AWS Athena2025年03月17日 | 阅读 9 分钟 数据分析是一个非常复杂的过程,人们一直在努力使其变得容易。有许多分析工具,甚至连流行的科技巨头亚马逊也提供名为Amazon Athena的AWS服务。本Amazon Athena教程将指导您完成Amazon Athena的基本和高级用法。 Amazon Athena是一个交互式数据分析工具,用于在相对较短的时间内处理复杂查询。它是无服务器的。因此,无需进行设置,也无需进行基础设施管理。它不是数据库服务。因此,您只需为运行的查询付费。只需将数据指向S3,定义所需的架构,然后就可以使用标准SQL开始工作。通过AWS培训了解有关Amazon Web Services的所有信息。 Amazon Athena简介2016年11月20日,亚马逊将其Athena作为一项服务推出。如前所述,Amazon Athena是一项无服务器查询服务,它使用存储在Amazon S3中的标准SQL来分析数据。通过在AWS管理控制台中进行几次点击,客户就可以将Amazon Athena指向存储在Amazon S3中的数据,并使用标准SQL运行查询以在几秒钟内检索结果。 使用Amazon Athena,无需设置或管理任何基础设施,客户只需为运行的查询付费。Amazon Athena会自动扩展,并行执行查询,即使面对大型数据集和复杂查询也能提供快速结果。 Microsoft SQL Server与Amazon Athena的区别
在Athena中创建表我们使用实时资源,因此您只需为运行的查询付费,而不用为使用的数据集付费。如果您想将数据文件上传到Amazon S3,则需要付费。 要查询S3文件数据,您必须有一个与文件结构关联的外部表。我们可以通过两种方式创建外部表
要手动创建外部表,请遵循正确的CREATE DETAILS CREATE EXTERNAL TABLE结构,并指定正确的格式和确切位置。下面提供了一个示例 手动创建外部表创建的外部表存储在AWS Glue Catalog中。Glue Crawler会解析输入文件结构,并创建在Glue Data Catalog中定义的元数据表。 Crawler使用AWS IAM(身份和访问管理)角色来允许存档数据和数据目录。您必须具有将角色传递给Crawler以访问被爬取的Amazon S3路径的权限。 转到AWS Glue,选择**"添加表"**,然后选择**"使用Crawler添加表"**选项。 使用Glue Crawler添加表。为Crawler命名。例如,让我们称之为car-crawler 输入Crawler名称 选择文件所在的**Amazon S3**路径。 如果您打算只查询一个文件,则可以选择S3文件路径或S3文件夹路径来查询具有相同结构的所有文件。 输入Crawler名称选择文件所在的**Amazon S3**路径。 如果您打算只查询一个文件,则可以选择S3文件路径或S3文件夹路径来查询具有相同结构的所有文件。 作为路径。 创建一个具有S3对象权限的IAM角色(您希望查询的目标),或选择一个现有的IAM角色(该角色具有访问S3对象的足够权限)。 选择一个包含外部表的数据库,并可选地选择一个将添加到外部表名称中的前缀。 为外部表选择数据库和前缀点击"完成"以创建Glue Crawler
外部表已在指定的数据库下创建。现在您可以使用此表查询S3对象。
由于我们放置了一个文件,因此查询"select * from json_files"会返回文件中的一条记录。让我们尝试将具有相同结构但另一个文件放入同一个S3文件夹,然后再次查询外部表。 如果查询同一个EXTERNAL表,您将看到返回了两行而不是一行。 当查询同一个外部表时,您将获得两条记录。这是因为S3文件夹中有两个具有所需结构的文件。您可以对数据执行许多操作。例如,以下查询将展开结果集中的数组。 访问Amazon AthenaAthena非常容易访问,并且可以通过以下方式之一进行访问 这些是访问Amazon Athena的一些方法。现在,您对Amazon Athena有了一切重要的了解,让我告诉您Athena的不同功能。 Athena的功能在亚马逊提供的众多服务中,Athena是其中之一。它具有许多使其适合数据分析的功能。让我们逐一查看不同的功能。
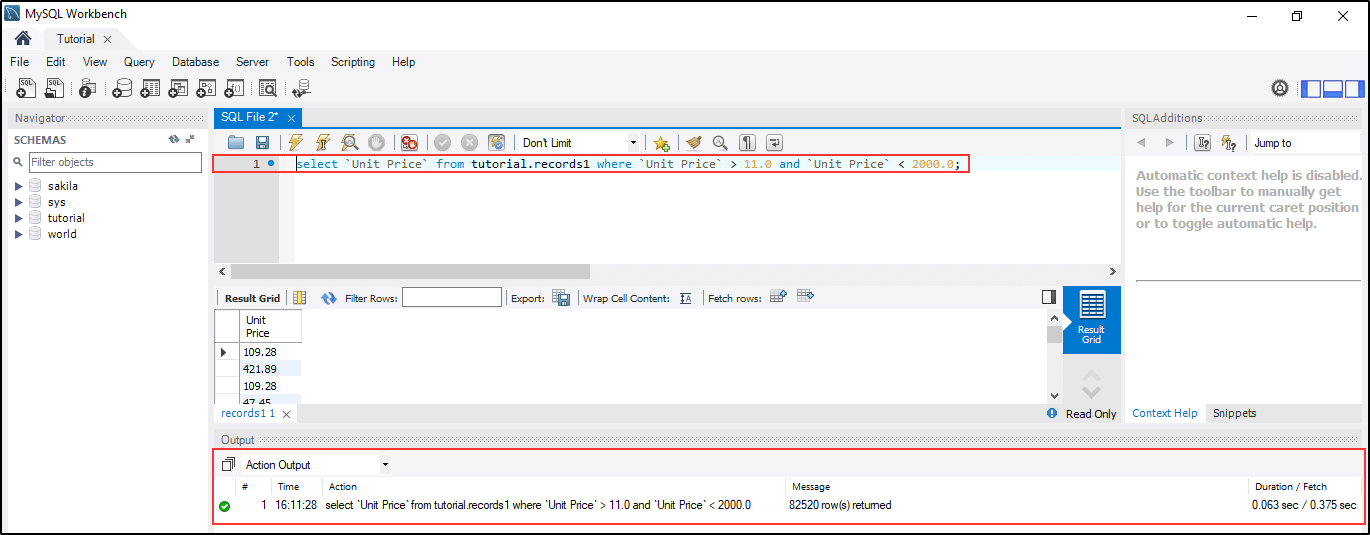
到目前为止,您应该对AWS Athena印象深刻。现在您已经对Athena有了很多了解。让我们动手通过一个小演示来理解Athena的工作。 演示(Amazon Athena与MySQL的比较)在本Amazon Athena教程中,我们将比较MySQL和Athena,并了解即使简单的查询在Athena中执行所需的时间也更少。
MySQL中带指定范围的Select查询。 Amazon Athena有什么局限性?
AWS Athena与AWS Glue自2017年8月首次发布以来,AWS Glue一直作为一个完全托管的提取、转换和加载(ETL)服务运行。它包含三个主要组件
AWS Glue可帮助您查找和转换数据集,并为这些工具的发现和查询做好准备。 因此,您应该能够将AWS Athena与AWS Glue一起使用。后续的数据目录将创建、存储和检索Athena查询的表元数据(或架构)。 使用AWS Athena的优点和缺点是什么?事实证明,AWS Athena是一把双刃剑。使其便宜且易于访问的功能可能在一定程度上限制您。 AWS Athena的优点
AWS Athena的缺点
AWS Athena是如何定价的?正如我们已经说过的,**AWS** Athena遵循一种定价计划,根据您选择在数据分析中运行的查询来收费。 Amazon会计算字节数,然后将其四舍五入到最接近的兆字节,每次查询最少10MB。 对于您能负担得起的每太字节**(TB)**数据,您应该期望支付5美元。同时,失败的查询、用于管理分区的语句以及**数据定义语言(DDL)**语句将不会向您收费。 但这还不是全部。Amazon还使您能够将每查询成本降低**30%**至**90%**。您只需**拆分、压缩**或**转换**数据为列格式。 下一主题什么是AWS Amplify |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India