MySQL 正则表达式2025年3月17日 | 阅读 7 分钟 正则表达式是一种特殊的字符串,用于描述搜索模式。它是一种强大、简洁且灵活的工具,可以根据模式识别文本字符串,例如字符和单词。它使用自己的语法,可以由正则表达式处理器进行解释。正则表达式广泛应用于几乎所有平台,从编程语言到数据库,包括 MySQL。 正则表达式使用反斜杠作为**转义字符**,如果使用了双反斜杠,则在模式匹配时应考虑它。正则表达式不区分大小写。**在 MySQL 中,它缩写为 REGEX 或 REGEXP**。 使用正则表达式的优点是,我们不再局限于使用 LIKE 运算符中的百分号 (%) 和下划线 (_) 来基于固定模式搜索字符串。正则表达式拥有更多的元字符,可以在执行模式匹配时提供更大的灵活性和控制力。 我们**之前已经学习过通配符**,它们可以实现与正则表达式类似的结果。那么,**为什么我们要学习正则表达式**,如果我们可以获得与通配符相同的结果呢?这是因为正则表达式允许我们以比通配符更复杂的方式搜索匹配的数据。 语法MySQL 采用了**Henry Spencer** 实现的正则表达式。**MySQL** 允许我们使用 REGEXP 运算符在 SQL 语句中直接匹配模式。以下是说明 MySQL 中正则表达式用法的基本语法: 在此语法中,**column_list** 指示结果集中返回的列名。**table_name** 是使用模式检索数据的表的名称。**WHERE** **field_name** 表示执行正则表达式的列名。REGEXP 是正则表达式运算符,而 **pattern** 是 REGEXP 要匹配的搜索条件。我们也可以使用 **RLIKE** 运算符,它是 REGEXP 的同义词,具有与 REGEXP 相同的结果。通过使用 REGEXP 而不是 LIKE,我们可以避免在此语句与 LIKE 运算符混淆。 如果 WHERE field_name 中的值与 pattern 匹配,此语句将返回 **true**。否则,它返回 **false**。如果 field_name 或 pattern 为 **NULL**,则结果始终为 NULL。REGEXP 运算符的否定形式是 NOT REGEXP。 正则表达式元字符下表显示了正则表达式中最常用的元字符和构造:
让我们通过下面的实际示例来理解正则表达式。 假设我们有一个名为 **student_info** 的表,其中包含以下数据。我们将基于此表数据演示各种示例。  如果我们想**搜索姓名以“A 或 B”开头的学生**,我们可以结合使用正则表达式和元字符,如下所示: 执行该语句,我们将获得所需的结果。请参见下面的输出:  如果我们想**获取姓名以 k 结尾的学生信息**,我们可以使用 'k$' 元字符来匹配字符串的结尾,如下所示: 执行该语句,我们将获得所需的结果。请参见下面的输出:  如果我们想**获取姓名恰好包含六个字符的学生信息**,我们可以使用 **'^'** 和 **'$ 元字符**来实现。这些字符匹配学生姓名的**开头**和**结尾**,并在中间的任何字符 **'.**' 上重复 {6} 次,如下面的语句所示: 执行该语句,我们将获得所需的结果。请参见下面的输出:  如果我们想**获取科目包含“i”字符的学生信息**,我们可以通过使用下面的查询来实现: 执行该语句,我们将获得所需的结果。请参见下面的输出:  正则表达式函数和运算符以下是 MySQL 中常用的正则表达式函数和运算符列表:
让我们详细了解所有这些。 REGEXP、RLIKE 和 REGEXP_LIKE()尽管这些函数和运算符返回相同的结果,但**REGEXP_LIKE()** 提供了更多带有可选参数的功能。我们可以如下使用它们: 这些语句返回字符串表达式是否匹配正则表达式模式。如果表达式匹配模式,则返回 1。否则,返回 0。下面的示例更清楚地解释了这一点。 在下面的图像中,第一个语句返回 '1',因为 **'B'** 在 A-Z 范围内。第二个语句将模式的范围限制在 B-Z。因此 **'A'** 不会匹配范围内的任何字符,MySQL 返回 0。这里我们使用了别名 **match_ 和 not_match_**,以便返回的列更易于理解。  REGEXP_LIKE() 参数以下是用于修改函数输出的**五个可选参数**:
示例 在此示例中,我们添加了 **'c' 和 'i'** 作为可选参数,它们分别调用**区分大小写**和**不区分大小写**的匹配。第一个查询返回 0,因为 'a' 在 'a-z' 范围内,但不在大写字母 A-Z 的范围内。第二个查询由于不区分大小写的特性返回 1。 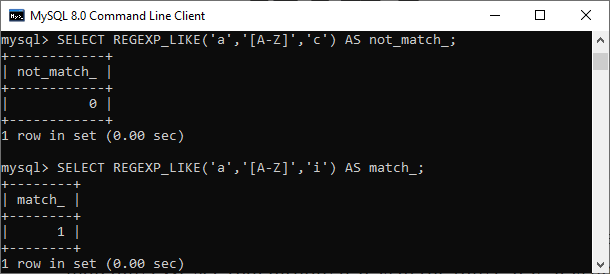 NOT REGEXP 和 NOT RLIKE它们是正则表达式运算符,用于比较指定的模式并返回不匹配模式的结果。如果未找到匹配项,这些运算符返回 1。否则,它们返回 0。我们可以如下使用这些函数: 示例 下面的语句返回 0,因为在给定范围内找到了 **'a'**。 这是输出  REGEXP_INSTR()这是一个函数,当子字符串表达式的起始索引与模式匹配时返回结果。如果没有找到匹配项,则返回 0。如果表达式或模式为 **NULL**,则返回 NULL。此处索引从 1 开始。 此函数使用各种可选参数,例如 pos、occurrence、return_option、match_type 等。 示例 假设我们要获取子字符串 'a' 在 expr (a b c d e f a) 中的索引位置。第一个查询返回 1,因为我们没有设置任何可选参数,它是字符串的第一个索引。第二个查询返回 13,因为我们已使用可选参数 occurrence 修改了查询。  REGEXP_REPLACE()此函数通过匹配字符来替换指定的字符串字符,然后返回结果字符串。如果找不到任何表达式、模式或可替换字符串,则返回 NULL。此函数可如下使用: 替换字符使用可选参数,如 pos、occurrence 和 match_type。 示例 此语句将 'tutorials' 模式替换为 'javat' 模式。. 这是输出  REGEXP_SUBSTRING()此函数返回表达式中与指定模式匹配的子字符串。如果表达式或指定的模式甚至未找到匹配项,则返回 NULL。此函数可如下使用: 模式使用可选参数,如 pos、occurrence 和 match_type。 示例 此语句返回 'point' 模式,这是给定范围的第三次出现。. 这是输出  下一主题MySQL RLIKE |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
