MySQL INSERT ON DUPLICATE KEY UPDATE2025年3月17日 | 阅读 3 分钟 INSERT ON DUPLICATE KEY UPDATE 语句是 MySQL 中 INSERT 语句的扩展。当我们在一 SQL 语句中指定 ON DUPLICATE KEY UPDATE 子句,并且某一行会导致 UNIQUE 或 PRIMARY KEY 索引列中的重复错误值时,就会发生现有行的更新。 换句话说,当我们向表中插入新值,并且该值会导致 UNIQUE 或 PRIMARY KEY 列中出现重复行时,我们会收到错误消息。但是,如果我们使用 ON DUPLICATE KEY UPDATE 子句在 SQL 语句中,它将用新行的值更新旧行,无论该行是否具有唯一键或主键列。 例如,如果列 col1 被定义为 UNIQUE 且在表 tab1 中包含值 10,那么执行以下两个语句后,我们将获得类似的效果。 它确保如果插入的行与表中的多个唯一索引匹配,则 ON DUPLICATE KEY 语句只更新第一个匹配的唯一索引。因此,不建议在包含多个唯一索引的表上使用此语句。 如果表包含 AUTO_INCREMENT 主键列,并且 ON DUPLICATE KEY 语句尝试插入或更新行,则 Last_Insert_ID() 函数将返回其 AUTO_INCREMENT 值。 以下是 MySQL 中 Insert on Duplicate Key Update 语句的语法 在此语法中,我们可以看到 INSERT 语句仅在找到重复行时添加 ON DUPLICATE KEY UPDATE 子句,并进行列-值对赋值。ON DUPLICATE KEY UPDATE 子句的工作原理是首先尝试将新值插入到行中,如果发生错误,它将用新行的值更新现有行。 VALUES() 函数仅在此子句中使用,并且在任何其他上下文中都没有意义。它从 INSERT 部分返回列值,对于多行插入特别有用。 MySQL 根据给定的操作,为 ON DUPLICATE KEY UPDATE 语句返回受影响的行数。
MySQL INSERT ON DUPLICATE KEY 示例让我们通过一个例子来理解 MySQL 中 INSERT ON DUPLICATE KEY UPDATE 子句的工作原理。 首先,使用以下语句创建一个名为 "Student" 的表。 接下来,插入数据到表中。执行以下语句。 执行 SELECT 语句以验证插入操作。 我们将得到如下输出,其中表中有三行。  再次,向表中添加一行,使用以下查询。 上述语句将成功添加一行,因为它不包含任何重复值。  最后,我们将添加一行,该行在 Stud_ID 列中具有重复值。 MySQL 在成功执行上述查询后会给出以下消息。 在下面的输出中,我们可以看到 id=4 的行已经存在。因此,查询仅将 City New York 更新为 California。 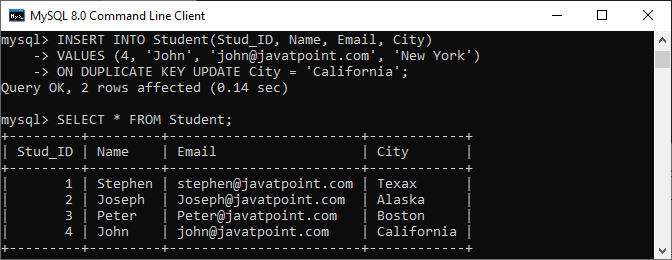 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
