数据仓库架构2025 年 2 月 12 日 | 阅读 9 分钟 引言我们将了解数据仓库架构,但在此之前,我们必须了解数据仓库。数据仓库是一个补充数据库,专门为查询和调查而设计。数据仓库是一个来自不同来源的异构数据集合,不侧重于事务处理。IBM研究员Barry Devlin和Paul Murphy于20世纪80年代末提出了“业务数据仓库”的概念。为了协助报告和分析,数据仓库被用于维护组织的历史信息。根据数据仓储之父Bill Inmon的说法,“数据仓库架构”一词描述了一种专门的、统一的、随时间变化的、非易失性的数据收集,用于决策。从定义中,我们可以了解到数据仓库架构的特性。 它到底是什么?数据仓库架构是定义企业内部终端用户计算所存在的数据通信处理和呈现的总体架构的一种方法。每个数据仓库都是不同的,但它们都具有标准的关键组件。 像薪资、应付账款、产品采购和库存控制这样的生产应用程序是为在线事务处理(OLTP)设计的。这类应用程序收集日常运营的详细数据。 数据仓库应用程序旨在支持用户临时数据需求,这是一项最近被称为在线分析处理(OLAP)的活动。这些包括预测、剖析、汇总报告和趋势分析等应用程序。 生产数据库由人工或通过OLTP应用程序持续更新。相比之下,仓库数据库则定期从操作系统中更新,通常在非工作时间进行。当OLTP数据积累到生产数据库中时,它会被定期提取、过滤,然后加载到专用的仓库服务器中,该服务器可供用户访问。当仓库被填充时,它必须被重构,表被反规范化,数据被清理掉错误和冗余,并添加新的字段和键以反映用户对数据排序、组合和汇总的需求。 数据仓库及其架构因组织情况的要素而异。 三种常见的架构是
设计数据仓库架构的方法要构建数据仓库架构,我们有两种流行的方法。它们是—— 1.自顶向下方法Bill提出的自顶向下方法被认为是一种数据驱动的技术,因为在这种情况下,信息首先被收集和集成。之后,识别出特定主题的商业需求。然后开始创建数据超市的过程。 使用自顶向下方法的优点
2.自底向上方法自底向上方法由Kimball提出。在这里,我们选择来自不同来源的各种数据,并且这些数据必须经过验证、重新格式化、清理并存储在数据超市中,而不是特定主题的数据仓库中。 使用自底向上方法的优点
数据仓库架构的特点
使用数据仓库架构的好处
数据仓库架构:基础 操作系统 操作系统是数据仓库中用于处理组织日常交易的系统。 平面文件 平面文件系统是一种文件系统,用于存储事务数据,并且系统中的每个文件都必须有不同的名称。 元数据 一组定义和提供其他数据信息的集合。 数据仓库中使用元数据,用于多种目的,包括 元数据总结了关于数据的必要信息,这使得查找和使用特定数据实例更加容易。例如,作者、数据构建、数据更改和文件大小是文档非常基础的元数据示例。 元数据用于将查询定向到最合适的数据源。 轻度和高度汇总数据 数据仓库的该区域保存了仓库管理器生成的所有预定义的轻度和高度汇总(聚合)数据。 汇总信息的目的是加快查询性能。汇总记录会随着新信息加载到仓库中而不断更新。 终端用户访问工具 数据仓库的主要目的是为业务经理提供战略决策所需的信息。这些客户使用终端用户访问工具与仓库进行交互。 一些终端用户访问工具的例子可以是
数据仓库架构:带暂存区在将操作信息放入仓库之前,我们必须对其进行清理和处理。 W我们可以以编程方式完成此操作,尽管数据仓库使用暂存区(数据在进入仓库之前进行处理的地方)。 暂存区简化了来自多个源系统的操作方法的数据清理和整合,特别是对于整合了企业所有相关数据的企业数据仓库。 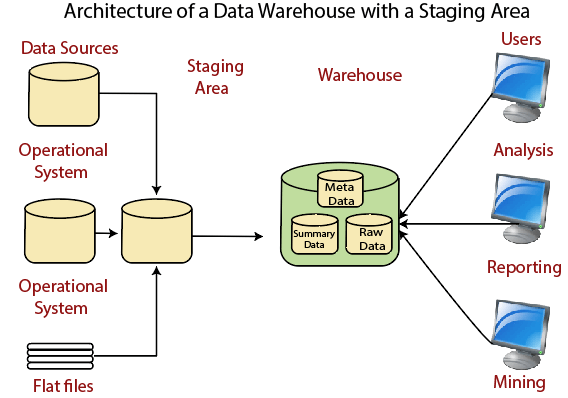 数据仓库暂存区是一个临时位置,源系统中的记录会复制到该位置。  数据仓库架构:带暂存区和数据超市我们可能希望为组织内的多个组自定义仓库的架构。 我们可以通过添加数据超市来做到这一点。数据超市是数据仓库的一个片段,它可以为公司的一个部门、单元、部门或业务(例如,销售、薪资、生产等)提供用于报告和分析的信息。 该图说明了一个示例,其中采购、销售和库存被分开。在此示例中,财务分析师希望分析采购和销售的历史数据,或挖掘历史信息以预测客户行为。  数据仓库架构的属性数据仓库系统需要以下架构属性  1.分离:分析和事务处理应尽可能分开。 2.可扩展性:硬件和软件架构应易于升级,以应对需要管理和处理的数据量的增加,以及需要满足的用户数量的逐步增加。 3.可扩展性:架构应能够执行新的操作和技术,而无需重新设计整个系统。 4.安全性:由于数据仓库中存储了战略数据,因此监控访问是必要的。 5.可管理性:数据仓库管理不应复杂。 数据仓库架构的类型 单层架构单层架构在实践中并不常用。其目的是尽量减少存储的数据量,为了达到这个目标,它消除了数据冗余。 该图显示了唯一物理存在的层是源层。在这种方法中,数据仓库是虚拟的。这意味着数据仓库是通过特定的中间件实现的,或者是一个中间处理层,作为操作数据的多维视图。  该架构的脆弱性在于它未能满足分析和事务处理之间分离的要求。分析查询在中间件解释它们后被应用到操作数据上。这样,查询就会影响事务工作负载。 双层架构如上图所示,分离的要求在定义数据仓库系统的双层架构中起着至关重要的作用。  虽然它通常被称为双层架构,以突出物理可用源和数据仓库之间的分离,但实际上它包含四个连续的数据流阶段。
三层架构三层架构由源层(包含多个源系统)、协调层和数据仓库层(包含数据仓库和数据超市)组成。协调层位于源数据和数据仓库之间。 协调层的主要优势在于它为整个企业创建了一个标准参考数据模型。同时,它将源数据提取和集成的问题与数据仓库填充问题分离开来。在某些情况下,协调层也直接用于更好地完成一些操作任务,例如生成公司应用程序无法令人满意地准备的每日报告,或定期生成数据流以供外部进程使用,以从清理和集成中获益。 这种架构对于广泛的企业级系统特别有用。这种结构的一个缺点是由于额外的冗余协调层而导致的文件存储空间额外增加。它也使得分析工具离实时操作更远了一点。  数据仓库架构选择题1.以下哪一项不是数据仓库架构?
答案:d 解释:因为数据仓库没有四层架构。 2. OLAP不包括哪个应用程序?
答案:c。 解释:数据复制不包含在线分析处理。 3. 谁拥有“数据仓储之父”的称号?
答案:a。 解释:Bill Inmon被称为上述称号。 4. 构建数据仓库的自底向上方法是由哪位科学家提出的?
答案:b。 解释:Ralph Kimball提出了数据仓库中的自底向上方法。 5. 数据仓库的属性不包括?
答案:d。 解释:面向主题的属性、非易失性属性、时变性属性是主要属性。 下一主题三层数据仓库架构 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
