大型案例研究2025年3月17日 | 阅读13分钟 在这个大型案例研究中,我们将构建一个混合深度学习模型。正如其名,这个挑战涉及结合两种深度学习模型,即人工神经网络和自组织图。 因此,我们将从信用卡申请数据集开始,以识别欺诈行为。我们的目标是构建一个先进的深度学习模型,在该模型中,我们可以预测每个客户欺诈的概率,并且为了做到这一点;我们将从无监督学习过渡到监督学习。 该挑战包含两个部分,即在第一部分中,我们将构建混合深度学习模型的无监督深度学习分支,然后在第二部分中,我们将构建监督深度学习分支,最终得到一个由无监督和监督深度学习组成的混合深度学习模型。 这里我们再次使用我们在自组织图中刚刚看到的**Credit_Card_Applications**数据集,其中包含银行不同客户的所有信用卡申请,因此我们将像之前的主题一样使用自组织图来识别欺诈。但是,挑战在于使用这个自组织图的结果来将我们的无监督深度学习模型与一个新的监督深度学习模型相结合,该模型将接收我们 SOM 提供的结果作为输入。挑战是获得每个客户欺诈概率的预测排名。 我们会得到非常小的概率,因为 SOM 只识别了少数欺诈,但这没关系。主要目标是获得这些概率的排名。 构建混合深度学习模型我们将从第一部分开始,其中包括构建混合深度学习模型的无监督深度学习分支,即**自组织图**,我们将像之前一样用它来识别欺诈。 第一部分:使用自组织图识别欺诈因此,我们将运行以下代码来获取包含离群神经元的自组织图。 输出  从上图可以看出,我们得到了一个离群神经元,因为它具有大的 MID(平均神经元间距离),并且此外,它包含了两类客户;已批准申请的客户和未批准申请的客户。 因此,我们获得了两种场景的欺诈情况,并且选择离群神经元是任意的,因为它取决于我们想要用来选择这些神经元的阈值,即我们是想要最白的神经元,还是可以稍微降低阈值。因此,我们将选择最白的神经元,而所有其他神经元都是常规神经元或通用神经元,它们遵循一般规则,并且看起来不是潜在的欺诈。 现在,我们获得了两个神经元的坐标,如上图所示,即第一个坐标是(7,2),第二个坐标是(8,3)。所以,我们准备好查找欺诈列表,潜在的欺诈,我们将通过执行以下代码来完成。 执行上述代码后,我们将转到变量浏览器,然后单击**fraud**变量,在那里我们将看到我们得到了 17 个欺诈。 输出  欺诈  接下来,我们将使用欺诈列表从无监督深度学习过渡到监督深度学习,因为在切换时,我们需要一个因变量,而无监督深度学习之所以没有考虑任何因变量,是因为它们是在不使用任何因变量的情况下在特征上进行训练的。但在进行监督学习时,我们需要一个因变量,因为我们需要模型来理解特征与结果/输出之间的一些相关性,而结果/输出就在因变量中。 第二部分:从无监督到监督深度学习在第二部分中,我们将首先创建特征矩阵,这是我们需要训练我们的监督学习模型所需的第一个输入,然后我们将创建因变量。 为了创建特征矩阵,我们可以采用与前一部分相同的方式从数据集中提取矩阵,为此,我们将用**customers**替换 X,因为这个特征矩阵包含了银行所有客户的信息,其中每一行都对应一个客户及其所有不同的信息。因此,我们称之为 customers,然后我们将因变量称为**is_fraud**,如果**是**,则为欺诈,则**is_fraud**等于**1**;如果**否**,则为无欺诈,则**is_fraud**等于 0。我们获取除最后一列(即申请是否被批准的**class**)之外的所有列,并且我们包含了**customer ID**以跟踪客户。 但是,由于我们只需要包含可能有助于预测欺诈概率的某些信息的特征矩阵,因此**customer ID**无助于我们预测欺诈概率。因此,我们将不包含该列,但是数据库的最后一列可能是有助于我们识别客户信息与其欺诈概率之间相关性的相关信息。因此,我们从未知道我们会包含这个自变量。 要创建特征矩阵,我们需要索引为 1 的所有变量,所以我们不包括索引 0 的第一个变量到最后一个变量。因此,**customers**将是我们数据集的所有列,索引从 1 到最后一列,并且这里用**-1**;我们不包括最后一列,所以我们会将其删除。这里我们包含除第一列之外的所有列,然后,当然,我们取所有行,因为我们想获取所有客户,然后是**.values**来创建 NumPy 数组。 通过执行上述代码行,我们得到了我们的特征矩阵,如下所示。 输出 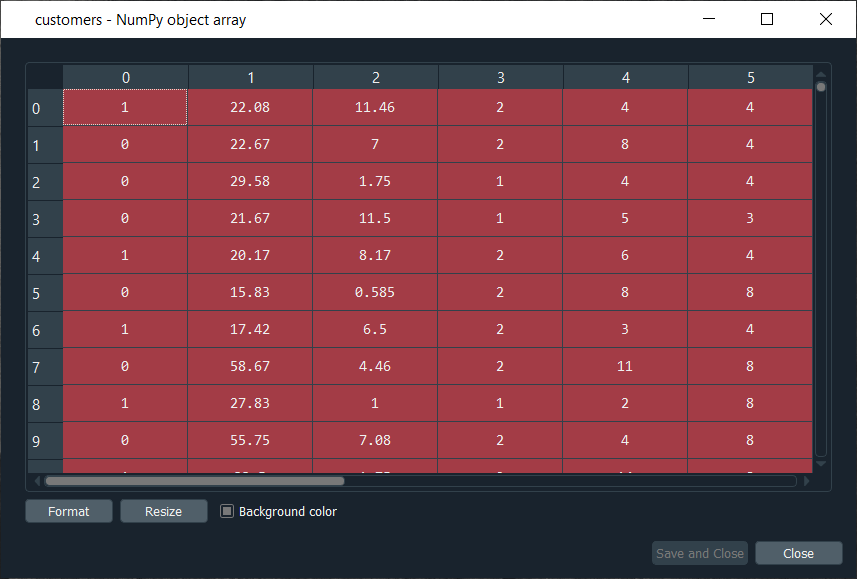 从上图可以看出,它包含了 690 名客户及其所有特征,即他们填写信用卡申请所需的所有不同信息。 接下来,我们将创建因变量,这是这里的关键部分。由于因变量将包含结果,即是否为欺诈,因此它将是一个二元结果的欺诈,如果不存在欺诈,则值为 0,如果存在欺诈,则值为 1。 因此,我们将初始化一个包含 690 个零的向量,这基本上就像我们起初假设所有客户都没有欺诈,然后我们将提取客户 ID,对于这些客户 ID,我们将在零向量中放入 1。我们将用 1 替换 0,对应于客户 ID 的索引。 让我们开始初始化向量,正如我们所说,我们将其称为**is_fraud**,它将是我们的因变量。然后,我们将使用 NumPy 函数初始化此向量,为此,我们将首先调用其快捷方式**np**来获取此函数,即**zeros**,它将创建任何数量元素的 0 向量。由于我们想要 690 个元素,为了使其更通用,我们将把**len(dataset)**放在函数中,因为它指的是数据集中观察的数量,在本例中为 690。 执行上述代码行后,我们可以看到我们的向量已初始化为 690 个零,如下图所示。 输出  下一个挑战是为所有可能欺诈的客户 ID 放置 1。因此,我们将遍历所有客户,以便对于每个客户,我们将检查该客户的客户 ID 是否属于欺诈列表,如果是这种情况,我们将用 1 替换 0。因此,我们将创建一个**for**循环,然后我们需要一个变量,我们称之为**i**,然后我们需要一个范围,该范围必须是客户索引的范围,所以我们将写**in range**。由于默认开始是零,所以我们需要指定停止点,这又是**len(dataset)**,即 690,然后在最后添加**:**。 正如我们刚才所说,对于每个客户,我们需要检查其客户 ID 是否在欺诈列表中,所以我们将通过创建一个**if**条件来做到这一点。我们将从检查客户的客户 ID 开始,所以我们需要提取客户的客户 ID,它包含在**dataset.iloc[i,0]**中,其中**i**代表数据集中第 i 行,并且正如我们之前所知,每个客户对应一行,所以第 i 行对应第 i 个客户,即我们刚才讨论的那个客户,循环,然后是**0**,因为正如我们之前所说,第一列包含客户 ID。因此,dataset.iloc[i,0]将获取客户 i 的客户 ID,然后我们不需要.value,因为它有助于创建 NumPy 数组。在此之后,我们将检查此客户 ID 是否在欺诈列表中,为此,我们将添加**in frauds**,它将检查客户 ID 是否在欺诈列表中。但是,如果发生这种情况,我们将为该特定客户将 0 替换为 1。 因此,对于该客户,is_fraud 中的值将为 1 而不是 0,并且 is_fraud 在该客户中的值由**is_fraud[i] = 1**给出,因为该客户的索引为 i。 执行上述代码后,我们将看到我们的因变量现在是一个包含 690 个元素的向量,当我们打开它时,我们将看到我们的因变量在欺诈列表中的客户索引处为 1,如下面的图片所示。由于我们的欺诈列表中有 17 个元素,因此我们将看到 17 个 1,您可以通过向下滚动来查看。 输出 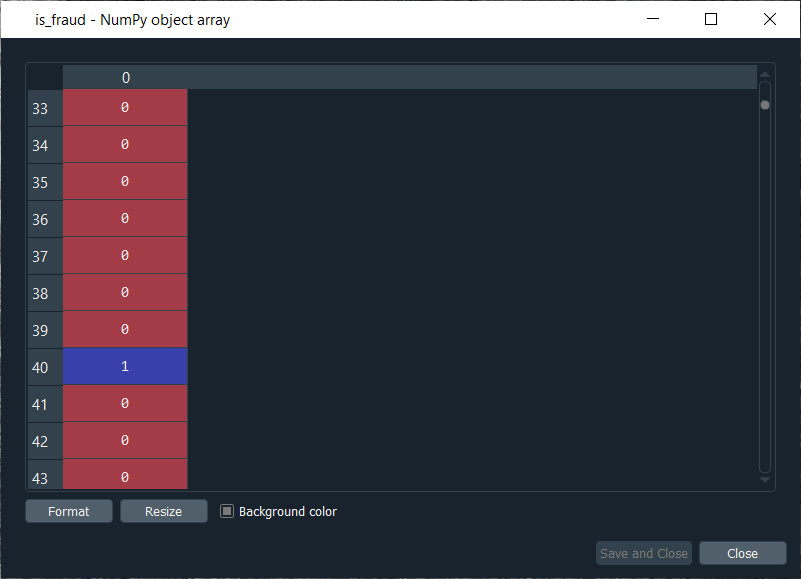 现在我们有了训练**人工神经网络**的所有条件,我们将以与之前相同的方式运行以下代码。基本上,我们只是执行 ANN 架构中的特征缩放部分,然后通过 fit 方法进行训练,然后进行预测,预测概率。 运行上述部分后,我们可以从下图看出,我们的客户已成功缩放,因此我们可以继续进行后续部分。 输出  接下来,我们将构建**人工神经网络**架构并使用 ANN 拟合我们的训练集。有一件重要的事情要注意,我们正在处理一个非常简单的数据集,其中包含 690 个观测值,这对于我们的**深度学习**模型来说太小了,但这里的想法不是处理大数据或处理非常复杂的数据集,而是学习如何结合两种深度学习模型。 我们简化了代码,因为我们不需要添加第二个隐藏层的复杂性,所以我们跳过了那部分,然后输入层我们采用了 2 个神经元而不是 6 个,然后更改输入维度,因为它们对应于我们特征矩阵中的特征数量。由于我们的特征矩阵中有 15 个特征,因此我们将**input_dim**设置为**15**而不是 11。 此外,我们还需要更改输入、输出、batch_size 以及 epochs。输入是我们不再称为 X_train 的特征矩阵,而是**customers**。然后我们需要更改输出,它不再称为 y_train,而是**is_fraud**。为了简单起见,我们设置了**batch_size**为**1**,**epochs**为**2**,因为数据集非常简单,只需要 1 到 2 个 epoch 就能让我们的神经网络理解相关性。权重只需要更新 1 到 2 次,这就是为什么我们采用 2 个 epoch。如果您有很少的观测值和很少的特征,则不需要为深度学习模型训练 100 个 epoch。 现在我们准备好了我们的人工神经网络,我们将使用 customers 这个特征矩阵和 is_fraud 这个因变量来训练它。运行上述代码后,我们可以从下面的输出图中看到,我们的准确率提高了,即**97.54%**,损失从**45.28%**大幅降低到**14.64%**。 输出  在训练了人工神经网络之后,我们将继续下一部分,在其中我们将预测欺诈的概率。我们将把这些预测概率**y_pred**,当然,我们将使用我们的**classifier**,然后使用**predict**方法,而不是像我们在 ANN 中那样在 X_test 上,而是在**customers**上,因为我们想为每个客户预测该客户欺诈的概率,或者其申请中存在欺诈的概率。通过执行上述一行代码,我们将得到预测概率。 执行上述一行代码后,我们可以查看下面的**y_pred**。 输出  从上图可以看出,y_pred 包含了所有不同的概率。它有很小的概率,但这是正常的,因为因变量向量只包含很少的 1,即总共 690 个观测值中只有 17 个。 所以,这就是所有的概率,现在我们必须对它们进行排序,为此,我们有两种选择;我们可以将 y_pred 向量导出到 Excel 中直接对概率进行排序,因为在这种情况下,我们不需要进一步遵循;或者,为了学习更多 Python 技巧来理解它如何对 Python 中的数组进行排序,那么我们必须遵循下面给出的步骤。 但是,在对概率进行排序之前,最好将客户 ID 包含在 y_pred 向量中,因为目前我们只有预测概率。如果我们能够创建一个包含两列的数组,第一列包含客户 ID,第二列包含预测概率,那么我们将能够清楚地识别出每个客户的预测概率的客户,这将是很好的。 让我们开始添加第二列到 y_pred,它实际上将位于第一列,所以我们将再次使用我们的**y_pred**向量,并且由于我们想将包含客户 ID 的第一列添加到 y_pred,因此我们将使用与上一步相同的连接技巧。但我们会做一些修改;我们将首先摆脱映射,然后我们将添加我们想要在 2D 数组中拥有的第一列,这当然是客户 ID,即**dataset.iloc[:, 0:1].values**,然后添加**y_pred**,最后,我们将添加**axis=1**,因为我们想进行水平连接,这就是为什么我们选择**1**而不是 0。 现在当我们执行上述一行代码时,我们将在下面的图片中看到,它给了我们一个包含两列的 2D 数组,即第一列是客户 ID,第二列是预测概率。 输出  从上图可以看出,y_pred 现在是一个 2D 数组,包含两列,正如我们所预期的。第一列包含所有客户 ID,第二列包含预测概率,并且我们对客户 ID 和预测概率之间有正确的关联。 接下来,我们将借助 NumPy 的 sort 函数按客户欺诈的预测概率对客户进行排序,该函数将同时对所有列进行排序,但我们不会这样做,因为我们想跟踪预测概率的客户 ID。 所以,我们将使用一个技巧,它将很快只对我们的第二列进行排序。我们将再次取**y_pred**,因为我们想修改它,然后取**y_pred[y_pred[:, 1]**,因为它指定了我们要排序的列,即包含预测概率的第二列。最后,我们将使用 NumPy 数组方法,即**argsort()**,来按索引 1 的列对我们的 NumPy 数组进行排序,这正是我们想要的。 输出  因此,我们可以从上图看出,所有概率都已从最低排序到最高。因此,我们得到了排名,现在好多了,因为欺诈部门可以利用这个排名,并从最高的预测欺诈概率开始调查欺诈。 下一个主题受限玻尔兹曼机 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
