Azure SQL 数据库17 Mar 2025 | 4 分钟阅读 SQL 数据库是微软在数据库领域的旗舰产品。它是一个通用的关系数据库,支持关系数据、JSON、空间和 XML 等结构。Azure 平台完全管理每个 Azure SQL 数据库,并保证无数据丢失和高比例的数据可用性。Azure 自动处理修补、备份、复制、故障检测、潜在的底层硬件、软件或网络故障、部署错误修复、故障转移、数据库升级和其他维护任务。  我们可以通过三种方式实现我们的 SQL 数据库 - 托管实例: 这主要面向本地客户。如果我们在本地数据中心已经有一个 SQL Server 实例,并且希望将其迁移到 Azure,同时对应用程序进行最少的更改并实现最大的兼容性,那么我们就会选择托管实例。
- 单一数据库: 我们可以在 Azure 上部署一个通过逻辑服务器管理其自身资源集的单一数据库。
- 弹性池: 我们可以部署一个数据库池,共享一组通过逻辑服务器管理的资源。
我们可以将 SQL 数据库部署为基础设施即服务。这意味着我们希望在 Azure 虚拟机上使用 SQL Server,但在这种情况下,我们需要负责管理该特定 Azure 虚拟机上的 SQL Server。 购买模式我们有两种方式可以在 Azure 上购买 SQL Server。 - VCore 购买模式: 基于 vCore 的购买模式使我们能够独立地扩展计算和存储资源,匹配本地性能,并优化价格。它还允许我们选择硬件代系。它还允许我们使用 SQL Server 的 Azure 混合权益来节省成本。最适合重视灵活性、控制和透明度的客户。
- DTU 模式: 它基于计算、存储和 IO 资源的捆绑衡量标准。计算的大小以数据库事务单元 (DTU)(用于单个数据库)和弹性数据库事务单元 (eDTU)(用于弹性池)表示。此模型最适合希望使用简单、预配置资源选项的客户。
Azure SQL 数据库服务层- 通用/标准模型: 它基于计算和存储服务的分离。此体系结构模型依赖于 Azure 高级存储的高可用性和可靠性,后者透明地复制数据库文件,并保证在底层基础设施发生故障时零数据丢失。
- 业务关键/高级服务层模型: 它基于数据库引擎进程的集群。SQL 数据库引擎进程和底层 mdf/ldf 文件都放置在同一节点上,并连接到本地 SSD 存储,从而为我们的工作负载提供低延迟。高可用性是使用类似于 SQL Server Always On 可用性组的技术实现的。
- 超大规模服务层模型: 这是基于 vCore 的购买模型中最新的服务层。此层是一个高度可扩展的存储和计算性能层,它利用 Azure 架构来扩展 Azure SQL 数据库的存储和计算资源,超出了通用和业务关键服务层的可用限制。
SQL 数据库逻辑服务器- 它充当多个单个或池化数据库登录名、防火墙规则、审核规则、威胁检测策略和故障转移组的中心管理点。
- 在我们创建 Azure SQL 数据库之前,它必须存在。服务器上的所有数据库都在与逻辑服务器相同的区域内创建。
- SQL 数据库服务不保证数据库相对于其逻辑服务器的位置,并且不公开实例级访问或功能。
- Azure 数据库逻辑服务器是数据库、弹性池和数据仓库的父资源。
弹性池- 它是扩展和管理多个数据库的简单且经济高效的解决方案。弹性池中的数据库位于单个 Azure SQL 数据库服务器上,并以固定价格共享一组资源。
- 我们可以根据基于 DTU 的购买模式或基于 vCore 的购买模式配置池的资源。
- 池的大小始终取决于池中所有数据库所需的总资源。它决定了以下选项
- 数据库在池中使用的最大资源。
- 数据库在池中使用的最大存储字节数。
使用 Azure 门户创建 Azure SQL 数据库步骤 1: 单击创建资源并搜索 SQL 数据库。然后单击创建。 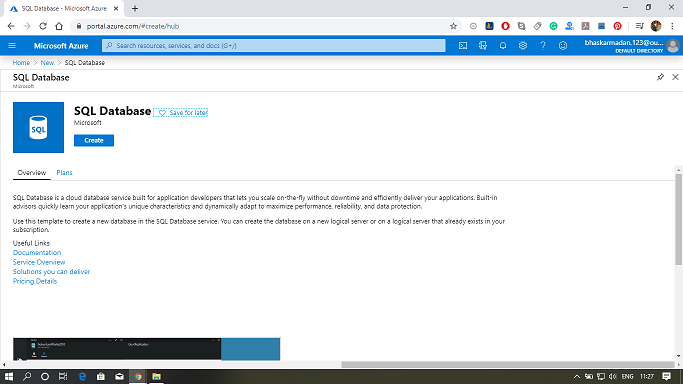 步骤 2: 填写所有必需的详细信息。  步骤 3: 选择一个服务器或创建一个新服务器,如下图所示。  步骤 4: 现在,通过单击“计算 + 存储”选择定价层,如下图所示。  步骤 5: 之后,单击“查看 + 创建”并为您的应用程序创建 SQL 数据库。  步骤 6: 您的 SQL 数据库现已创建,现在单击“转到资源”以配置数据库的其他设置。 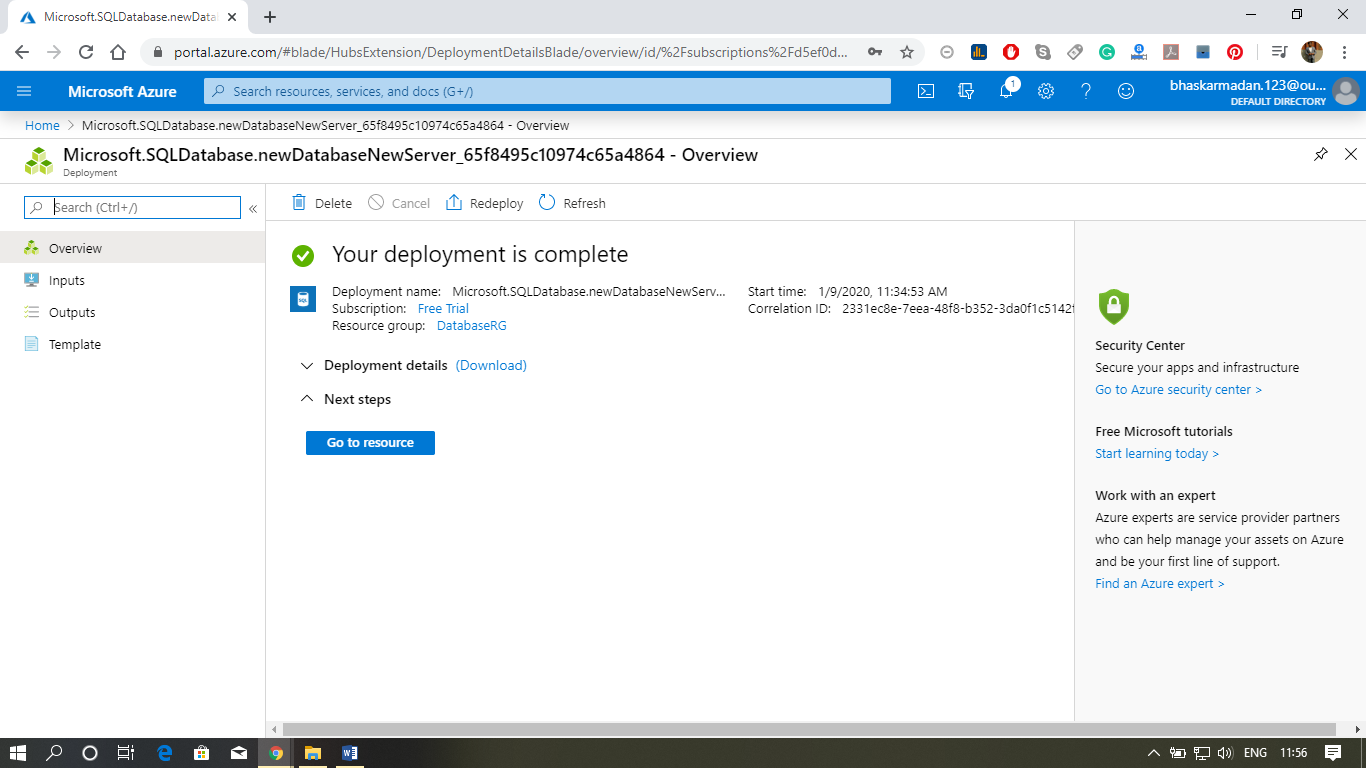
| 