科霍宁自组织映射2025年3月17日 | 阅读 24 分钟 自组织映射由 Teuvo Kohonen 在 20 世纪 80 年代 发明,有时也称为 Kohonen 映射。由于它们具有一种特殊性质,能够有效地为输入数据的几个特征创建空间组织的“内部插图”,因此它被用于降维。数据点之间的拓扑关系通过映射得到最佳保留。 考虑下面给出的图 1,尝试理解自组织映射网络的基本结构。它有一个由神经元或单元组成的数组,这些神经元或单元排列在矩形或六边形平面上。这里,单元表示为单个索引 i,使得输入向量 X(t)= [ x1(t), x2(t), ..., xn(t)]T ∈ Rn 与所有单元并行连接,通过不同的权重向量 mi(t) = [ mil(t), mi2(t) ..., min(t) ∈ Rn,这些权重向量在整个自组织学习过程中根据输入数据集进一步调整。  首先,在学习过程开始时,我们将 mi(0) 初始化为一些小的随机值,然后我们反复呈现要分析的数据作为输入向量,可以按原始顺序或随机顺序。每次呈现输入 X(t) 时,我们都会找到所有单元中最佳匹配单元 c,其定义如下:  其中 ||. || 表示欧几里得距离或其他距离度量。我们定义了一个围绕单元的邻域 Nc (t) 作为横向交互的范围,这已在上图中得到演示。基本的权重学习或权重适应过程由以下方程控制: 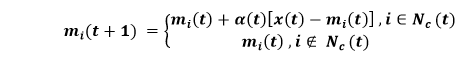 这里,0 <α(f) < 1 表示一个标量因子,它负责控制学习率,学习率必须随时间减小才能获得良好性能。由于横向相互作用,网络在经过足够的自学习步骤后,根据输入数据集的结构呈现出空间“组织”状态。单元也调整到某些特定的输入向量或它们的组,其中每个单元仅响应输入模式集中的某些特定模式。最后,响应不同输入的单元的单元位置倾向于根据输入集中模式之间的拓扑关系进行良好组织。通过这种方式,它有助于在神经映射上最佳保留原始数据空间中的拓扑关系,这就是为什么它被称为 **自组织映射**,因为它使网络在某些应用中非常强大。 自组织映射分析假设单元 i 识别输入向量 X;那么我们将单元 i 或其在地图上的位置称为输入向量 X 的图像。输入集中的每个模式向量在神经地图上只有一个图像,但一个单元可以是许多向量的图像。在这种情况下,如果在一个平面上放置一个格网,并将其用于表示神经地图,那么一个方格对应一个神经元,然后写入输入模式的编号,其图像由相应方格中的单元表示,我们得到如图 2 所示的地图。该地图描绘了输入模式图像在神经地图上的分布,这就是为什么它被称为 SOM 密度图或 SOM 图像分布图。  每当原始模式集中出现分组或聚类时,SOM 都会保留它并在 SOM 密度图上展示,这正是横向竞争的结果。原始空间中相邻的模式会在地图上的某个位置“聚集”它们的图像,由于两个或更多图像密集区域之间的单元受到两个相邻聚类的影响,它们将倾向于不响应其中任何一个。它们将被模仿为一些“**高原**”,代表数据集中的聚类,这些聚类由一些“**山谷**”分隔,这对应于 SOM 密度图上的分类线。请参阅图 2 以更好地理解此现象。分类线在图中用虚线绘制。 这是我们通过自组织映射进行聚类分析的基础。我们分析数据以“训练”SOM,然后经过“学习”后,聚类在 SOM 密度图上得到描绘。 以下是它的一些优点
构建 SOM我们将实现我们的第一个**无监督**深度学习模型,即**自组织映射**,来解决一种新的业务问题,即**欺诈检测**。因此,为了在开始实施之前理解业务问题,假设我们是一名在银行工作的深度学习科学家,并且我们获得了一个数据集,其中包含该银行客户申请高级信用卡的信息。 基本上,这些信息是客户填写申请表时必须提供的数据。我们的任务是检测这些申请中潜在的欺诈行为,这意味着在完成此任务时,我们必须明确列出可能作弊的客户。 因此,我们的目标非常明确。我们必须返回一些东西,即潜在欺诈客户的列表,我们不会建立一个有监督的深度学习模型,并试图预测每个客户是否可能作弊,使用具有二元值的因变量。相反,我们将建立一个无监督深度学习模型,这意味着我们将在一个充满非线性关系的高维数据集中识别一些模式,其中之一将是潜在的欺诈。 我们将以与之前主题相同的方式导入必要的库,以便我们可以继续实现模型。 接下来,我们将导入“**Credit_Card_Applications.csv**”数据集。我们的数据集来自 **UCI 机器学习存储库**,名为 Statlog Australian Credit Approval Dataset,您可以通过点击 http://archive.ics.uci.edu/ml/datasets/statlog+(australian+credit+approval) 简单获取。 导入数据集后,我们将转到变量浏览器并打开它。  从上图中,我们首先需要理解的是,这里的列是属性,即客户的信息,行是客户。之前,当我们说无监督深度学习模型将识别一些模式时,这些模式就是客户。这些客户是我们的神经网络的输入,它们将被映射到一个新的输出空间。在输入空间和输出空间之间,我们有一个由神经元组成的神经网络,每个神经元都初始化为与客户向量相同的权重向量,即一个由 15 个元素组成的向量,因为我们有客户 ID 加上 14 个属性,因此,对于每个观察点或每个客户,该客户的输出将是与该客户最接近的神经元。这个神经元被称为每个客户的**获胜节点**,它是与客户最相似的神经元。 接下来,我们将使用**高斯邻域函数**等邻域函数来更新获胜节点邻居的权重,使其更接近该点。我们必须对输入空间中的所有客户重复此操作,并且每次重复时,输出空间都会减小,随后会失去维度。它一点一点地减小维度。然后,它达到一个点,邻域或输出空间停止减小,此时我们获得了一个二维自组织映射,其中包含所有最终识别出的获胜节点。这有助于我们更接近欺诈,因为事实上,当我们想到欺诈时,我们会想到异常值,因为欺诈被定义为与一般规则相去甚远的东西。 一般规则是申请信用卡时必须遵守的规则。因此,欺诈实际上是二维自组织映射中的异常神经元,因为异常神经元远离遵循规则的大多数神经元。因此,为了检测 SOM 中的异常神经元,我们需要**神经元间平均距离**,这意味着在我们的自组织映射中,对于每个神经元,我们将计算一个神经元与其邻域之间的欧几里得距离的平均值,这样我们就必须手动定义邻域。 但我们为每个神经元定义了一个邻域,并计算我们选择的神经元与邻域中所有神经元之间的欧几里得距离的平均值,我们将其定义为这样做我们将能够检测异常值,因为异常值将远离其邻域中的所有神经元。之后,我们将使用**逆映射**函数来识别输入空间中哪些客户最初与作为异常值的获胜节点相关联。 所以,现在我们已经解开了谜团,我们将开始实施部分。我们将首先将数据集分成两个子集:一个子集包含从客户 ID 到属性 A14(即**A14**)的所有变量,另一个子集是类别,它是一个变量,用于指示客户的申请是否获得批准。因此,**0**表示申请**未**批准,而**1**表示申请**已**批准。这里我们需要分离所有这些变量和类别变量,以便在自组织映射上我们可以清楚地区分未批准申请的客户和已获得批准的客户,因为只有这样才有意义,例如,如果我们想优先检测那些获得批准的欺诈客户,那会更有意义。 导入数据集后,我们将创建这两个子集,为此我们将调用一个变量 X,使其等于 dataset.iloc 以获取我们想要包含在 X 中的观测值的索引。因此,我们将从索引行开始,由于我们想要所有行,因为我们想要所有客户,我们将在这里使用 :,然后由于我们想要除最后一列之外的所有列,我们将使用 :-1。然后,像往常一样,我们将使用 .values,因为它将返回所有由这些索引索引的观测值。 接下来,我们将创建最后一列,并将其命名为 y。由于我们将使用最后一列,所以我们只需将 :-1 替换为 -1,其余代码与我们为 X 变量所做的相同。 执行上述两行代码后,将创建 X 和 Y,我们可以在变量资源管理器窗格中检查。从下图中,我们可以清楚地看到 **X** 包含除最后一个变量之外的所有变量。但是,**y** 包含最后一个变量,它告诉应用程序是否批准。 输出  注意:这里我们将数据集分为 x 和 y,但我们这样做并不是因为我们正在进行有监督学习,我们最终不会尝试创建一个模型来预测 0 或 1。我们只是最终区分已批准的客户和未批准的客户。由于我们正在训练我们的自组织映射,我们只使用 X,因为我们正在进行无监督深度学习,这意味着没有考虑任何独立变量。 接下来,我们将进行**特征缩放**,因为对于深度学习来说,它至关重要,因为需要进行大量计算,我们将从一个包含大量非线性关系的高维数据集开始,所以如果特征经过缩放,我们的深度学习模型将更容易训练。 我们实际上将像处理循环神经网络那样做。我们将使用**归一化**,这意味着我们将所有特征置于 **0** 和 **1** 之间。所以,我们将首先从 **sklearn.preprocessing** 导入 **MinMaxScaler**。然后我们将创建一个 **MinMaxScaler** 类的对象 **sc**,在该类中,我们将传递 **feature_range** 参数,该参数指定我们的标度在 **0** 和 **1** 之间的范围,这被称为归一化。接下来,我们将 **sc** 对象拟合到 **X**,以便 sc 获取 X 的所有信息,例如最小值和最大值,以及它需要将归一化应用于 X 的所有信息。所以,我们将首先将对象拟合到 X,然后我们需要转换 X,即对 X 应用归一化。因此,我们将使用 **sc.fit_transform** 方法,并将其应用于 **X**。 执行上述代码后,我们可以从下图看到 X 已全部归一化,我们确实可以检查所有值都在 0 到 1 之间。 输出  至此,我们完成了数据预处理阶段,现在我们准备训练 SOM 模型。训练模型我们有两种选择:
所以,我们将从另一个开发人员那里获取,这完全取决于在线可用性和开发人员是否已经做了一些好的 SOM 实现。幸运的是,SOM 的一个非常优秀的实现是 **Minisom 1.0**,它由 **Giuseppe Vettigili** 开发,是一个基于 **NumPy** 的自组织映射实现。许可证是 **Creative Commons by 3.0**,这意味着我们可以共享、改编以及对代码做任何我们想做的事情,所以我们完全可以使用它来构建我们的 SOM。 为了开始训练 SOM 模型,我们将首先导入 MiniSom,同时记住在我们的文件资源管理器中的工作目录文件夹中,我们有 minisom.py,这是开发人员自己实现的自组织映射。我们将从 minisom python 文件中导入名为 **MiniSom** 的类。接下来,我们将创建这个类的一个对象,它将是自组织映射本身,它将在 **X** 上进行训练,因为我们正在进行无监督学习,即我们被训练来识别 X 中包含的独立变量内部的一些模式,并且我们不使用因变量的信息。我们不考虑 y 中的信息。 由于该对象本身就是自组织映射,所以我们将其命名为 **som**,然后我们将调用类 **MiniSom**,并在其中传递以下参数。
在此之后,我们将在 X 上训练我们的 som 对象,但在此之前,我们将首先初始化权重,我们将借助 random_weights_init 方法完成此操作,并在该方法中输入 X。然后我们将使用 train_random 方法在 X 上训练 som。在该方法中,我们将传递两个参数;一个是数据,即 X,另一个是 num_iteration,即迭代次数。这里我们尝试 100 次迭代,因为这对于我们的数据集来说已经足够了。 因此,我们刚刚训练了模型,现在我们准备可视化结果,即绘制自组织映射本身,在那里我们可以清楚地看到包含所有最终获胜节点的二维网格,并且对于这些获胜节点中的每一个,我们将获得神经元间平均距离。特定获胜节点的 MID 是获胜节点周围所有神经元在 sigma 定义的邻域内的距离平均值,sigma 是邻域的半径。因此,MID 越高,获胜节点越是异常值,即欺诈,因为对于每个神经元,我们将获得 MID,我们只需选择具有最高 MID 的获胜节点即可。 为了开始构建地图,我们将需要一些特定的函数来完成此操作,因为我们将不使用 matplotlib,因为我们将要制作的图实际上非常特殊。我们不会绘制经典的图表,如直方图或曲线,但我们正在构建自组织地图,因此在某种程度上,我们将从头开始制作。 因此,我们将从 **pylab** 导入我们将使用的函数,这些函数是 **bone、pcolor、colorbar、plot** 和 **show**。接下来,我们将开始制作地图,为此我们首先需要初始化图形,即包含地图的窗口,为此我们将使用 **bone()** 函数。 在下一步中,我们将在地图上放置不同的获胜节点,这通过将神经元间平均距离信息添加到地图上,以显示 SOM 识别出的所有获胜节点来完成。这里我们不会添加所有这些 MID 的数字,而是使用不同的颜色对应 MID 的不同范围值,为此,我们将使用 **pcolor** 函数,并在其中添加 SOM 所有获胜节点的所有 MID 值。为了获得这些平均距离,我们有一个特定的方法,即距离地图方法,实际上,这个距离地图方法将返回一个矩阵中的所有 MID,然后对该矩阵进行转置,以便 pcolor 函数以正确的顺序获取数据,这将通过使用 **som.distance_map().T** 完成。接下来,我们将添加颜色条,它将准确地为我们提供所有这些颜色的图例。  从上图中,我们可以看到图片右侧有图例,这是 MID 的范围值。但这些是从 **0** 到 **1** 缩放的归一化值。因此,我们可以清楚地看到**最高** MID 对应于**白色**,而**最小** MID 对应于**深色**。所以,根据我们之前讨论的,我们已经知道欺诈在哪里,因为它们是由偏离一般规则的异常获胜节点识别的。可以看出,大多数深色都彼此靠近,因为它们的 MID 相当低,这意味着一个获胜节点邻域中的所有获胜节点都靠近中心获胜节点,从而形成了获胜节点的聚类。 由于获胜节点的 MID 值很大,它们是异常值,因此也是潜在的欺诈。在下一步中,我们将通过对获胜节点进行逆映射来获取明确的客户列表,以查看哪些客户与该特定获胜节点相关联。但是我们可以做得比这张地图更好,因为我们可以添加一些标记来区分已获得批准的客户和未获得批准的客户,因为与未获得批准的作弊客户相比,作弊并获得批准的客户与欺诈检测更相关。因此,了解客户在自组织地图中的位置会很好。 所以,在下一步中,我们将在所有位置添加标记,以说明这些获胜节点中的每个客户是否获得了批准。我们将创建两个标记;一些红色圆圈对应于未获得批准的客户,一些绿色方块对应于获得批准的客户。要创建标记,我们首先创建一个名为 **markers** 的新变量,然后创建一个包含两个元素的向量,对应于两个标记,即第一个是引用为 **"o"** 的圆圈,另一个是引用为 **"s"** 的方块。接下来,我们将为这些标记着色,为此我们将再次创建一个名为 **colors** 的变量,然后创建一个包含两个元素的向量;第一个是引用为 **"r"** 的红色,第二个是引用为 **"g"** 的绿色。 在此之后,我们将遍历所有客户,对于每个客户,我们将获得获胜节点,并根据客户是否获得批准,如果客户未获得批准,则将此获胜节点着色为红色圆圈,如果客户获得批准,则着色为绿色方块。这里我们将使用一个需要两个循环变量的 for 循环,即 **i** 和 **x**,其中 i 是我们客户数据库所有索引的不同值,这意味着它将取值 0,1,2,...689,x 将是客户的不同向量。 所以,对于 x 和 i,我们将添加 **in enumerate**,在 enumerate 内部,我们将添加 **X**,然后进入循环。在循环内部,我们将首先获取第一个客户的获胜节点,因为在此循环开始时,我们从第一个客户开始,以获取其获胜节点。为了获取获胜节点,我们将从 **w** 开始,然后我们将获取我们的对象 **som**,然后获取 **winner** 方法。接下来,我们将在 winner 方法中传递 **X**,因为它将为我们获取客户 X 的获胜节点。 获取获胜节点后,我们将在其上**绘制**彩色标记。然后在 plot 函数中,我们将指定标记的坐标,为此我们希望将标记放置在获胜节点的中心。由于每个获胜节点在自组织地图中都由一个正方形表示,正如我们之前看到的,所以我们希望将标记放置在正方形的中心。因此,获胜节点的坐标 **w[0]** 对应于 X 坐标,**w[1]** 对应于正方形左下角的 y 坐标。但是我们想将其放置在正方形的中心,所以我们将添加 **w[0] + 0.5** 以将其放置在正方形水平底部的中间,并添加 **w[1] + 0.5** 以将其放置在正方形的中心。 为了知道标记是红色圆圈还是绿色方块,我们将使用我们之前创建的 **markers** 向量,然后我们将 **y[i]** 传入向量,因为 **i** 是客户的索引,所以 y[i] 是客户因变量的值,即如果客户未获得批准则为 **0**,如果客户获得批准则为 **1**。因此,可以得出结论,如果客户未获得批准,则 **y[i]** 将等于 **0**,**markers[y[i]]** 也将如此,即一个**圆圈**。同样,如果客户获得批准,则 **y[i]** 和 **markers[y[i]]** 将等于 **1**,对应于一个**方块**。接下来,我们将以相同的方式添加颜色,通过使用我们的 colors 向量,即 colors,然后我们将使用 [y[i]],因为它包含客户是否获得批准的信息,因此根据 [y[i]] 的值,如果客户未获得批准,我们将获得红色,如果客户获得批准,我们将获得绿色。 但事实上,我们会将 colors[y[i]] 赋予标记,然而,在标记中,我们可以为标记的内部和边缘着色。这里我们将为标记的边缘着色,所以我们将把 **markeredgecolor** 设置为 **colors[y[i]]**,对于标记的内部,我们不会着色,因为同一个获胜节点可以有两个标记,因此,我们将把 **markerfacecolor** 设置为 **None**。最后,我们将添加 **markersize**,否则我们会得到太小的标记,我们希望能够看到标记,所以我们将其设置为 **10**。最终,我们也会对边缘大小做同样的处理;因此,我们将添加 **markeredgewidth**,并将其设置为 **2**。现在当我们查看我们的自组织映射时,我们会发现它实际上会更好看,因为我们不仅会看到所有获胜节点的不同神经元间平均距离,而且还会看到与获胜节点关联的客户是否获得批准,为了检查这一点,我们将添加 **show()** 来显示图表。 输出  从上图中,我们可以看到神经元间平均距离,同时我们还获得了关于每个获胜节点客户是否获得批准的信息。例如,如果我们查看红色圆圈,我们可以看到与该特定获胜节点关联的客户未获得批准。但是,如果我们查看绿色方块,我们可以看到与它关联的客户获得了批准。 现在,如果我们查看异常值,它们是神经元间平均距离几乎等于 1 的获胜节点,表明与这些获胜节点相关的客户存在高风险。基本上,在这种特殊情况下,我们看到两种情况都存在,即一些客户获得了批准,一些客户未获得批准,因为我们得到了一个绿色方块和一个红色圆圈。因此,现在我们必须在获胜节点中找出潜在的作弊者,但优先是那些获得批准的作弊者,因为对于银行来说,抓住那些逃脱惩罚的作弊者显然更重要。 现在我们已经完成了地图,它相当不错,接下来我们将使用这张地图来捕捉这些潜在的骗子。我们将使用一个字典,可以通过 **minisom.py** 中提供的方法获取,因为它包含从获胜节点到客户的所有不同映射。基本上,我们首先获取所有这些映射,然后我们将使用我们识别出的异常获胜节点(白色节点)的坐标,因为它会给我们客户列表。由于我们已经识别出两个异常获胜节点,所以我们必须使用连接函数来连接这两个客户列表,这样我们就可以得到一个完整的潜在骗子列表。 我们将从引入一个新变量 **mapping** 开始,然后使用一个方法,该方法将返回从获胜节点到客户的所有映射的字典。由于它是一个方法,所以我们需要使用我们的对象 **som**,然后我们将添加点,再添加 **win_map** 方法。在该方法内部,我们将简单地输入 X,它不是整个数据,而只是我们的 SOM 训练所用的数据。 执行上述代码后,我们将得到以下输出。 输出  正如我们之前所说,**mappings** 实际上是一个字典,如果我们点击它,我们将获得 SOM 中所有不同获胜节点的所有映射。这里键是获胜节点的坐标,如果我们谈论坐标 **(0,0)**,我们会看到有 **6** 个客户与该特定获胜节点相关联,我们实际上可以通过点击相应的值来查看列表,如下所示。  从上图中,每行对应一个与坐标 (0,0) 的获胜节点关联的客户。 在此之后,我们创建一个名为 **frauds** 的新变量,然后我们再次回到我们的地图以获取异常获胜节点的坐标,因为这些获胜节点对应于我们正在寻找的客户。所以,我们将再次执行它,然后我们将获取 **mappings** 字典。在字典的括号内,我们将输入第一个异常节点的坐标,即 **(1,1)**,因为它将为我们提供与此异常获胜节点相关联的客户列表,然后添加第二个异常获胜节点 **(4,1)** 的坐标,这对应于非常高的 MID。这里有一点非常重要需要记住,即每当我们输入两个我们希望连接到同一个参数的列表时,我们只需要将我们的两个映射放入一对新的括号中,之后我们添加另一个参数,即 **axis**,这是一个强制性参数,因为这就是您指定是否要垂直或水平连接的方式。由于我们正在连接客户的水平向量,并且我们希望将第二个客户向量列表放在第一个客户向量列表下方,所以我们将沿着垂直轴进行连接,其默认值为 **0**。 最终,我们准备好获取所有欺诈者的完整列表,所以让我们执行以下代码。  从上图可以看出,我们有了潜在作弊客户的列表。我们可以看到这些值仍然是经过缩放的,所以唯一剩下的就是进行逆缩放,为此,我们有一个逆缩放方法可以逆转这种映射。 所以,我们将再次从获取 **frauds** 列表开始,然后使用 **inverse_transform** 方法来反转缩放。由于我们使用从 MinMaxScaler 类创建的 sc 对象应用了特征缩放,所以我们将获取我们的对象 **sc**,然后使用 **inverse_transform** 方法,并在该方法中输入我们的 frauds 列表。 当我们运行上述代码时,我们将得到带有原始真实值的欺诈列表,如下所示。  从上图可以看出,我们有**客户 ID**,可以用来查找潜在的作弊者。至此,我们通过向银行提供潜在作弊者名单完成了我们的工作。此外,分析师将调查潜在作弊者名单,他可能会获取所有这些客户 ID 的 **y** 值,以便优先处理那些获得批准的客户,以重新审查申请,然后通过更深入的调查,他们将查明客户是否真的以某种方式作弊。 下一个主题大型案例研究 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
