Informatica BDM17 Mar 2025 | 4 分钟阅读 Informatica 大数据管理 (BDM) 产品是一款基于 GUI 的集成开发工具。 组织使用此工具为其大数据平台构建数据质量、数据集成和数据治理流程。 Informatica BDM 具有内置的智能执行器,支持各种处理引擎,例如 Apache Spark、Blaze、基于 Tez 的 Apache Hive 和基于 MapReduce 的 Apache Hive。 Informatica BDM 用于执行数据提取到 Hadoop 集群、集群上的数据处理以及从 Hadoop 集群提取数据。 在 Blaze 模式下,Informatica 映射由 BlazeTM 处理 - Informatica 的原生引擎,作为基于 YARN 的应用程序运行。 在 Spark 模式下,Informatica 映射被转换为 Scala 代码。 在 Hive 和 MapReduce 模式下,Informatica 的映射被转换为 MapReduce 代码,并在 Hadoop 集群上以原生方式执行。 Informatica BDM 与 Hortonworks Data Platform (HDP) Hadoop 集群在所有相关方面无缝集成,包括其默认授权系统。 Ranger 可用于对存储在 HDP 集群中的数据以及元数据强制执行细粒度的基于角色的授权。 Informatica 的 BDM 与 Ranger 在所有执行模式下集成。 Informatica 的 BDM 具有一个智能执行器,使组织能够在现有安全设置的范围内,无缝地在其一种或多种实现方法上运行其 Informatica 映射。 认证身份验证是可靠地确保用户是其声称的身份的过程。 Kerberos 是 Hadoop(包括 Hortonworks Data Platform)上广泛接受的身份验证机制。 Kerberos 协议依赖于密钥分发中心 (KDC),这是一种网络服务,用于颁发允许访问的票证。 Informatica BDM 在 Active Directory 和基于 MIT 的密钥分发中心上都支持 Kerberos 身份验证。 Informatica BDM 中的所有执行模式都支持 Kerberos 身份验证。 授权授权是确定用户是否有权对给定系统执行某些操作的过程。 在 HDP Hadoop 集群中,授权在确保用户仅访问 Hadoop 管理员允许其访问的数据方面起着至关重要的作用。 1. Blaze - YARN 应用程序在 Informatica Blaze 上执行映射时,优化器首先调用 Hadoop 服务以获取元数据信息,例如 Hive 表的分区详细信息。  然后将作业提交到 Blaze Runtime。 该图说明了 Blaze 如何与 Hadoop 服务(例如 Hive Server 2)交互。 在 Blaze 模式下执行 Informatica 映射时,会调用 Hive Metastore 以了解表的结构。 然后,Blaze 运行时将优化的映射加载到内存中。 然后,此映射与相应的 Hadoop 服务交互以读取数据或写入数据。 Hadoop 服务本身与 Ranger 集成,并确保在提供请求之前进行授权。 2. SparkInformatica BDM 可以在 HDP Hadoop 集群上将映射作为 Spark 的 Scala 代码执行。 该图详细说明了使用 Spark 执行模式时涉及的不同步骤。 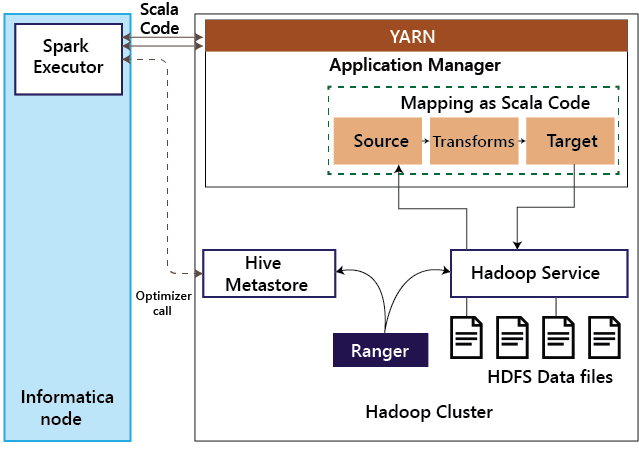 Spark 执行器将 Informatica 的映射转换为 Spark Scala 代码。 作为此转换的一部分,如果涉及 Hive 源或目标,则 Spark 执行器会调用 Hive metastore 以了解 Hive 表的结构并优化 Scala 代码。 然后,此 Scala 代码被提交到 YARN 以供执行。 当 Spark 代码访问数据时,相应的 Hadoop 服务依赖 Ranger 进行授权。 3. 基于 MapReduce 的 HiveInformatica BDM 可以在 Hadoop 集群上将映射作为 MapReduce 代码执行。 下面说明了基于 MapReduce 模式的 Hive 步骤。  在基于 MapReduce 模式执行映射时,Informatica 节点上的 Hive 执行器会将 Informatica 映射转换为 MapReduce 并将作业提交到 Hadoop 集群。 如果涉及 Hive 源或目标,则 Hive 执行器会调用 Hive Meta Store 以了解表结构并相应地优化映射。 由于 MapReduce 与 Hadoop 服务(例如 HDFS 和 Hive)交互,因此 Hadoop 服务会使用 Ranger 授权请求。 4. 基于 Tez 的 Hive可以通过配置更改在 Informatica BDM 中启用 Tez,并且对于开发的映射是透明的。  因此,在基于 Tez 的 Hive 上运行的映射遵循与基于 MapReduce 的 Hive 类似的模式。 在基于 Tez 模式执行映射时,Informatica 节点上的 Hive 执行器会将 Informatica 映射转换为 Tez 作业并将其提交到 Hadoop 集群。 如果涉及 Hive 源或目标,则 Hive 执行器会调用 Hive Meta Store 以了解表结构并相应地优化映射。 由于 Tez 作业与 Hadoop 服务(例如 HDFS 和 Hive)交互,因此 Hadoop 服务会使用 Ranger 授权请求。 下一个主题在 Informatica 中进行分区 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
