机器学习系统高效处理庞大数据集,将其转化为可操作的洞察力,并支持实时决策。 示例
自动化重复性任务机器学习通过自动化问题解决,减轻了枯燥、重复的任务,同时实现了高准确性。因此,人工工作量减少,错误也相应降低。 示例
提供个性化体验通过分析用户行为,机器学习定制其推荐,为个人带来更具吸引力和相关性的体验。 示例
持续自我改进与传统系统不同,机器学习模型在处理越来越大的数据集时性能会提高。它们学会识别模式,提高预测准确性,并稳步变得更加智能。 示例
机器学习的分类广义上,机器学习可以分为三种类型  1. 监督学习在监督学习中,将带标签的样本数据提供给机器学习系统进行训练,然后系统根据训练数据预测输出。 系统使用带标签的数据来构建一个模型,该模型理解数据集并学习每个数据集。训练和处理完成后,我们使用样本数据测试模型,以查看它是否能准确预测输出。 将输入数据映射到输出数据是监督学习的目标。监督学习依赖于监督,它类似于学生在教师的指导下学习。垃圾邮件过滤就是监督学习的一个例子。 2. 无监督学习无监督学习是一种机器在没有任何监督的情况下学习的学习方法。 提供给机器的训练数据是一组未标记、未分类或未分类的数据,算法需要在没有任何监督的情况下对这些数据进行操作。无监督学习的目标是将输入数据重构为新的特征或具有相似模式的对象组。 在无监督学习中,我们没有预定的结果。机器试图从大量数据中找到有用的洞察力。它还可以进一步分为两类算法: 3. 强化学习强化学习是一种基于反馈的学习方法,其中学习代理在每次正确动作时获得奖励,在每次错误动作时获得惩罚。代理通过这种反馈自动学习并提高其性能。在强化学习中,代理与环境交互并探索环境。代理的目标是获得最多的奖励点,从而提高其性能。 自动学习手臂运动的机器狗是强化学习的一个例子。 机器学习历史大约40-50年前,机器学习还是科幻小说,但今天它已成为我们日常生活的一部分。从自动驾驶汽车到亚马逊的虚拟助手“Alexa”,机器学习正在让我们的日常生活变得轻松。然而,机器学习背后的思想由来已久,历史悠久。以下是机器学习史上发生的一些里程碑:  1943年:通过电路实现第一个神经网络的引入 1943年,沃伦·麦卡洛克和沃尔特·皮茨构建了第一个由电路组成的人工神经网络。他们的模型表明,计算机可以模拟人类神经元实现的通信,从而奠定了当今神经网络和机器学习技术的基础。 1950年:图灵测试 1950年,艾伦·图灵提出了图灵测试,以确定机器是否能如此令人信服地模拟人类智能,以至于无法与人类对话者区分开来。该测试衡量的是响应与人类的相似性,而不是任何真正的推理能力。尽管它对人工智能领域至关重要,但它也因只衡量模仿而非真正的智能而受到批评。 1952年:计算机跳棋 1952年,开创性的机器学习专家阿瑟·塞缪尔创建了第一个跳棋电脑程序。他将alpha-beta剪枝和minimax算法融入程序中以增强其性能。该系统构成了最早由机器学习算法驱动的游戏演示之一。 1957年:感知器 1957年,弗兰克·罗森布拉特提出了感知器,它被认为是实现人工神经网络的最早算法之一。感知器可以通过调整其参数来从数据中训练,直到找到最佳解决方案。重点是让计算机能够逐步提高其预测能力,并为更复杂的神经网络模型铺平道路。 1967年:最近邻算法 Cover和Hart于1967年首次提出了最近邻算法。该算法旨在根据新数据点与已标记示例的接近程度对其进行分类。这种方法可以从大量数据集中提取模式,并被证明对模式识别、分类和预测建模非常有价值。 1974年:反向传播 在1974年的博士论文中,Paul Werbos首次阐述了反向传播的思想。通过反向传播误差,神经网络重新校准了它们的权重,从而更有效地学习模式。该方法成为现代深度学习的关键基石。 1979年:斯坦福推车 1979年,斯坦福大学的科学家们发布了一款名为“斯坦福推车”的遥控机器人。该机器人在无人干预的情况下,在充满椅子的房间里自主行驶了五个小时。这是自主机器人技术迈出的第一步。 人工智能寒冬 在20世纪70年代末和整个80年代,人工智能研究经历了一段低迷时期,非正式地被称为“人工智能寒冬”。研究资金减少,许多项目因进展甚微和承诺落空而被中止。此时,夸大人工智能研究成果的问题也浮出水面。 1997年:深蓝战胜加里·卡斯帕罗夫 1997年,IBM超级计算机“深蓝”创造了一个前所未有的里程碑,它战胜了世界国际象棋冠军加里·卡斯帕罗夫。这是机器首次击败人类国际象棋大师,表明人工智能可用于在复杂问题/战略问题中超越人类。 2002年:Torch库 2002年,Torch库首次亮相,成为一个用于机器学习的开源平台。由Geoffrey Hinton、Pedro Domingos和Andrew Ng等研究人员开发,Torch提供了该库。尽管该库暂停了积极开发,但其继任者PyTorch此后迅速崛起,如今已成为最广泛采用的框架之一。 2006年:深度学习的兴起 2006年,Geoffrey Hinton在他的论文《深度信念网络的快速学习算法》中首次倡导深度学习。实际上,它证明了深度神经网络可以在图像识别任务中达到人类水平的准确性。这标志着深度学习时代的真正开始。 2011年:Google Brain Google于2011年成立了Google Brain,这是一个人工智能和机器学习研究小组。它的任务是开发能够熟练学习数据、理解自然语言甚至利用常识做出决策的机器。自成立以来,Google Brain取得了一系列突破,其中最著名的是AlphaGo程序。 2014年:DeepFace 2014年,当时名为Facebook的公司(现为Meta)推出了DeepFace,一种基于深度学习的面部识别算法。DeepFace在“野外标记人脸”基准测试中达到了甚至超越了人类的准确性。这是深度神经网络在计算机视觉应用方面的一个重大改进。 2017年:ImageNet挑战赛的转折点 到2017年,深度学习将图像识别提升到了一个全新的水平。在2017年ImageNet挑战赛中,38个团队中有29个达到了95%的准确率阈值。这一成功表明了计算机视觉的快速发展以及深度学习在模式识别任务中的高效性。 生成式AI的崛起 生成式AI的诞生可以追溯到20世纪60年代末的聊天机器人,特别是ELIZA,但该领域最重要的进展是在2014年,伊恩·古德费洛创建了生成对抗网络(GAN)。2017年Transformer架构的推出以及2018年OpenAI的GPT系列在自然语言处理领域掀起了又一场革命。 到2020年,GPT-3展示了卓越的文本生成能力,为生成式AI革命铺平了道路。 2022年:ChatGPT首次亮相 ChatGPT于2022年11月30日推出,并超越成为历史上发展最快的客户程序,不到两个月内达到1亿用户。ChatGPT推广了生成式AI,微软开始将其整合到Bing中,谷歌也推出了Bard。此举标志着全球人工智能领域的蓬勃发展。 2023-2024年:生成式AI加速发展 截至2023年底,ChatGPT表示其每周活跃用户超过1亿,超过200万开发者正在基于OpenAI API开发应用程序。生成式AI已渗透到各行各业,并促进了内容创作、教育、医疗保健和软件开发。 尽管这已变得非常流行,但对就业自动化、隐私和虚假信息的担忧也随之出现。到2024年,能够同时分析文本、图像和音频的模型已成为创新的焦点。 机器学习的现状近年来,机器学习取得了显著进展,其应用无处不在,包括自动驾驶汽车、亚马逊Alexa、聊天机器人和推荐系统。它包括聚类、分类、决策树、支持向量机算法和强化学习,以及无监督学习和监督学习。 如今,人工智能模型可用于进行各种预测,包括气候预测、疾病预测、金融市场分析等。 前提条件在学习机器学习之前,您必须具备以下基本知识,以便轻松理解机器学习的概念:
目标受众我们的机器学习教程旨在帮助初学者和专业人士。 问题我们保证您在学习我们的机器学习教程时不会遇到任何困难。但是,如果本教程中存在任何错误,请在联系表中发布问题或错误,以便我们进行改进。 下一个主题机器学习的应用 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
