Keras 模型2025年3月17日 | 阅读 12 分钟 Keras 提供了两种内置模型:Sequential 模型和带有函数式 API 的高级模型类。Sequential 模型往往是最简单的模型之一,因为它构成了一个线性层集合,而函数式 API 模型可以创建任意网络结构。 Keras Sequential 模型Sequential 模型中的层按顺序排列,因此被称为 Sequential API。在大多数人工神经网络中,层按顺序排列,层之间的数据流以指定的顺序流动,直到到达输出层。 开始使用 Keras Sequential 模型可以通过将层实例列表传递给构造函数来简单地创建 sequential 模型 .add() 方法用于添加层 指定输入形状由于模型必须知道它期望的输入大小,因此 sequential 模型中的第一层需要指定其输入形状,以便其他层可以自动推测形状。这可以通过以下方式完成
以下代码片段是严格等效的 编译首先编译模型,为此,使用 compile 过程来构建学习过程,然后模型在下一步进行训练。编译包括三个参数,如下所示
训练输入数据或标签的 Numpy 数组被合并用于训练 Keras 模型,因此它使用 fit 函数。 示例:在 MNIST 数据集上训练一个简单的深度学习神经网络 用于序列分类的堆叠 LSTM为了使模型能够学习高级时间表示,3 个 LSTM 层相互堆叠。 这些层以这样的方式堆叠,即前两层产生完整的输出序列,第三层在其输出序列中产生最终阶段,这有助于成功地将输入序列转换为单个向量(即,时间维度下降)。 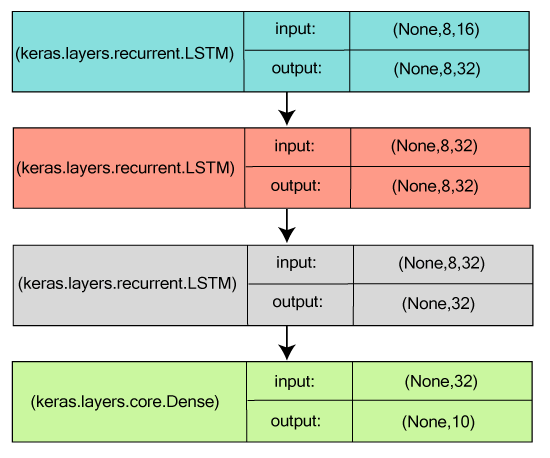 相同的堆叠 LSTM 模型,渲染为“有状态”一个模型,它的中心(内部)状态被再次用作另一个批次样本的初始状态,这些状态是在处理一批样本后获得的,被称为“有状态循环模型”。它不仅管理了计算复杂度,而且允许处理更长的序列。 Keras 函数式 APIKeras 函数式 API 用于描绘复杂的模型,例如,多输出模型、有向无环模型或带有共享层的图。换句话说,可以说函数式 API 允许您概述那些共享层的输入或输出。 第一个例子:一个密集连接的网络要实现一个密集连接的网络,Sequential 模型的结果更好,但如果我们尝试使用另一个模型,这也不是一个坏主意。 Keras 函数式 API 的实现与 Keras Sequential 模型类似。
所有模型都是可调用的,就像层一样由于我们正在讨论函数式 API 模型,我们可以简单地通过将任何此类模型视为一个层来重用经过训练的模型。这可以通过在一个张量上调用一个模型来完成。 当我们在一个张量上调用一个模型时,应该注意的是,我们不仅重用了它的架构,而且还重用了它的权重。 上面给出的代码允许一个实例构建一个用于处理输入序列的模型。此外,借助单独的一行代码,我们可以将图像分类模型转换为视频分类模型。 多输入和多输出模型由于函数式 API 很好地解释了多输入和多输出模型,因此它可以通过操作来处理大量相互交织的数据流。让我们看一个下面给出的例子,以更简洁地了解它的概念。基本上,我们将预测社交媒体(如 Twitter)上的新闻标题将获得多少转发和喜欢。 标题(这是一个单词序列)和一个辅助输入将被提供给接受数据的模型,例如,标题发布的时间或日期等。这两个损失函数也被用于监督模型,这样,如果我们首先使用主损失函数,这将是正则化深度学习模型的最佳选择。  这里的 main_input 获取标题作为一个整数序列,其中每个整数将编码每个单词。整数的范围从 1 到 10,000,序列由 100 个单词组成。 然后将插入辅助损失,这将允许 LSTM 和 Embedding 层平稳地训练自身,即使模型中的主损失较高也是如此。 接下来我们将 aux_input 输入到我们的模型中,这是通过将其与 LSTM 输出连接起来完成的。 此后,我们将通过在辅助损失上分配 0.2 的权重来编译我们的模型。然后我们将使用列表或目录来识别所有不同输出的 loss 或 loss_weight。要在每个输出上使用相同的损失,将传递一个单一的损失参数(loss)。 接下来我们将通过传递输入数组和目标数组的列表来训练我们的模型。 由于我们已经命名了输入和输出,因此该模型将按如下方式编译; 该模型可以通过以下方式进行推断; 或者, 共享层要考虑的另一个例子是为了理解函数式 API 模型,将会是共享层。为此,我们将检查推特的数据库。由于我们愿意组成这样一个模型,它可以确定两个推文是否属于同一个人,这将使一个实例可以根据推文的相似性轻松地比较用户。 我们将构建一个模型,该模型将通过将两个推文编码为向量,然后将它们连接起来,然后我们将包括逻辑回归。该模型将输出两个推文属于同一个人的概率。接下来,我们将用成对的正面和负面推文来训练我们的模型。 由于这里我们选择的问题是对称的,我们的机制必须重用第一个编码的推文,以便对另一个推文进行编码,为此我们将使用一个共享的 LSTM 层。 要使用函数式 API 构建此模型,我们将输入一个形状为 (280,256) 的推文二进制矩阵。这里 280 是大小为 256 的向量序列,使得每个 256 维向量将编码一个字符的存在与否。 接下来我们将输入一个层,然后根据需要将其调用在各种输入上,以便我们可以在多个输入上共享一个层。 现在为了理解如何读取共享层的输出或输出形状,我们将简要地看一下 层“节点”的概念。 在调用任何输入上的层时,我们实际上是通过将一个节点附加到层并将输入张量链接到输出张量来生成新的张量。如果同一个层被调用多次,那么该层将拥有很多节点,这些节点将被索引为 0,1,2,.. 为了获得层实例的张量输出,我们在旧版本的 Keras 中使用了 layer.get_output(),而对于其输出形状,我们使用了 layer.output_shape。但现在 get_output() 已经被输出替换。 只要一个层连接到一个输入,该层就会返回该层的一个输出。 如果该层包含多个输入; 输出 >> AttributeError: Layer lstm_1 has multiple inbound nodes, hence the notion of "layer output" is ill-defined. Use `get_output_at(node_index)` instead. 现在以下内容将执行它; 因此,字符(例如 input_shape 和 output_shape)也一样。如果一个层包含单独的层或所有节点都具有相似的输入/输出,只有这样我们才能说“层输入/输出形状”的概念被完全定义,并且该形状将被 layer.output_shape/ layer.input_shape 返回。 如果我们对形状为 (32, 32, 3) 的输入应用 conv2D 层,然后对 (64, 64, 3) 应用 conv2D 层,那么该层将包含几种输入/输出形状。为了获取它们,我们将需要指定它们所属节点的索引。 下一个主题Keras 层 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
