使用 Hugging Face / Transformers 运行 DeepSeek2025年4月23日 | 阅读9分钟 如今,大多数用户在本地实现 DeepSeek 时,会使用 Ollama 等工具进行快速简便的部署。虽然这些工具集都非常用户友好且操作速度快,但它们通常会带来各种限制,其中之一就是**缺乏微调模型的灵活性**。  在本教程中,我们将介绍如何使用**Hugging Face 的 transformers**,在**中端游戏笔记本电脑**上轻松地将 **DeepSeek 本地实现**,该笔记本电脑拥有**20GB 的 GPU 内存**。由于消费级 GPU 的内存限制,我们通常会使用**8 位量化**。 我们还将介绍**不同级别的交互**(在本地 LLM 的帮助下)、**量化技术**及其在内存优化方面的重要性,然后深入探讨**微调**的过程。我们还将使用 **Hugging Face** 来加载 DeepSeek 模型并在本地进行交互。 量化及其对内存优化的重要性俗话说,PC 上的 GPT 比手机上的“**更聪明**”。这是因为我们使用了**量化技术**。  此外,当我们在较小的 硬件 上运行大量语言模型时,我们遇到的最大挑战之一是将所有数据装入有限的 **GPU 内存**。 “**量化是主要降低模型权重的技术,以便使其在内存方面更有效。**”此外,通过将权重从**32 位**转换为**8 位整数**,用户现在可以有效地减小模型的尺寸和处理器的速度,从而使其能够在功耗较低的设备上运行。 现在,让我们将量化视为**丢弃小数**。这就像手机变成了一个**便携计算器**,但仍然可以得到准确的答案,只是忽略了一些细节。大量的模型也会缩小,因此它们完全能够装入较小的设备,并且当我们需要的计算能力更多时,优化后的模型可以有效地利用云。 针对这一限制,我们将对 **DeepSeek 模型**应用 8 位量化,使其能够在配备**20GB GPU** 存储的消费级笔记本电脑上流畅运行。这种方法使我们无需高端硬件即可与大量模型进行交互,我们还可以使用此技术优化类似设置下的其他模型。 如何轻松地与 DeepSeek 和本地 LLM 进行交互?众所周知,通过利用六种有效的技术,可以轻松地与 DeepSeek 和本地 LLM 进行交互,并且通常有不同级别的本地 LLM 交互,例如 DeepSeek、Llama、Mistral 等。 
不同的技能集及其用例我们大多数人现在将在前三个级别与本地 LLM 进行交互。尽管如此,其余级别更适合特定的专家或 LLM 提供商的内部人员。例如,为了应对各种 GPU 限制,**DeepSeek 团队**深入到 CUDA(Nvidia 的 软件)之下,深入到 **PTX 层**,以从旧的 GPU 芯片中榨取更多性能,从而在不失败的情况下满足所需的成果。 从 HuggingFace 下载并加载模型。 要有效地下载模型,我们必须访问 **https://hugging-face.cn/deepseek-ai/DeepSeek-R1** 这个 **URL**,在那里我们可以找到我们想要下载的特定模型。  在本节中,我们决定选择最小的选项:**精简模型**,仅包含**15 亿个参数**。精简模型通常体积更小,并且被认为是复杂 AI 模型的快速版本,可以有效地保留关键信息。 因此,为了有效地从 **HuggingFace** 下载模型,我们必须安装 **PyTorch**(由 Meta 开发)和 **Transformers**(由 Hugging Face 开发)。一旦安装了软件,我们就可以设置我们的“**项目目录**”和“**虚拟环境**”,并运行以下代码集: 代码 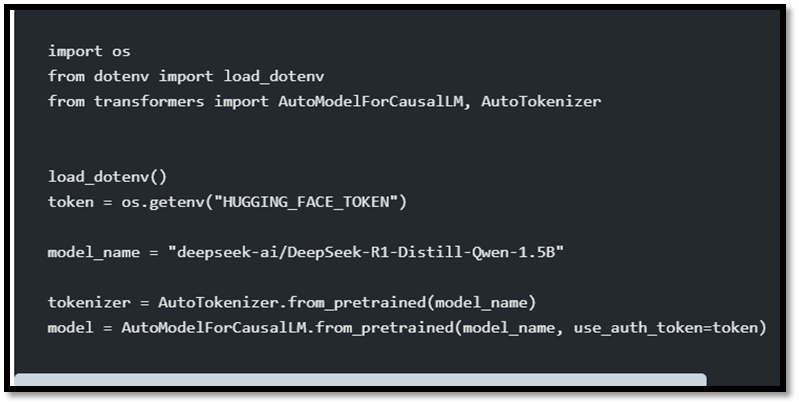 尽管如此,在 **.env 文件**中保存 **hugging face API 密钥**和模型名称都很重要。 加载模型非常简单 代码 通过编写上述代码集,它将自动加载与模型名称相关的预训练**因果语言模型**。如果是第一次,它会**下载**并**加载**模型。但是,它不像我们安装 Python 包那样进行安装。**模型在首次下载后会在本地缓存,以便后续更快地使用。**只要我们不清除缓存,我们就无需导入它。 依赖关系 代码 这负责加载具有 8 位量化配置的模型和分词器,以优化内存使用和推理性能。 该函数将根据环境变量动态加载模型和分词器。 它还将配置模型以进行 8 位量化,这将减少内存占用并加快推理速度,同时还可以通过“llm_int8_threshold”灵活地控制量化模型的程度。 量化主要通过使用 `BitsAndBytesConfig` 来完成 - `load_in_8bit=True` 确保模型权重以 8 位精度 (INT8) 加载, 从而减少模型的内存需求。 - `llm_int8_threshold=6.0` 指定了应用 8 位量化的阈值。 幅度大于此阈值的权重将被量化为 8 位精度, 而较小的权重可能会保留在更高的精度中以保持准确性。 模型加载方式还可以使其自动在 CPU 和 GPU 资源之间进行平衡。 返回值 元组:分词器和模型对象。 """ 此外,相应的函数从 Hugging Face 加载 DS 模型及其对应的分词器,然后将其配置为优化的 8 位量化,以提高内存和推理性能。 **模型名称**使用 dotenv 库从**.env 文件**加载(.env 文件私密保存 API 密钥、其他凭证、模型名称等)。 代码 开源 LLM 的分词器比 Anthropic 或 OpenAI 等云 LLM 的分词器稍微复杂一些。
尽管如此,如果需要,我们也可以使用自己的自定义分词器,但 Hugging Face AutoTokenizer 使加载变得容易。 量化配置模型主要通过集体使用 BitsAndBytesConfig 进行 8 位量化配置:load_in_8bit=True,这确保了模型权重以 8 位精度 (INT8) 加载。这将减少模型的内存占用,但会加快推理速度。
考虑的值在**1.0 到 10.0** 的范围内,但对于某些特定模型或用例,它也可能被设置为更低或更高的值。例如:
加载模型 模型通过 AutoModelForCausalLM.from_pretrained (model_name, ...) 加载。AutoModelForCausalLM 是 Transformers 中用于加载开源**LLM**模型的首选类。大多数 Python 用户仅使用此项。 device_map **device_map="auto"** 选项通常确保模型根据可用性动态地跨 CPU 和 GPU 资源加载,从而优化计算效率(即,将 90% 的负载放在 GPU 上)。然后将量化配置 (quantization_config) 传递给模型以应用指定的 8 位量化。 一旦模型和分词器加载完成,该函数将返回一个元组(分词器,模型)。然后,这些可以在各种后续代码中使用以生成响应或有效地进行模型微调。 生成响应 此特定函数通常是查询 LLM 和生成响应的核心代码。Hugging Face 的 model.generate 比 chat.completions(我们可以轻松使用 OpenAI 中的各种 LLM API 调用)或 message.create(在 Anthropic 中)要手动得多。 Code Example     关键参数和参数使用的各种关键参数和参数如下:
|
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
