受限玻尔兹曼机2025年3月17日 | 阅读时长54分钟 如今,受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)是一种无向图模型,在深度学习框架中发挥着重要作用。最初,它由Paul Smolensky于1986年作为Harmonium引入,后来在最近几年因Netflix大奖而广受欢迎,RBM在协同过滤中取得了最先进的性能,并击败了大多数竞争对手。  通过将受限玻尔兹曼机的未来激活作为下一个RBM的训练数据,可以有效地学习许多隐藏层。这些本质上是属于能量基模型的神经网络。它是一种用于降维、分类、回归协同过滤、特征学习和主题建模的算法。 自编码器与受限玻尔兹曼机自编码器是一种包含三层的神经网络,其中输出层连接回输入层。与可见单元相比,它的隐藏单元数量少得多。它执行训练任务以最小化重建或误差。简单来说,我们可以说训练有助于发现一种有效的方法来表示输入数据。  然而,RBM也分享了类似的思想,但它使用具有特定分布的随机单元,而不是使用确定性分布。它训练模型以理解两组变量之间的关联。 RBM有两个偏置,这是将它们与其他自编码器区分开来的最重要方面之一。隐藏偏置帮助RBM在正向传播中提供激活,而可见层偏置帮助RBM在反向传播中学习重建。 受限玻尔兹曼机中的层受限玻尔兹曼机是浅层的;它们基本上是两层神经网络,构成了深度信念网络的基本构建块。RBM中的第一层是输入层,也称为可见层,然后是第二层,即隐藏层。每个节点代表一个神经元状单元,它们在不同层之间相互连接。  但同一层的任意两个节点之间没有连接,这表明没有层内通信,这是受限玻尔兹曼机中唯一的限制。在每个节点,计算通过简单地处理输入并就其是否应该开始传输输入做出随机决策。 受限玻尔兹曼机的工作原理每个可见节点从数据库中的项目获取一个低级特征,以便可以学习它;例如,从灰度图像数据集中,每个可见节点将为一张图像中的每个像素接收一个像素值。 让我们跟踪单个像素值X通过两层网络。在隐藏层的第一个节点,X被乘以一个权重,然后加上偏置。之后,结果被提供给激活函数,以便它可以产生该节点的输出,或者当输入x已经给出时通过它的信号强度。  现在,我们将看看不同的输入如何在特定的隐藏节点处组合。基本上,每个X都被乘以一个不同的权重,然后将其乘积相加,再将其添加到偏置中。再次,结果被提供给激活函数以产生该节点的输出。  每个输入X在每个隐藏节点处被一个单独的权重w相乘。换句话说,我们可以说一个输入会遇到三个权重,这将进一步导致总共12个权重,即(4个输入节点 x 3个隐藏节点)。两层之间的权重将始终形成一个矩阵,其中行数等于输入节点数,列数等于输出节点数。  这里每个隐藏节点都将接收四个输入,这些输入将乘以单独的权重,然后再次将这些乘积添加到偏置中。然后它将结果通过激活算法,为每个隐藏节点产生一个输出。 受限玻尔兹曼机的训练受限玻尔兹曼机的训练与通过随机梯度下降训练神经网络完全不同。 以下是两个主要的训练步骤
吉布斯采样是训练的第一部分。每当我们给定一个输入向量v时,我们使用以下p(h| v)来预测隐藏值h。然而,如果我们给定隐藏值h,我们使用p(v| h)来预测新的输入值v。 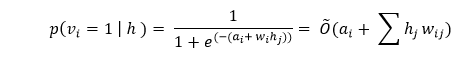 这个过程重复多次(k次),使得在每次迭代(k)之后,我们获得另一个输入向量v_k,它是从原始输入值v_0重建的。 
在对比散度步骤中,它更新权重矩阵。为了分析隐藏值h_0和h_k的激活概率,它使用向量v_0和v_k。  更新矩阵计算为概率与输入向量v_0和v_k的外积之差,由以下矩阵表示。  现在,借助这个更新权重矩阵,我们可以使用以下方程给出的梯度下降来分析新权重。  从训练到预测步骤1: 在所有用户的数据上训练网络。 步骤2: 在推理时获取特定用户的训练数据。 步骤3: 使用数据获取隐藏神经元的激活。 步骤4: 使用隐藏神经元值获取输入神经元的激活。 步骤5: 输入神经元的新值显示用户将给出的评分。 构建受限玻尔兹曼机我们将使用PyTorch来实现我们的受限玻尔兹曼机,这是一个高度先进的深度学习和人工智能平台。我们必须确保在我们的机器上安装PyTorch,为此,请遵循以下步骤。 对于Windows用户 单击左下角的Windows按钮 在Anaconda prompt中,运行以下命令。  从上图中我们可以看到,它询问是否继续。用y确认并按Enter键。  从上图中我们可以看到,我们已经成功安装了我们的库。 在此之后,我们将继续构建我们的两个推荐系统,其中一个将预测用户是否会喜欢/不喜欢一部电影(是/否),另一个将预测用户对一部电影的评分。所以,第一个将预测二元结果,1或0,即是或否,第二个预测1到5的评分。通过这种方式,我们将拥有行业中最常用的推荐系统。如今,许多公司构建了一些推荐系统,大多数时候,这些推荐系统要么预测用户或客户是否会喜欢/不喜欢产品,要么预测某些产品的评分或评论。 因此,我们将使用受限玻尔兹曼机创建一个预测二元结果是或否的推荐系统。我们将在本主题中实现的神经网络,然后我们将在下一个主题(自编码器)中实现另一个预测1到5评分的推荐系统。然而,对于这两个推荐系统,我们将使用相同的数据集,这是一个可以在线找到的真实世界数据集,即MovieLens数据集。 您可以通过点击链接下载数据集;https://grouplens.org/datasets/movielens/,这将引导您到官方网站。该数据集由grouplens研究创建,在该页面上,您将看到几个包含不同评分数量的数据集。但我们将使用带有来自1000个用户和1700部电影的另外100,000个评分的较旧数据集,如下图所示。此外,我们还有另一个包含一百万个评分的旧数据集,所以我建议您查看这些数据集并下载它们。这里我们将下载两个红色标记的数据集。 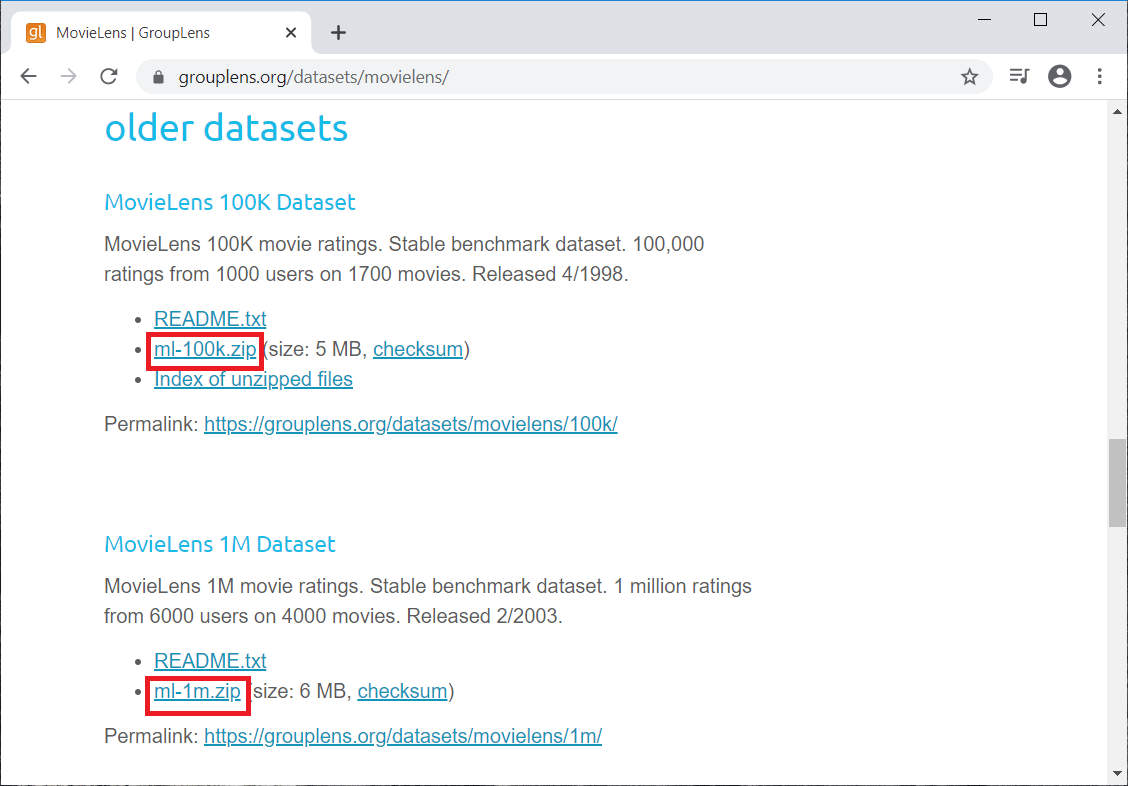 接下来,我们将导入用于导入受限玻尔兹曼机的库。由于我们将使用数组,所以我们将导入NumPy。然后是Pandas来导入数据集并创建训练集和测试集。接下来,我们有所有的Torch库;例如,nn是Torch的模块,用于实现神经网络。这里的parallel用于并行计算,optim用于优化器,utils是我们将使用的工具,autograd用于随机梯度下降。 导入所有库、类和函数后,我们现在将导入我们的数据集。我们要导入的第一个数据集是所有电影,它们在文件movies.dat中。因此,我们将创建一个新变量movies来包含我们所有的电影,然后我们将使用read_csv()函数来读取CSV文件。在函数内部,我们将传递以下参数
输出  执行上述行后,我们将获得MovieLens数据库中所有电影的列表。我们有数千部电影,对于这些电影中的每一部,我们都有第一列,即电影ID,这是最重要的信息,因为我们将使用它来构建我们的推荐系统。我们不会使用标题;实际上,使用电影ID会简单得多。 接下来,我们将以同样的方式导入用户数据集。因此,我们将创建一个新变量Users,我们只需更改路径,其余部分保持不变,因为我们实际上需要在这里对分隔符、标题、引擎以及编码使用完全相同的参数。 输出  从上图我们可以看到,我们得到了用户的所有不同信息,其中第一列是用户ID,第二列是性别,第三列是年龄,第四列是一些对应用户工作的代码,最后第五列是邮政编码。 现在我们将导入评分,我们将像以前一样再次操作,只是我们将创建一个新变量Ratings,然后更改其路径,其余部分保持不变。 输出  执行上述代码行后,我们可以看到我们已成功导入了评分变量。这里的第一列对应于用户,使得所有1都对应于同一个用户。然后第二列与电影相关,第二列中显示的数字是movies DataFrame中包含的电影ID。接下来,第三列对应于评分,范围从1到5。最后一列是时间戳,指定每个用户何时评价了电影。 接下来,我们将准备训练集和测试集,为此我们将创建一个变量training_set,然后使用Pandas库导入u1.base。然后我们将把这个训练集转换为数组,因为通过Pandas导入u1.base,我们将最终得到一个DataFrame。所以,首先,我们将使用pandas的read_csv函数,然后我们将传递我们的第一个参数,即包含ml-100k文件夹中的u1.base的路径,为了做到这一点,我们将从包含u1.base的文件夹开始,它实际上位于ml-100k文件夹中,然后添加训练集的名称,即u1.base。由于u1.base的分隔符是制表符而不是双冒号,所以我们需要指定它,否则它将默认使用逗号。因此,我们将添加我们的第二个参数,即delimiter = '\t'来指定制表符。 正如我们已经看到的,ml-100k中的整个原始数据集包含100,000个评分,并且由于每个观察对应一个评分,从下图中我们可以看到,执行上述代码行后,我们有80,000个评分。因此,训练集是包含100,000个评分的原始数据集的80%。所以,这将是80%:20%的训练集:测试集分割,这是训练模型时训练集和测试集的最佳分割。  我们可以通过简单地点击training_set变量来查看它的样子。 输出  从上图我们可以看到,它与我们之前导入的评分数据集完全相同,即第一列对应用户,第二列对应电影,第三列对应评分,第四列对应时间戳,我们实际上并不需要,因为它与训练模型无关。training_set作为DataFrame导入,我们需要将其转换为数组,因为在本主题的后面部分,我们将使用PyTorch张量,为此我们需要一个数组而不是DataFrame。 在此之后,我们将把这个训练集转换为数组,为此我们将再次使用我们的training_set变量,然后使用NumPy函数,即array将DataFrame转换为数组。在函数内部,我们将首先输入training_set参数,作为第二个参数,我们需要指定我们正在创建的这个新数组的类型。由于我们只有用户ID、电影ID和评分,它们都是整数,所以我们将把这个整个数组转换为整数数组,为此,我们将输入dtype = 'int'表示整数。 执行上述行后,我们将看到我们的training_set是integer32类型的数组,大小与下图所示相同。  我们可以通过简单地点击training_set变量来查看它的样子。 输出  从上图中可以看出,我们得到了相同的值,但这次是以数组形式。 现在,我们将以同样的方式处理测试集,我们将准备测试集,这次会非常容易,因为我们将采用相同的技术来导入并将我们的测试集转换为数组。我们将完全使用上面的代码。我们所要做的就是将training_set替换为test_set,并将u1.base替换为u1.test,因为我们现在正在获取测试集,即u1.test。 执行上述行后,我们将得到我们的test_set,我们可以看到它的结构完全相同。第一列是用户,第二列是电影,第三列是评分。从下图中,我们必须理解test_set和training_set具有不同的评分。training_set和test_set之间没有同一用户对同一电影的共同评分。然而,我们有相同的用户。这里确实,我们从用户1开始,就像在training_set中一样,但对于这个相同的用户1,我们不会有相同的电影,因为评分不同。 输出  由于我们的数据集仍然是一个DataFrame,所以我们需要将其转换为数组,为此,我们将按照训练集相同的方式进行操作。 运行上述代码行后,我们可以从下图中看到,我们的test_set是一个包含20,000个评分的integer32数组,这对应于由100,000个评分组成的原始数据集的20%。  我们可以简单地点击test_set变量来查看它的样子。 输出  从上图中可以看出,我们得到了相同的值,但这次是以数组形式。 在下一步中,我们将获取用户和电影的总数,因为在接下来的步骤中,我们将把我们的training_set和test_set转换为一个矩阵,其中行是用户,列是电影,单元格是评分。我们将为training_set和test_set各创建一个这样的矩阵。然而,除了这两个矩阵之外,我们还希望包含来自原始数据集的所有用户和所有电影。如果在我们刚刚导入的训练集中,某个用户没有评价某部电影,那么在这种情况下,我们将在对应于该用户和这些电影的矩阵单元格中放置一个0。 因此,为了获取用户总数和电影总数,我们将获取训练集和测试集中最大用户ID的最大值,以便获取用户总数和电影总数,这将进一步帮助我们构建以用户为行、电影为列的矩阵。 为此,我们将创建两个新变量,nb_users将是用户总数,nb_movies将是电影总数。正如我们所说,我们将获取训练集中最大用户ID的最大值,所以我们将借助max(max(training_set[:,0])来实现。在括号内,我们需要放置用户列的索引,即索引0,同时我们需要获取所有行,所以我们添加了:。因此,training_set[:,0]对应于training_set的第一列,即用户,由于我们正在取最大值,这意味着我们肯定正在获取用户ID列的最大值。 之后,我们需要对test_set做同样的事情,因为最大用户ID可能在测试集中,所以以同样的方式,我们将对测试集进行操作,为此,我们现在将取max(test_set[:,0])。为了强制最大值成为整数,我们必须将数字转换为整数,为此,我们使用了int函数,然后将所有这些最大值放在int函数内部,如下所示。 执行上述行后,我们将得到用户ID总数为943,但它可能不适用于其他训练/测试分割,因此我们将使用上述代码,以防我们想将其应用于其他训练集和测试集。  现在,我们将以同样的方式处理电影,我们将使用相同的代码,但将用户列的索引0替换为电影列的索引,即1。  通过执行上述行,我们得到电影ID的总数为1682。因此,我们不得不取最大值中的最大值,因为我们不知道这部电影ID是在训练集中还是测试集中,我们实际上通过运行以下命令来检查。 因此,training_set中的最大电影ID是1682。  同样地,我们可以检查test_set。 运行上述代码后,我们可以从下图中看到,test_set中的最大电影ID是1591。因此,它可能存在于test_set中,但这对于第一次训练/测试分割来说并非如此,但对于其他训练/测试分割可能会是另一种情况。  现在,我们将把我们的训练集和测试集转换成一个以用户为行、电影为列的数组,因为我们需要创建一个特定的数据结构,它将与受限玻尔兹曼机期望的输入相对应。受限玻尔兹曼机是一种神经网络,其中有一些输入节点作为特征,并且有一些观测值一个接一个地进入网络,从输入节点开始。 因此,我们将创建一个包含这些观测值(将进入网络)的结构,并且它们的各种特征将进入输入节点。基本上,我们只是为神经网络甚至一般的机器学习构建了通常的数据结构,即以观测值为行,特征为列,这正是神经网络期望的数据结构。 因此,我们将把我们的数据转换为这种结构,由于我们将对训练集和测试集都这样做,所以我们将创建一个函数,我们将分别应用于它们。为了在python中创建函数,我们将从def开始,它代表定义,然后给它一个名为convert()的名称。在函数内部,我们将只传递一个参数,即data,因为我们将这个函数只应用于一个集合,首先是训练集,然后是测试集。 接下来,我们将创建一个列表的列表,这意味着我们将创建几个列表,其中每个列表对应一行/用户。由于我们有943个用户,所以我们将相应地有943个列表,这些列表将是水平列表,它们将对应于我们刚刚描述的特殊结构中的行中的观察。第一个列表将对应第一个用户,第二个列表将对应第二个用户,依此类推。通过这样做,我们将获得对应于该列表的用户对1682部电影的评分。基本上,我们将获得每部电影的评分,如果用户没有评价这部电影,那么在这种情况下,我们将得到一个0。这就是为什么新转换的训练集和测试集将具有相同大小的原因,因为对于它们两者,我们都考虑了所有用户和所有电影,当用户没有评价电影时,我们只是将其设置为0。 因此,我们将创建名为new_data的列表列表,这将是函数返回的最终输出,即它将是以用户为行,电影为列的最终数组。 由于new_data是一个列表的列表,所以我们需要将其初始化为list。之后,我们将创建一个循环,因为我们想为每个用户创建一个列表,即用户对电影的所有评分列表,因此,我们需要一个for循环来获取每个用户的评分。 为了创建for循环,我们将引入一个局部变量,它将遍历数据中的所有用户,即训练集或测试集。所以,我们将这个变量命名为id_users,它将获取我们数据库中所有用户的ID,然后为这些用户ID指定一个范围,这个范围将是从1到最大值的所有用户ID,即我们在此步骤之前找到的用户总数。因此,id_users的范围将从1到nb_users + 1,这样当它达到944时将被排除,我们将一直到943。 现在在循环内部,我们将创建这个新数据列表的第一个列表,它是第一个用户的评分,因为这里的id_users从1开始,这就是为什么我们将从第一个用户开始,因此,我们将把第一个用户的评分列表添加到整个列表中。我们将获取第一个用户评分的所有电影ID,为了做到这一点,我们将所有电影ID放入一个名为id_movies的变量中。 然后我们将获取我们的数据,假设它是我们的training_set,因为我们将对training_set应用转换,然后从训练集中,我们将首先获取包含所有电影ID的列,即我们索引的第二列,即索引1。接下来,我们将获取所有观测值,为此我们将使用:,然后用逗号分隔冒号和一,即[:,1]。它基本上意味着我们这里只取整列,所有用户所在的整列。 由于我们只需要第一个用户的电影ID,因为我们在循环的开头,所以我们将使用某种语法来告诉我们想要数据(即训练集)的第一列,使得第一列等于1,在 Python 中,我们将添加一个新条件,将其放入一个新括号对 [] 中。在这个括号内,我们将放置条件 data[:,0] == id_users,这将获取第一个用户的所有电影 ID。 现在,我们将以同样的方式获取评分,即我们将获取该相同第一个用户的所有评分。我们不取id_movies,而是取id_ratings,因为我们想取training_set中所有评分,它在第3个索引列,即索引2处,所以我们只需将1替换为2,其余保持不变。通过这样做,我们就拥有了创建第一个列表所需的一切,即第一个用户的评分列表。 在此之后,当用户没有评价电影时,我们将得到所有的零,或者更具体地说,我们现在将创建一个包含1682个元素的列表,其中列表的元素对应于1682部电影,这样,对于每部电影,如果用户评价了电影,我们就得到电影的评分,如果用户没有评价电影,我们就得到零。 因此,我们将从初始化1682部电影的列表开始,为此我们首先将此列表命名为ratings,然后使用NumPy,它有一个快捷方式np,然后我们将使用zeros函数。在这个函数内部,我们将输入我们希望此列表中包含的零的数量,即1682,它对应于nb_movies。 在此之后,我们将用用户已评分电影的评分替换零。为此,我们将获取ratings,然后添加[id_movies - 1],因为它将为我们获取已评分电影的索引。这些索引是我们在几步之前创建的id_movies,因为它包含所有已评分电影的索引,这正是我们想要做的。由于在python中,索引从0开始,但在id_movies中,索引从1开始,我们基本上需要电影ID与ratings的索引(即0)在同一基数上开始,因此我们添加了-1。由于我们已经成功获取了在所有电影的评分列表中已评分电影的索引,因此对于这些评分,我们将通过添加id_ratings给出实际评分。通过这样做,我们成功地为每个用户创建了所有评分的列表,包括未评分电影的零。 现在,我们只剩下最后一件事要做,即,将这里对应于一个用户的评分列表添加到将包含所有不同用户的不同列表的巨大列表中。因此,我们将获取这个整个列表,即new_data,然后获取append函数,因为它将把这里对应于一个用户的评分列表(循环中的用户,id_users)附加到这个整个new_data列表中。在函数内部,我们将放入一个特定用户的所有评分列表。为了确保这是一个列表,我们将把ratings放入list函数中,因为我们正在寻找一个列表的列表,这正是PyTorch所期望的。 所以,我们的函数已经完成,现在我们将把它应用于我们的training_set和test_set。但在继续之前,我们需要添加最后一行来返回我们想要的内容,为此,我们首先添加return,然后添加new_data,这是所有不同评分列表的列表。 下一步是将此函数应用于训练集和测试集,为此;我们将使用我们的training_set,然后对其使用convert函数。在convert函数内部,我们将添加旧版本的training_set,然后它将成为新版本,即一个以用户为行,电影为列的数组。 以同样的方式,我们现在将对test_set进行操作。我们只需将training_set替换为test_set,其余部分保持不变。 通过运行上面的代码段,我们可以从下图中看到,training_set是一个包含943个列表的列表。  我们也可以通过简单地点击training_set来查看它。  从上图我们可以看到,这个巨大的列表包含943个水平列表,其中这943个列表中的每一个都对应我们数据库中的每个用户。因此,我们可以检查第一部电影、第二部电影和第三部电影;评分如预期般为0、3和4。可以清楚地看到,对于每个用户,我们都会得到数据库中所有电影的评分,如果电影未评分,则得到0,如果用户评分了电影,则得到实际评分。 同样,对于测试集,我们有新版本的test_set,它也包含一个包含943个元素的列表,如下所示。  同样,我们也可以通过简单地点击test_set来查看它。  从上图中我们可以看到,我们得到一个列表的列表,其中包含所有评分,包括未评分电影的0。 接下来,我们将把我们迄今为止的列表列表形式的training_set和test_set转换为Torch张量,使得我们的training_set将是一个Torch张量,而test_set将是另一个Torch张量。简单来说,我们可以说将有两个独立的、基于PyTorch的多维矩阵,为了做到这一点;我们将只使用torch库中的一个类,它将自行完成转换。 因此,我们将从获取我们的training_set开始,然后给它一个新值,这将是转换为torch张量的这个训练集。所以,我们将获取一个torch.FloatTensor,其中torch是库,而FloatTensor是用于创建该类对象的类。该对象将是Torch张量本身,即具有单一类型的多维矩阵,由于我们使用的是FloatTensor类,因此在这种情况下,单一类型将是float。 在类内部,我们将接受一个参数,它必须是一个列表的列表,即training_set,这就是为什么我们必须在上一节中进行这种转换为列表的列表的原因,因为FloatTensor类期望一个列表的列表。 同样,我们将对test_set进行操作。我们只需将training_set替换为test_set,其余部分保持不变。运行以下代码后,我们将看到training_set和test_set变量将在变量浏览器窗格中消失,因为Spyder尚未识别torch张量。然而,变量仍然存在,但它们不会显示在变量浏览器窗格中。 执行上述两行代码后,我们的training_set和test_set变量将消失,但它们现在已转换为Torch张量,至此,我们完成了推荐系统常用的数据预处理。 在下一步中,我们将把评分转换为二元评分,0或1,因为这些将是我们的受限玻尔兹曼机的输入。所以,我们将从training_set开始,然后我们将原始训练集中所有的0替换为-1,因为原始训练集中所有的0,所有实际上不存在的评分,这些都对应于用户未评分的电影。为了访问这些原始数据集中为0的原始评分,我们将借助[training_set == 0]来做到这一点,因为它将解释为我们希望获取training_set中所有值等于0的值。对于training_set中所有这些零值,这些零评分,我们希望将它们替换为-1。 现在我们也将对其他评分进行处理,即1到5的评分。这将以与上面相同的方式完成,同时处理我们想要转换为零的评分,即不喜欢的评分。正如我们已经讨论过的,用户不喜欢的电影是那些被评为一颗星或两颗星的电影。所以,我们也将对等于一的评分进行同样的操作,只需将0替换为1,将-1替换为0,因为在我们的新评分格式中,0对应于用户不喜欢的电影。 同样,我们也将对原始训练集中等于2的评分进行操作。现在我们将1替换为2,其余保持不变。因此,通过下面给出的这两行代码,原始训练集中等于1或2的所有评分现在将等于0。 在此之后,我们只需对用户喜欢的电影进行操作。因此,至少被评为三颗星的电影更受用户喜爱,这意味着三颗星、四颗星和五颗星将变为1。为了访问三、四和五颗星,我们需要将==替换为>=以包括3而不是2。所以,[training_set >= 3]意味着训练集中所有大于或等于三的值将获得评分1。通过这样做,三、四和五将在训练集中变为一。由于我们希望RBM以二元格式输出评分,所以输入必须具有相同的二元格式0或1,我们已成功将训练集中所有评分转换为此格式。 现在我们将对test_set做同样的事情,为此,我们将复制上面整个代码段,并简单地将所有training_set替换为test_set。这样,training_set和test_set中所有1到5的评分都将转换为二元评分。 执行完上面的代码段后,我们的输入就可以进入RBM了,这样它就可以返回输入向量中未原始评分的电影的评分,因为这是无监督的深度学习,它就是这样工作的。 现在我们将创建神经网络的架构,即受限玻尔兹曼机的架构。所以,我们将选择隐藏节点的数量,并且我们大多会像它工作的那样构建神经网络,即我们将构建这个概率图模型,因为RBM本身就是一个概率图模型,为了构建它,我们将使用类。 基本上,我们将创建三个函数;一个用于初始化我们将创建的RBM对象,第二个函数将是sample H,它将根据可见节点对隐藏节点的概率进行采样,第三个函数将是sample V,它将根据隐藏节点对可见节点的概率进行采样。 因此,我们将从定义类开始,将其命名为RBM,在类内部,我们首先将创建__init__()函数,它定义了类创建后将创建的对象的参数。它默认是一个强制函数,将定义为def __init__()。之后,我们将在函数内部输入以下参数
由于我们想初始化权重和偏置,所以我们将进入函数内部,在那里我们将初始化我们未来对象的参数,即我们将从这个类创建的对象。基本上,在__init__函数内部,我们将初始化我们在RBM训练期间将优化的所有参数,即权重和偏置。 由于这些参数特定于RBM模型,即我们将来将从RBM类创建的对象,所以我们需要指定这些变量是对象的变量。因此,要初始化这些变量,我们需要从self.W开始,其中W是权重变量的名称。这些权重是给定隐藏节点的可见节点概率的所有参数。接下来,我们将使用torch,即torch库,然后使用randn函数随机初始化张量中的所有权重,其大小应为nh和nv。 接下来,我们将初始化偏置。对于给定可见节点的隐藏节点概率存在一些偏置,对于给定隐藏节点的可见节点概率存在一些偏置。因此,我们将从给定可见节点的隐藏节点概率的偏置开始。这与我们之前所做的一样,我们将给这些偏置命名,对于第一个偏置,我们将其命名为a。但在此之前,我们将获取self对象,因为a是对象的参数。然后我们将再次获取torch.randn以根据均值为0和方差为1的正态分布初始化权重。由于每个隐藏节点只有一个偏置,并且我们有nh个隐藏节点,所以我们将创建一个nh个元素的向量。但我们需要创建一个对应于批次的附加维度,因此这个向量不应该像单个输入向量那样只有一个维度;它应该有两个维度。第一个维度对应于批次,第二个维度对应于偏置。因此,在函数内部,我们首先输入1,然后输入nh,因为它将有助于创建我们的二维张量。 然后我们有第三个要定义的参数,它仍然是特定于将创建的对象的,即可见节点的偏置,所以我们将其命名为b。这里它与上一行完全相似;我们将使用torch.randn函数,但这次是针对nv。所以我们最终初始化了一个nv个元素的张量,并带有一个对应于批次的附加维度。 接下来,我们将创建RBM类所需的第二个函数,它主要根据给定v的概率P(h)对隐藏节点进行采样,其中h是隐藏节点,v是可见节点。这个概率无非是sigmoid激活函数。 在训练期间,我们将通过吉布斯采样近似对数似然梯度,为了应用它,我们需要计算给定可见节点的隐藏节点的概率。一旦我们有了这个概率,我们就可以对隐藏节点的激活进行采样。因此,我们将从调用sample_h()开始,以返回RBM不同隐藏节点的一些样本。 在sample_h()内部,我们将传递两个参数;
现在,在函数内部,我们首先计算给定v的h的概率,即给定可见神经元值(即包含所有评分的观测值输入向量)时隐藏神经元等于1的概率。给定v的h的概率无非是应用于wx(权重向量w与可见神经元向量x的乘积)加上偏置a的sigmoid激活函数,因为a对应于隐藏节点的偏置。而b对应于可见节点的偏置,我们将用它来定义采样函数,但用于可见节点。由于我们目前正在处理隐藏节点,因此我们将使用隐藏节点的偏置,即a。 我们将首先计算权重乘以神经元,即x的乘积。因此,我们将首先将wx定义为一个变量,然后我们将使用torch,因为我们正在使用torch张量。由于我们即将进行两个张量的乘积,因此我们必须使用torch来完成该乘积,为此我们将使用mm函数。在函数内部,我们将输入我们的两个矩阵;矩阵1和矩阵2。 正如我们之前所说,我们想计算x(可见神经元)和nw(权重张量)的乘积。但是,这里的W是附加到对象的,因为它是由__init__函数初始化的对象的权重张量,所以我们不只使用W,而是使用self.W,我们将其输入到mm函数中。为了使其在数学上正确,我们将借助t()计算权重矩阵的转置。 在此之后,我们将计算sigmoid激活函数内部的内容,这无非是wx加上偏置,即神经元的线性函数,其中系数是权重,然后我们有偏置a。 我们将把wx + a称为激活,因为这将是激活函数内部的内容。然后我们将取wx加上偏置,即a,由于它附加到将由RBM类创建的对象上,所以我们需要取self.a来指定a是对象的变量。 如前所述,每个输入向量不会单独处理,而是在批次内部处理,即使批次包含一个输入向量或一个偏置向量,该输入向量仍然存在于批次中,我们将其称为mini-batch。因此,当我们添加隐藏节点的偏置时,我们希望确保该偏置应用于mini-batch的每一行,即维度的每一行。我们将使用expand_as函数,它将再次为我们正在添加的这些偏置添加一个新维度,然后将wx作为参数传递到函数内部,因为它对应于我们想要扩展偏置的内容。 接下来,我们将计算激活函数,为此我们将调用p_h_given_v函数,它对应于给定可见节点值时隐藏节点被激活的概率。正如我们已经讨论过的,p_h_given_v是激活的sigmoid,所以我们将继续使用the torch.sigmoid函数,然后将activation传递到函数内部。 在此之后,在最后一步,我们将返回概率以及h的样本,它是RBM所有隐藏节点的所有隐藏神经元的样本,根据概率p_h_given_v。因此,我们首先使用return p_h_given_v,它将返回我们想要的第一个元素,然后是torch.bernoulli(p_h_given_v),它将返回所有隐藏神经元的概率,给定可见节点的值,即评分以及隐藏神经元的采样。 因此,我们刚刚实现了sample_h函数,以根据概率p_h_given_v对隐藏节点进行采样。我们现在将对可见节点做同样的事情,因为从隐藏节点中的值,即它们是否被激活,我们还将估计可见节点的概率,即每个可见节点等于1的概率。 最后,我们将输出用户未原始评分的电影的预测评分(0或1),这些最终得到的新的评分将取自我们在隐藏节点中获得的值,即来自隐藏节点的样本。因此,我们将创建函数sample_v,因为它也是吉布斯采样所需的,我们将在近似对数似然梯度时应用它。 为了创建这个函数,它与上面的函数完全相同;我们只需替换一些东西。首先,我们将调用函数sample_v,因为我们将根据概率p_v_given_h(即给定隐藏节点的值)创建可见节点的一些样本,我们返回每个可见节点等于1的概率。 这里我们将返回p_v_given_h和可见节点的一些样本,仍然基于伯努利采样,即我们有可见节点的概率向量,并从该向量中返回可见节点的一些采样。接下来,我们将改变激活函数内部的内容,为此,我们首先将变量x替换为y,因为在sample_h函数中x表示可见节点,但这里我们正在创建sample_v函数,它将返回给定隐藏节点值的可见节点的概率,因此变量这次是隐藏节点的值,y对应于隐藏节点。 同样,我们将wx替换为wy,然后对不是x而是y的张量矩阵与所有权重的torch张量进行torch乘积。由于我们正在计算隐藏节点和权重torch张量(即W)的乘积,用于概率p_v_given_h,所以我们这里不会取转置。之后,我们将计算sigmoid函数内部隐藏神经元的激活,为此,我们不取wx,而是取wy,并且我们将a替换为b,因为我们需要取可见节点的偏置,它包含在self.b变量中,其余保持不变。 现在我们将创建最后一个函数,它是关于对比散度,我们将用它来近似对数似然梯度,因为RBM是一种基于能量的模型,即我们有一些能量函数,我们试图最小化它,并且由于这个能量函数取决于模型的权重,所有我们在开始时定义的权重张量中的权重,所以我们需要优化这些权重以最小化能量。 不仅可以将其视为基于能量的模型,还可以将其视为概率图模型,目标是最大化训练集的对数似然。为了最小化能量或最大化任何深度学习模型或机器学习模型的对数似然,我们需要计算梯度。然而,梯度的直接计算过于繁重,因此我们不直接计算它,而是尝试借助对比散度来近似梯度。 因此,我们再次开始定义名为train的新函数,然后在函数内部,我们将传递几个参数,如下所示
在此之后,我们将取我们的张量或权重self.W,由于我们必须再次取它并添加一些东西,所以我们将取+=。然后我们将计算隐藏节点等于1的概率与输入向量v0的乘积,其中给定输入向量v0的隐藏节点等于1的概率无非是ph0。 因此,为了做到这一点,我们首先将使用我们的torch库,然后使用mm进行两个张量的乘积,并在括号内,我们将输入乘积中的两个张量,即v0(观测值输入向量),然后借助t()取其转置,然后是ph0,它是乘积的第二个元素。 然后我们需要再次减去torch.mm,即可见节点(在k次采样后获得,即vk)的torch乘积,然后借助t()取其转置,以及给定这些可见节点vk的值时隐藏节点等于1的概率,这无非是phk。 接下来,我们将更新权重b,它是概率p(v|h)的偏置,为了做到这一点,我们将从获取self.b开始,然后再次+=,因为我们将向b添加一些东西,然后获取torch.sum,因为我们将对(v0 - vk)求和,它是观测值输入向量v0和k次采样后可见节点vk之间的差值,以及0。基本上,我们只是对v0-vk和0求和,这只是为了保持b的格式为二维张量。 在此之后,我们将进行最后一次更新,即偏置a,它包含P(h|v)的概率。所以,我们将从self.a开始,然后获取+=,因为我们也将添加一些东西,即我们将添加隐藏节点等于1的概率与v0(观测值输入向量)的值之差,以及隐藏节点等于1的概率与vk(k次采样后可见节点的值)的值之差。基本上,我们只添加差值(ph0-phk)和0,我们将以与上面相同的方式执行此操作。 现在我们有了类,我们可以用它来创建多个对象。所以,我们可以创建多个RBM模型。我们可以用不同的配置来测试它们,即使用多个隐藏节点,因为这是我们的主要参数。但是我们也可以向类中添加一些参数,比如学习率,以改进和调整模型。 执行上述代码段后,我们现在准备创建RBM对象,为此我们需要两个参数,nv和nh。这里nv是一个固定参数,对应于电影的数量,因为nv是可见节点的数量,并且在开始时,可见节点是一个特定用户对所有电影的评分,这是我们每部电影有一个可见节点的唯一原因。因此,我们有多种方法来获取可见节点的数量;首先,我们可以说nv等于nb_movies,即1682,或者另一种方法是确保它对应于我们特征矩阵(即训练集,特征张量)中的特征数量。 因此,我们将首先将 nv 定义为 len(training_set[0]),其中 training_set[0] 对应于训练集的第一行,而 len(training_set[0]) 是第一行中的元素数量,即我们希望 nv 具有的特征数量。 接下来,我们将对 nh 进行操作,它对应于隐藏节点的数量。由于我们有 1682 部电影,或者可以说有 1682 个可见节点,并且我们知道隐藏节点对应于 RBM 模型将检测到的一些特征,因此最初我们将从检测 100 个特征开始。 然后我们有另一个变量 batch_size,它尚未被突出显示。然而,我们已经在上面的代码部分提到了它的概念,这是因为当我们训练我们的模型算法时,我们不会在每次观察后更新权重,而是会在几次观察(它们将进入一个批次)后更新权重,因此每个批次将具有相同数量的观察。 所以,这个额外的参数,我们也可以调整它以尝试改进模型,最终是 batch_size 本身。为了实现快速训练,我们将创建一个新变量 batch_size 并将其设置为 100,但您可以尝试不同的 batch_size 以获得更好的性能结果。 现在我们将创建我们的 RBM 对象,因为我们已经有了 __init__ 方法的两个必需参数,即 nv 和 nh。为了创建我们的对象,我们将首先将我们的对象命名为 rbm,然后使用我们的类 RBM。在类内部,我们将输入 nv 和 nh 作为参数。 接下来,我们将继续训练我们的受限玻尔兹曼机,为此我们必须在 for 循环中包含我们在 RBM 类中创建的不同函数。我们将从选择一个 epoch 数量开始,为此我们将调用变量 nb_epoch,然后将其设置为 10,因为我们只有少量观测值,即 943,此外,我们只有二元值 0 和 1,因此收敛将非常快。 之后,我们将创建一个 for 循环,该循环将遍历 10 个 epoch。在每个 epoch 中,我们所有的观测值将回到网络中,然后在每个批次的观测值通过网络后更新权重,最后,我们将获得具有未被原始评分电影的新评分的最终可见节点。 为了创建 for 循环,我们将从 for 开始,然后我们将为 epoch 创建一个变量,所以我们简单地称之为 an epoch,它是循环变量 in range 的名称,然后在括号内,我们将从 (1, nb_epoch+1) 开始,这将确保我们从 1 到 10,因为即使 nb_epoch + 1 等于 11,它也不会包含上限。 然后我们将进入循环,并创建损失函数来衡量预测和真实评分之间的误差。在此训练中,我们将预测与我们已有的评分(即训练集的评分)进行比较。因此,基本上,我们将衡量预测评分(即 0 或 1)与真实评分(0 或 1)之间的差异。 对于这个 RBM 模型,我们将使用简单的绝对值差异法来衡量损失。因此,我们将引入一个损失变量,称之为 train_loss,并将其初始化为 0,因为在开始训练之前,损失为零,当我们在预测和真实评分之间发现一些错误时,损失将进一步增加。 之后,我们需要一个计数器,因为我们要对 train_loss 进行归一化,为了归一化 train_loss,我们只需将 train_loss 除以计数器 s,然后将其初始化为 0。由于我们希望它是一个浮点数,所以我们将在 0 后面添加一个点,以确保 s 具有浮点类型。这样,我们就有一个计数器,我们将在每个 epoch 后增加它。 接下来,我们将进行实际的训练,这通过我们到目前为止在上述步骤中创建的三个函数完成,即 sample_h、sample_v 和 train。当我们创建这些函数时,是针对一个用户的,当然,采样以及对比散度算法必须在批次中的所有用户上完成。 因此,我们首先获取用户批次,为了做到这一点,我们需要另一个 for 循环。这里我们将在第一个 for 循环中创建一个 for 循环,所以将从 for 开始,由于这个 for 循环是遍历所有用户,我们将引入一个循环变量 id_user in range()。正如我们已经知道的,用户的索引从 0 开始,所以我们将范围从 0 开始。 现在在我们继续之前,需要注意一个重要点,即我们希望获取一些用户批次。我们不想一个接一个地获取每个用户,然后更新权重,而是希望在每个用户批次通过网络后更新权重。因此,我们不会一个接一个地获取每个用户,而是会获取用户批次。 由于 batch_size 等于 100,所以第一个批次将包含索引 0 到 99 的所有用户,然后第二个批次将包含索引 100 到 199 的用户,第三个批次将从 200 到 299,依此类推,直到结束。因此,进入网络的最后一个批次将是索引 943 - 100 = 84 的用户批次,这意味着最后一个批次将包含从 843 到 943 的用户。因此,用户范围的停止点不是 nb_users,而是 nb_users - batch_size,即 843。之后,我们需要一个步长,因为我们不想从 1 到 1,而是希望从 1 到 100,从 100 到 200,依此类推,直到最后一个批次。因此,作为我们需要输入的第三个参数的步长将不是 1(默认步长),而是 100,即 batch_size。 现在我们将进入循环,我们的第一步是分离输入和目标,其中输入是我们在循环中处理的特定用户对所有电影的评分,而目标在开始时将与输入相同。由于输入将在吉布斯链内部并会更新以获取每个可见节点的新评分,因此输入会改变,但目标将保持不变。 因此,我们将输入称为 vk,因为它将是随机游走 k 步后吉布斯采样(Gibbs sampling)的输出。但最初,这个 vk 实际上将是所有观测值的输入批次,即批次中所有用户评分的输入批次。因此,输入将是 training_set,并且由于我们正在处理具有 ID id_user 的特定用户,所以我们想要获得的批次是所有从 id_user 到 id_user + batch_size 的用户,为了做到这一点,我们将使用 [id_user:id_user+batch_size],因为它将产生 100 个用户的批次。 同样,我们将对目标进行操作,目标是原始评分的批次,我们不想更改它,但我们希望最终将其与我们的预测评分进行比较。我们需要它,因为我们想要衡量预测评分和真实评分之间的误差以获得损失,即 train_loss。 所以,我们将目标称为 v0,它包含此批次中 100 个用户已评分的电影评分。由于目标最初与输入相同,所以我们只需复制上面的代码行,因为在开始时,输入与目标相同,它将在稍后更新。 然后我们将取 ph0,接着添加 ,_,以使其理解我们只想返回 sample_h 函数的第一个元素。由于 sample_h 是 RBM 类的方法,所以我们将借助 rbm.sample_h 从我们的 rbm 对象中使用 sample_h 函数。在函数内部,我们将输入 v0,因为它对应于开始时的可见节点,即我们批次中所有用户的电影原始评分。 在下一步中,我们将为对比散度(contrastive divergence)的 k 步添加另一个 for 循环。因此,我们将从 for 开始,然后调用循环变量,即 k in range(10)。 接下来,我们将取 _,hk,它将是对比散度第 k 步获得的隐藏节点,并且由于我们处于开始阶段,所以 k 等于 0。但是 h0 将是 sample_h 方法返回的第二个元素,并且由于 sample_h 方法在 RBM 类中,所以我们将从我们的 rbm.sample_h 中调用它。由于我们正在进行第一个隐藏节点的采样,给定第一个可见节点的值,即原始评分,所以吉布斯采样第一步中 sample_h 函数的第一个输入将是 vk,因为到目前为止 vk 是我们的观测值输入批次,然后 vk 将被更新。这里 vk 等于 v0。 现在我们将更新 vk,以便 vk 不再是 v0,而是吉布斯采样第一步之后采样的可见节点。为了获得这个样本,我们将对我们的第一个隐藏节点样本,即 hk(基于第一个可见节点,即原始可见节点进行第一次采样的结果)调用 the sample_v 函数。因此,vk 将是我们在 hk(第一个采样的隐藏节点)上调用的 rbm.sample_v。 在下一步中,我们将借助 vk 更新权重和偏差。但在继续之前,我们需要做一件重要的事情。即,我们将在训练过程中跳过评分为 -1 的销售额,方法是冻结包含 -1 评分的可见节点,因为在吉布斯采样期间无法更新它们。 为了冻结包含 -1 评分的可见节点,我们将使用 vk,这是在随机游走 k 步中更新的可见节点。然后我们将借助我们的目标 v0 获得评分为 -1 的节点,因为它没有改变,它实际上保留了原始评分。因此,我们将取 [v0<0] 来获得 -1 评分,因为我们的评分是 -1、0 或 1。对于这些可见节点,我们将通过从目标中取原始的 -1 评分来表示它们等于 -1 评分,因为它没有改变,为此,我们将取 v0[v0<0],因为它将获得所有 -1 评分。这只是为了确保训练不会在这些实际上不存在的评分上进行。我们只想对已发生的评分进行训练。 接下来,我们将在应用训练函数之前计算 phk,为此,我们将从 phk,_ 开始,因为我们想获取 sample_h 函数返回的第一个元素。然后我们将对可见节点的最后一个样本应用 sample_h 函数,即在 for 循环结束时。因此,我们首先获取我们的 rbm 对象,然后将 sample_h 函数应用于 10 步后的可见节点的最后一个样本,即 vk。 现在,我们将应用训练函数,由于它不返回任何内容,所以我们不会创建任何新变量,而是将我们的 rbm 对象作为 RBM 类中的一个函数。然后从 rbm 对象中,我们将调用我们的 train 函数,然后将 v0、vk、ph0 和 phk 作为参数传递给函数。 现在训练将顺利进行,权重和偏差将朝最大似然方向更新,因此,所有给定隐藏节点状态的概率 P(v) 将更加相关。我们将获得最重要概率的最大权重,并最终得到一些预测评分,这些评分将接近真实评分。 接下来,我们将更新 train_loss,然后我们将使用 +=,因为我们希望将误差添加到其中,误差是预测评分与目标 v0 的真实原始评分之间的差异。因此,我们将首先比较 vk(在最后一批用户通过网络后可见节点的最后一个)与 v0(从开始就没有改变的目标)。 在这里,我们将借助预测和真实评分之间绝对值的简单距离来衡量误差,为此,我们将使用 torch 函数,即 mean。在 mean 函数内部,我们将使用另一个 torch 函数,即 abs 函数,它返回一个数的绝对值。因此,我们将取目标 v0 和我们的预测 vk 的绝对值。为了改进绝对值 v0-vk,我们将包含实际存在的评分,即 [v0>=0],用于 v0 和 vk,因为它对应于存在的评分的索引。 现在我们将更新计数器以对 train_loss 进行归一化。所以,在这里我们将其浮点数增加 1。 最后,我们将打印训练过程中发生的一切,即 epoch 的数量,以查看我们在训练过程中处于哪个 epoch,然后对于这些 epoch,我们想看看损失是如何减少的。所以,我们将使用 print 函数,它包含在循环中,遍历所有 epoch,因为我们希望它在每个 epoch 都打印。 在 print 函数内部,我们将以一个字符串开始,即 epoch,即 'epoch: ',然后添加 + 来连接两个字符串,然后我们将添加通过 str 函数获得的第二个字符串,因为在这个函数内部,我们将输入我们正在训练的 epoch,即一个整数 epoch,它将在 str 函数内部变为字符串,所以我们只需添加 str(epoch)。然后我们再次添加 +,接着添加另一个字符串,即 ' loss: ',然后再次添加 + str(train_loss/s)。基本上,它将打印我们正在训练的 epoch 和相关的损失,这实际上是归一化的 train_loss。 因此,在执行上述代码部分后,我们可以从下图看到,我们最终的 train_loss 为 0.245 或近似 0.25,这非常好,因为它意味着在训练集中,我们获得了正确的预测评分,四次中有三次是正确的,四次中一次在预测所有用户对电影的评分时犯了错误。  接下来,我们将通过 test_set 结果获取新观测值的最终结果,以便查看结果是否接近 training_set 结果,即即使在新预测上,我们也能在四次中预测出三次正确的评分。测试 test_set 结果非常容易,并且与测试 training_set 结果非常相似;唯一的区别是不会有任何训练。所以,我们只需复制上述代码并进行必要的更改。 为了获取 test_set 结果,我们将用 test_set 替换 training_set。由于没有任何训练,所以我们不需要遍历 epoch 的循环,因此,我们将删除 nb_epoch = 10,然后删除第一个 for 循环。然后我们将 train_loss 替换为 test_loss 来计算损失。我们将保留初始化为零的计数器,然后在每一步将其递增一。 然后我们有一个遍历 test_set 中所有用户的 for 循环,所以我们不会包含 batch_size,因为它只是训练特有的技术。它是一个您可以调整的参数,以在 training_set 上,以及因此在 test_set 上,获得或多或少的性能结果。但是将观测值收集到 batch_size 中仅用于训练阶段。 因此,我们将删除所有与 batch_size 相关的内容,并将用户一直取到最后一个用户,因为基本上,我们将一个接一个地为每个用户进行一些预测。此外,我们将删除 0,因为那是默认的开始。所以,我们将执行 for id_user in range(nb_user),因为基本上,我们正在一个接一个地遍历所有用户。 现在对于每个用户,我们将进入循环,并再次删除 batch_size,因为我们确实不需要它们。由于我们将一个接一个地为每个用户进行预测,所以我们只需将 batch_size 替换为 1。之后,我们将 vk 替换为 v,将作为目标的 v0 替换为 vt。这里的 v 是我们将在其上进行预测的输入。对于作为输入的 v,我们不会在这里将 training_set 替换为 test_set,因为 training_set 是用于激活隐藏神经元以获取输出的输入。由于 vt 包含 test_set 的原始评分,我们将在最后用它来与我们的预测进行比较,所以我们在这里将 training_set 替换为 test_set。 现在,我们将进入下一步,我们将在其中迈出一步,以便我们的预测将直接是吉布斯采样一次往返的结果,或者我们可以说一步,一次绑定游走迭代。在这里,我们只需删除 for 循环,因为我们不必进行 10 步,我们只需进行一步。所以,为了迈出这一步,我们将从 if 条件开始,以过滤 test_set 中不存在的评分,然后使用 len 函数。在函数内部,我们将输入 vt[vt>=0],它与所有存在的评分相关,即 0 或 1。所以,如果 len,即包含设置评分的可见节点的数量(vt[vt>=0])大于 0,那么我们就可以进行一些预测。 由于我们只需要进行一步盲走(即吉布斯采样),因为我们没有 10 步的循环,所以我们将删除所有的 k。 接下来,我们将用 test_loss 替换 train_loss 以便更新它。然后,我们将再次更新 torch 库中的 mean 函数,并且我们仍然会取预测和目标之间的绝对距离。所以,这次,我们的目标将不再是 v0,而是 vt,然后取 test_set 中所有存在的评分,即 [vt>=0]。此外,预测将不再是 vk,而是 v,因为只有一步,然后我们将再次取相同的存在评分 [vt>=0],因为它将帮助我们获取具有存在评分的单元格的索引。 现在,我们将更新 counter 以便对 test_loss 进行归一化。 最后,我们将打印最终的 test_loss,为此我们将从代码中删除所有 epoch。然后从第一个字符串中,我们将用 test_loss 替换 loss 以指定它是测试损失。接下来,我们将用 test_loss 替换 train_loss,并将其除以 s 进行归一化。 输出  因此,在执行上述代码行后,我们可以从上图中看到,我们得到了 0.25 的 test_loss,这非常好,因为这是针对新的观测值、新电影。我们成功地在四次中预测了三次正确的评分。我们实际上成功地建立了一个强大的推荐系统,这是一个更容易的系统,用于预测二元评分。 下一主题# |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India

 -> 程序列表 -> Anaconda -> Anaconda prompt。
-> 程序列表 -> Anaconda -> Anaconda prompt。