数据科学初学者教程2025年3月17日 | 阅读 12 分钟 数据科学已成为21世纪最热门的职业。每个组织都在寻找具有数据科学知识的候选人。在本教程中,我们将介绍数据科学,包括数据科学的职位、工具、组成部分、应用等。 那么,让我们开始吧!  什么是数据科学?数据科学是对海量数据的深入研究,它涉及使用科学方法、不同的技术和算法从原始的、结构化的和非结构化的数据中提取有意义的洞察。 它是一个多学科领域,使用工具和技术来处理数据,以便您可以发现新的、有意义的事物。 数据科学使用最强大的硬件、编程系统和最有效的算法来解决数据相关问题。它是人工智能的未来。 简而言之,我们可以说数据科学就是:
 示例假设我们想驾车从A站到B站。现在,我们需要做出一些决定,例如哪条路线最快,哪条路线不会堵车,哪条路线最具成本效益。所有这些决策因素都将作为输入数据,我们将从这些决策中获得适当的答案,因此这种数据分析称为数据分析,它是数据科学的一部分。 数据科学的需求 几年前,数据量较少,且大部分以结构化形式存在,可以很容易地存储在Excel表格中,并使用BI工具进行处理。 但在今天的世界,数据量变得如此庞大,即每天大约产生 2.5万亿字节 的数据,这导致了数据爆炸。据研究估计,到2020年,地球上每一个人每秒将创建 1.7 MB 的数据。每家公司都需要数据来运营、发展和改进其业务。 现在,处理如此海量的数据对每个组织来说都是一项具有挑战性的任务。因此,为了处理、分析和管理这些数据,我们需要一些复杂、强大和高效的算法和技术,而这种技术就是数据科学。以下是使用数据科学技术的一些主要原因:
数据科学工作根据各种调查,由于对数据科学的需求不断增长,数据科学家已成为21世纪最热门的职业。有些人甚至称之为“21世纪最 热门的职位 ”。数据科学家是能够使用各种统计工具和机器学习算法来理解和分析数据的专家。 数据科学家的平均年薪约为 95,000美元至165,000美元,根据不同的研究,到 2026年 将创造约 1150万个 工作岗位。 数据科学工作类型如果您学习数据科学,您将有机会在这个领域找到各种激动人心的职位。主要的职位如下:
以下是对数据科学中一些关键职位名称的解释。 1. 数据分析师 数据分析师是一个从事海量数据挖掘、数据建模、寻找模式、关系、趋势等工作的人。最终,他会进行可视化和报告,以便进行数据分析以支持决策制定和问题解决过程。 所需技能: 要成为一名数据分析师,您必须在 数学、商业智能、数据挖掘 方面有良好的背景,并具备 统计学 的基本知识。您还应该熟悉一些计算机语言和工具,例如 MATLAB、Python、SQL、Hive、Pig、Excel、SAS、R、JS、Spark 等。 2. 机器学习专家 机器学习专家是处理数据科学中使用的各种机器学习算法的人,例如 回归、聚类、分类、决策树、随机森林 等。 所需技能: 计算机编程语言,如Python、C++、R、Java和Hadoop。您还应该了解各种算法、解决问题的分析能力、概率和统计学。 3. 数据工程师 数据工程师处理海量数据,负责构建和维护数据科学项目的数据架构。数据工程师还负责创建用于建模、挖掘、获取和验证的数据集流程。 所需技能: 数据工程师必须对 SQL、MongoDB、Cassandra、HBase、Apache Spark、Hive、MapReduce 有深入的了解,并掌握 Python、C/C++、Java、Perl 等语言。 4. 数据科学家 数据科学家是专业人士,他们处理海量数据,通过部署各种工具、技术、方法、算法等,提出引人注目的商业见解。 所需技能: 要成为一名数据科学家,应具备 R、SAS、SQL、Python、Hive、Pig、Apache Spark、MATLAB 等技术语言技能。数据科学家必须理解统计学、数学、可视化和沟通技巧。 数据科学的先决条件非技术先决条件
技术先决条件
BI与数据科学的区别BI代表商业智能,也用于业务信息的数据分析:以下是BI与数据科学的一些区别
数据科学组成部分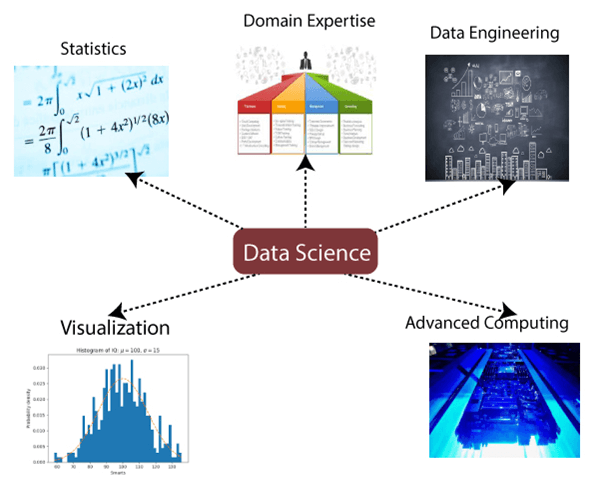 数据科学的主要组成部分如下: 1. 统计学: 统计学是数据科学最重要的组成部分之一。统计学是一种收集和分析大量数值数据并从中发现有意义洞察的方法。 2. 领域专业知识: 在数据科学中,领域专业知识将数据科学紧密结合在一起。领域专业知识意味着某个特定领域的专业知识或技能。在数据科学中,有各种领域需要领域专家。 3. 数据工程: 数据工程是数据科学的一部分,它涉及数据的获取、存储、检索和转换。数据工程还包括向数据添加元数据(关于数据的数据)。 4. 可视化: 数据可视化意味着以视觉方式呈现数据,以便人们可以轻松理解数据的意义。数据可视化使得以视觉方式访问大量数据变得容易。 5. 高级计算: 数据科学的重头戏是高级计算。高级计算涉及计算机程序的源代码的设计、编写、调试和维护。 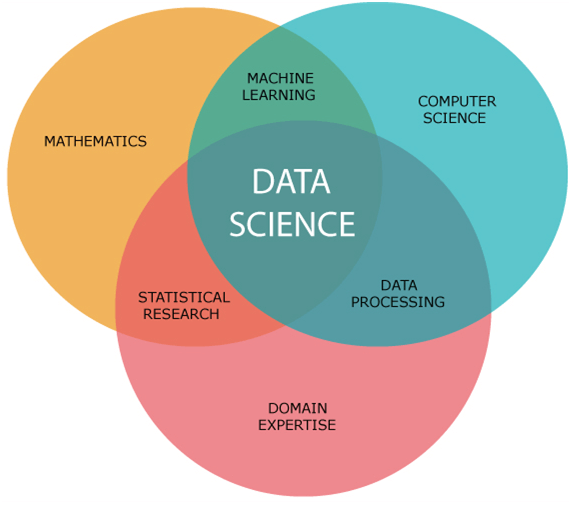 6. 数学: 数学是数据科学的关键部分。数学涉及对数量、结构、空间和变化的研究。对于数据科学家来说,良好的数学知识至关重要。 7. 机器学习: 机器学习是数据科学的支柱。机器学习旨在为机器提供训练,使其能够像人脑一样运作。在数据科学中,我们使用各种机器学习算法来解决问题。 数据科学工具以下是一些数据科学所需的工具:
数据科学中的机器学习要成为一名数据科学家,还需要了解机器学习及其算法,因为在数据科学中,各种机器学习算法被广泛使用。以下是数据科学中使用的部分机器学习算法的名称:
我们在此将简要介绍其中一些重要算法: 1. 线性回归算法: 线性回归是基于监督学习的最受欢迎的机器学习算法。此算法基于回归工作,回归是一种根据独立变量建模目标值的方法。它以线性方程的形式表示,该方程在输入集和预测输出之间存在关系。此算法主要用于预测和预报。由于它显示了输入变量和输出变量之间的线性关系,因此称为线性回归。 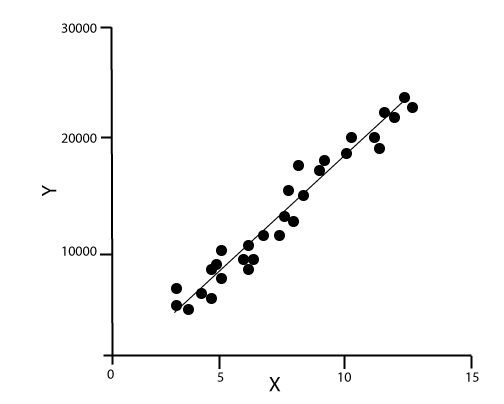 以下方程可以描述 x 和 y 变量之间的关系: 其中,y = 因变量 2. 决策树: 决策树算法是另一种机器学习算法,属于监督学习算法。它是最受欢迎的机器学习算法之一。它可以用于分类和回归问题。 在决策树算法中,我们可以通过使用树形表示来解决问题,其中每个节点代表一个特征,每个分支代表一个决策,每个叶子代表一个结果。 以下是一个工作机会问题的示例: 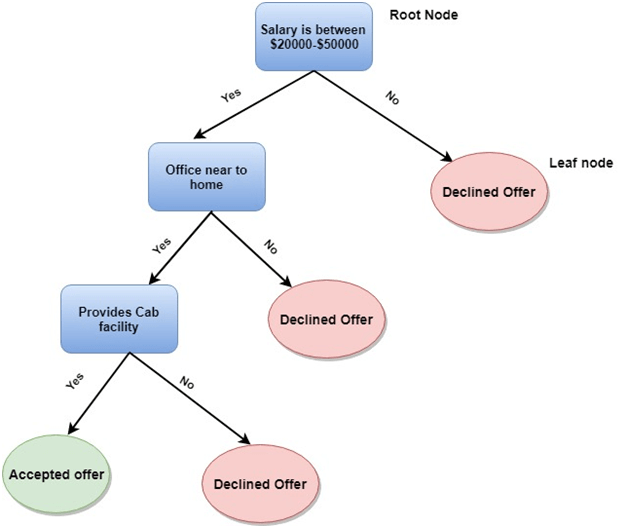 在决策树中,我们从树的根部开始,将根属性的值与记录属性进行比较。在此比较的基础上,我们根据值跟随分支,然后移动到下一个节点。我们继续比较这些值,直到到达带有预测类别值的叶节点。 3. K-均值聚类: K-均值聚类是机器学习中最流行的算法之一,它属于无监督学习算法。它解决了聚类问题。 如果给我们一组具有特定特征和值的项目数据集,我们需要将这些项目集分类为组,那么可以使用 K-均值聚类算法来解决此类问题。 K-均值聚类算法旨在最小化一个目标函数,该函数被称为平方误差函数,其表达式为: 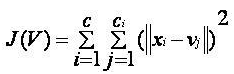 其中,J(V) => 目标函数 如何使用机器学习算法解决数据科学中的问题?现在,让我们了解数据科学中最常见的问题类型以及解决问题的方法。在数据科学中,问题是使用算法解决的,下图展示了针对可能问题的适用算法: 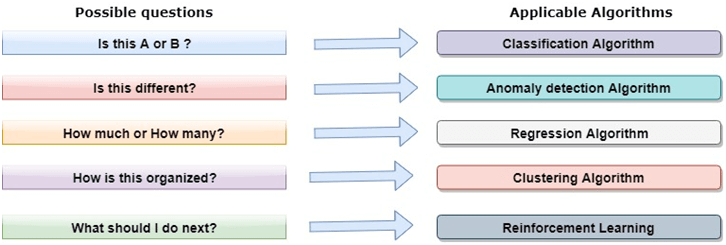 这是A还是B? 我们可以将这种只有两个固定解决方案(例如“是”或“否”、“1”或“0”、“可能”或“不可能”)的问题归类。这类问题可以使用分类算法解决。 这有什么不同? 我们可以将这类问题归结为各种模式,我们需要从中找出异常。这类问题可以使用异常检测算法解决。 多少或多少个? 另一种问题类型是需要数值或数字的问题,例如今天几点了,今天的温度会是多少,这些问题可以使用回归算法解决。 这是如何组织的? 现在,如果您有一个需要处理数据组织的问题,那么可以使用聚类算法来解决。 聚类算法根据特征、颜色或其他共同特征组织和分组数据。 数据科学生命周期数据科学的生命周期如下图所示。 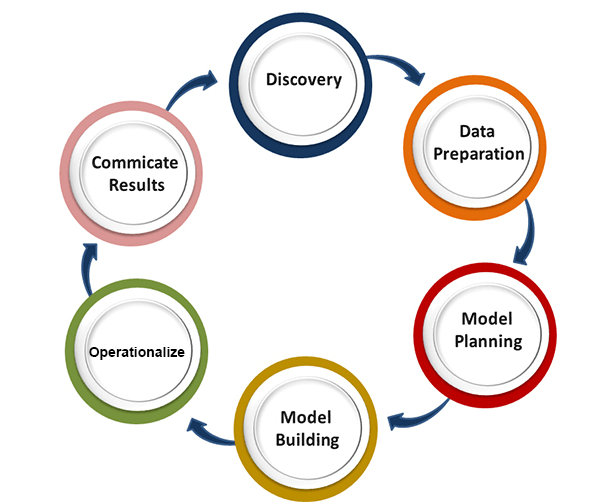 数据科学生命周期的主要阶段如下: 1. 发现: 第一阶段是发现,它涉及提出正确的问题。当你开始任何数据科学项目时,你需要确定基本需求、优先级和项目预算。在此阶段,我们需要确定项目的所有需求,例如人员数量、技术、时间、数据、最终目标,然后我们可以在第一层假设上构建业务问题。 2. 数据准备: 数据准备也称为数据整理。在此阶段,我们需要执行以下任务:
完成上述所有任务后,我们可以轻松地将这些数据用于后续流程。 3. 模型规划: 在此阶段,我们需要确定各种方法和技术来建立输入变量之间的关系。我们将通过使用各种统计公式和可视化工具应用探索性数据分析(EDA),以了解变量之间的关系并查看数据能告诉我们什么。模型规划常用的工具是:
4. 模型构建: 在此阶段,模型构建过程开始。我们将创建用于训练和测试目的的数据集。我们将应用关联、分类和聚类等不同技术来构建模型。 以下是一些常见的模型构建工具:
5. 运行: 在此阶段,我们将交付项目的最终报告,以及简报、代码和技术文档。此阶段在全面部署之前,为您提供了完整的项目性能和其他组件的小规模概览。 6. 沟通结果: 在此阶段,我们将检查我们是否达到了在初始阶段设定的目标。我们将与业务团队沟通发现和最终结果。 数据科学的应用
下一个主题数据网格——重新思考企业数据架构 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
