卷积神经网络的工作原理2025年3月17日 | 阅读 7 分钟 CNN(卷积神经网络或 ConvNet)是一种前馈人工神经网络,其神经元之间的连接模式受到动物视觉皮层的组织的启发。 视觉皮层有一个小的细胞区域,对视觉场的特定区域敏感。我们大脑中的一些单个神经元细胞会对特定方向的边缘做出反应。 例如: 有些神经元在暴露于顶点边缘时会激发,有些神经元在显示水平或对角边缘时会激发。 CNN 利用输入数据中存在的空间相关性。神经网络的每个并发层连接一些输入神经元。该区域称为局部感受野。局部感受野侧重于隐藏神经元。 隐藏的神经元处理上述领域内的输入数据,而不会意识到特定边界之外的变化。 CNN 的工作原理通常,卷积神经网络有三层。我们将借助分类器的示例逐一理解每一层。 它可以对 X 和 O 的图像进行分类。因此,在这种情况下,我们将理解所有四层。 卷积神经网络具有以下层
 在某些更棘手的情况下,X 也可以用这四种形式表示,如右侧所示,所以这些只不过是变形图像的影响。这里,X 和 O 有多种表示形式。 这使得计算机难以识别。但目标是,如果输入信号看起来像它之前见过的先前图像,则“图像”参考信号将与输入信号卷积。 生成的输出信号然后传递到下一层。 考虑下图   计算机通过每个像素的数字来理解图像。 在我们的示例中,我们认为蓝色像素的值为 1,白色像素的值为 -1。 这是我们用来区分主要二元分类中像素的方式。  当我们使用标准技术比较这两个图像时,一个是 X 的正确图像,另一个是 X 的扭曲图像。我们发现计算机无法对 X 的变形图像进行分类。 它正在与 X 的正确表示进行比较。因此,当我们添加这两个图像的像素值时,我们会得到一些东西,因此计算机无法识别它是否是 X。  借助 CNN,我们获取图像的小块,因此这些块或碎片称为过滤器。我们正在寻找两个图片中相同位置的粗略特征匹配。 与整个图像匹配方案相比,CNN 在看到相似性方面做得更好。 我们有这些过滤器,所以考虑一下第一个过滤器,它与变形图像中图像部分的特征完全相等,而且这是一个正确的图像。 CNN 逐段比较图像。 通过在两个图像中的大致相同位置找到粗略的匹配项,CNN 在查看相似性方面比整个图像匹配方案要好得多。  我们有三个特征或过滤器,如下所示。  乘以相应的像素值   添加并除以像素总数  创建一个地图,将过滤器放置在该位置的值 为了跟踪我们创建地图并在该位置放置过滤器数量的特征。  在整个图像中滑动过滤器 现在,使用相同的功能并将其移动到另一个位置并再次执行过滤。  卷积层输出我们将把特征转移到图像的每个其他位置,并查看这些特征如何匹配该区域。 最后,我们将获得一个输出,如下所示;  同样,我们对每个其他过滤器执行相同的卷积。  ReLU 层在这一层中,我们从过滤后的图像中删除每个负值,并用零替换它们。 发生这种情况是为了避免值加起来为零。 修正线性单元 (ReLU) 变换函数仅在输入高于某个量时激活节点。 当数据低于零时,输出为零,但是当信息升高到阈值以上时。 它与因变量具有线性关系。  我们考虑了任何具有上述值的简单函数。 因此,该函数仅在因变量获得该值时才运行。 例如,获得以下值。  删除负值  一个特征的输出  所有特征的输出  池化层在该层中,我们将图像堆栈缩小为更小的尺寸。 池化是在通过激活层之后进行的。 我们通过实施以下 4 个步骤来做到这一点
让我们通过一个例子来理解这一点。 考虑执行池化,窗口大小为 2,步幅也为 2。 计算每个窗口中的最大值 让我们从我们的第一个过滤图像开始。 在我们的第一个窗口中,最大或最高值为 1,因此我们跟踪该值并将窗口移动两个步幅。  在整个图像上移动窗口  通过池化层后的输出  堆叠图层因此,为了在一个图片中获得时间范围,我们在这里从一个 7×7 矩阵获得一个 4×4 矩阵,在输入通过 3 层 - 卷积、ReLU 和池化之后,如下所示  我们将图像从 4×4 减少到更小的东西吗?我们需要在第一次通过后在迭代中执行 3 个操作。 因此,在第二次通过之后,我们得到了一个 2×2 矩阵,如下所示  网络中的最后一层是完全连接的,这意味着先前层的神经元连接到后续层中的每个神经元。 这模仿了高层次的推理,其中考虑了从输入到输出的所有可能的路径。 然后,将缩小的图像放入单个列表中,因此我们经过两次卷积和池化后,并将将其转换为单个文件或矢量。 我们取第一个值 1,然后我们再取 0.55,我们取 0.55,然后我们再取 1。然后我们取 1,然后我们取 0.55,然后我们取 1,然后是 0.55 和 0.55,然后再取 0.55,取 0.55、1、1 和 0.55。所以,这只不过是一个矢量。完全连接层是最后一层,分类发生在这里。在这里,我们采用过滤和缩小的图像,并将它们放入一个列表中,如下所示。  输出当我们输入“X”和“0”时。那么矢量中会有一些元素会很高。 考虑下图,因为我们可以看到对于“X”,有不同的顶部元素,同样,对于“O”,我们有各种高元素。 我的列表中有一些特定的值很高,如果我们重复我们为不同个体成本讨论的整个过程。 哪些会更高,因此对于 X,我们有向量值的第 1、第 4、第 5、第 10 和第 11个元素更高。对于 O,我们有第 2个、第 3个、第 9个和第 12个元素向量更高。我们现在知道,如果我们有一个输入图像,它的第 1个、第 4个、第 5个、第 10个和第 11个元素向量值很高。 我们可以将其归类为 X 类似地,如果我们的输入图像有一个列表,其中包含第 2个、第 3个、第 9个和第 12个元素向量值很高,这样我们就可以组织它 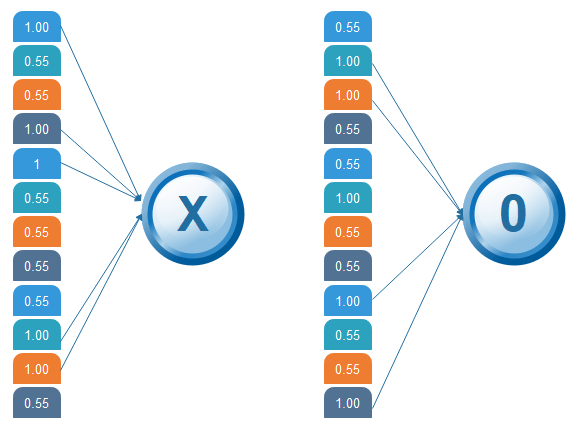 然后第 1个、第 4个、第 5个、第 10个和第 11个值很高,我们可以将图像分类为“x”。这个概念对于其他字母也是类似的 - 当某些值的排列方式是这样时,它们可以被映射到我们需要的实际字母或数字 将输入向量与 X 进行比较在对“X”和“O”完成整个过程的训练之后。然后,我们得到了这个 12 元素矢量,它有 0.9、0.65 所有这些值,那么我们现在如何对它进行分类,无论是 X 还是 O。我们将把它与 X 和 O 的列表进行比较,所以我们已经在之前的幻灯片中得到了这个文件,如果我们注意到我们已经为 X 和 O 获得了两个不同的列表。 我们正在将我们到达的这个新的输入图像列表与 X 和 O 进行比较。首先让我们将它与 X 进行比较,因为对于 X 来说,会有一些值更高,只不过是第 1个、第 4个、第 5个、第 10个和第 11个值。 因此,我们将对它们求和,我们得到了 5= 1+ 1+ 1+ 1+1 次 1,我们得到了 5,我们将对我们的图像向量的对应值求和。 因此,第 1个值是 0.9,第 4个值是 0.87 第 5个值是 0.96,第 10个值是 0.89,第 11个值是 0.94,因此在对这些值求和后,我们得到了 4.56,并将这个值除以 5,我们得到了 0.9。  我们将输入向量与 0 进行比较。 对于 X,我们对 O 执行相同的过程,我们注意到第 2个、第 3个、第 9个和第 12个元素向量值很高。因此,当我们对这些值求和时,我们得到 4,当我们对我们的输入图像的对应值求和时。 我们得到 2.07,当我们除以 4 时,我们得到 0.51。  结果 现在,我们注意到 0.91 是比 0.5 更高的值,因此我们将我们的输入图像与 X 的值进行了比较,我们得到了一个比我们将输入图像与 4 的值进行比较后得到的值更高的值。 因此,输入图像被分类为 X。  CNN 用例步骤:  在这里,我们将训练我们的模型使用不同类型的狗和猫的图像,一旦训练完成。 我们将提供它来分类输入是狗还是猫。  下一个主题CNN 训练 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
