跨区域复制17 Mar 2025 | 4 分钟阅读 - 跨区域复制是一项功能,可以将数据从一个存储桶复制到另一个存储桶,而后者可能位于不同的区域中。
- 它提供跨存储桶的对象异步复制。假设 X 是源存储桶,Y 是目标存储桶。如果 X 想要将其对象复制到 Y 存储桶,则不会立即复制这些对象。
跨区域复制需要记住的一些要点 - 创建两个存储桶: 在 AWS 管理控制台中创建两个存储桶,其中一个存储桶是源存储桶,另一个是目标存储桶。
- 启用版本控制: 只有在启用两个存储桶的版本控制后,才能实现跨区域复制。
- Amazon S3 使用 SSL 加密跨 AWS 区域传输的数据: 当数据跨不同区域传输时,它也提供安全性。
- 已经上传的对象不会被复制: 如果存储桶中已经存在任何类型的数据,则在执行跨区域复制时,不会复制该数据。
跨区域复制的用例 - 合规性要求
默认情况下,Amazon S3 将数据存储在不同的地理区域或可用区中,以确保数据的可用性。有时,可能存在合规性要求,您希望将数据存储在某些特定区域中。跨区域复制允许您在某些特定区域复制数据以满足要求。 - 最大限度地减少延迟
假设您的客户位于两个地理区域。为了最大限度地减少延迟,您需要在地理位置上更靠近用户的 AWS 区域中维护数据副本。 - 在不同的所有权下维护对象副本: 无论谁拥有源存储桶,您都可以告诉 Amazon S3 将所有权更改为拥有目标存储桶的 AWS 账户用户。这被称为所有者覆盖选项。
让我们通过一个例子来理解跨区域复制的概念。 - 登录 AWS 管理控制台。
- 现在,我们将文件上传到 jtpbucket。 jtpbucket 是我们创建的 s3 存储桶。


- 现在,我们在存储桶中添加两个文件,即 version.txt 和 download.jpg。

- 现在,我们创建一个新存储桶,其名称为 jtp1bucket,位于不同的区域中。

现在,我们在 s3 中有两个存储桶,即 jtpbucket 和 jtp1bucket。 - 单击 jtpbucket,然后转到 jtpbucket 的管理。


- 单击 开始使用 按钮。
- 启用两个存储桶的版本控制。
- 您可以将整个存储桶或标签复制到目标存储桶。假设您要复制整个存储桶,然后单击下一步。


- 创建一个新的 IAM 角色,角色名称为 S3CRR,然后单击下一步。

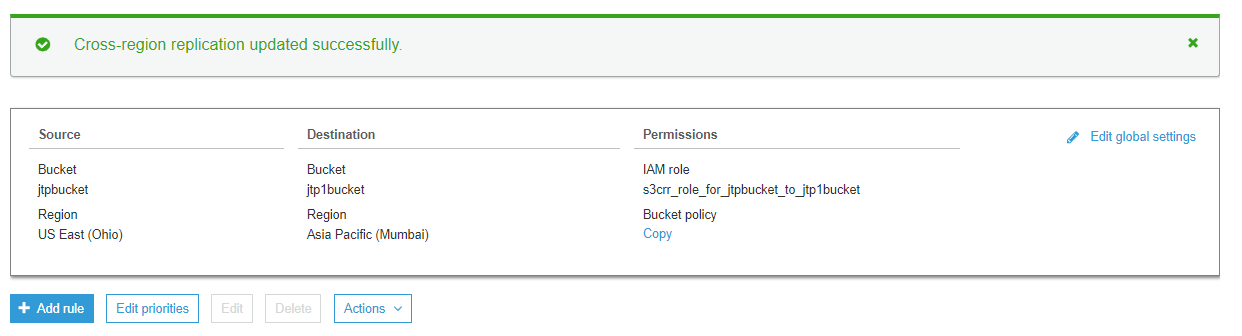
上面的屏幕显示跨区域复制已成功更新。我们还可以看到源存储桶和目标存储桶及其关联的权限。 - 现在,我们将查看文件是否已从 jtpbucket 复制到 jtp1bucket。单击 jtp1bucket。

上面的屏幕显示存储桶是空的。因此,我们可以说对象不会自动从一个存储桶复制到另一个存储桶,我们只能通过 AWS CLI(命令行界面)进行复制。要使用 AWS CLI,您需要安装 CLI 工具。 - 安装完成后,打开 cmd 并键入 aws configure。

- 现在,我们需要生成访问密钥 ID(用户名)和秘密访问密钥(密码)。为了实现这一点,我们首先需要创建一个 IAM 组。


- 选中 AdministratorAccess 策略以通过 AWS CLI 访问 AWS 控制台。
- 现在,创建一个 IAM 用户。
- 使用编程访问添加用户名。



从上面的屏幕中,我们观察到已生成访问密钥和秘密访问密钥。 
- 要查看 S3 存储桶,请运行命令 aws s3 ls。

- 要将 jtpbucket 的对象复制到 jtp1bucket,请运行命令 aws s3 cp?recursive s3://jtpbucket s3://jtp1bucket。

上面的屏幕显示 jtpbucket 的对象已复制到 jtp1bucket。 
从上面的屏幕中,我们观察到原始存储桶中的所有文件都已复制到另一个存储桶,即 jtp1bucket。 注意:如果原始存储桶中进行任何进一步的更改,都将始终复制到其复制的存储桶。要记住的要点- 必须在源存储桶和目标存储桶上都启用版本控制。
- 两个存储桶的区域必须是唯一的。
- 原始存储桶中的所有文件不会自动复制,可以通过 AWS CLI 复制。所有后续文件都会自动复制。
- 文件中的文件无法复制到多个存储桶。
- 删除标记不会被复制。
- 删除版本或删除标记不会被复制。
| 