使用 Kafka 在 Cosmos DB 中处理大规模优化数据2025年5月16日 | 阅读 7 分钟 引言Apache Kafka 是一个分布式事件流平台,专为高吞吐量、容错性和实时处理而设计。它充当事件驱动型架构的中间件,能够实现事件生成者(事件生成器)和事件使用者(事件处理器)之间的数据无缝移动。另一方面,Azure Cosmos DB 是一种全球分布式 NoSQL 数据库服务,以其可伸缩性、低延迟性能和多模型能力而闻名。 通过将 Kafka 与 Cosmos DB 集成,组织可以建立一个高度可伸缩的实时数据处理管道,该管道能够高效地摄取、处理和持久化事件数据。 大规模事件处理的重要性处理大规模事件数据对于各个行业都至关重要,包括
处理这些工作负载需要一个能够
Kafka 和 Cosmos DB 共同为这些需求提供了坚实的基础。 为什么将 Kafka 与 Cosmos DB 结合使用?Kafka 和 Cosmos DB 通过提供实时事件处理和可伸缩存储来相互补充。它们的集成提供了多项优势 1. 可伸缩性和弹性
2. 高可用性和可靠性
3. 实时处理和分析
4. 成本优化
5. 多模型和灵活的模式支持
架构概述Kafka 和 Cosmos DB 的集成涉及多个组件协同工作,以创建可伸缩且高效的数据管道。高层架构包括
流程图 示例 Kafka 生产者代码 输出  示例 Kafka 消费者代码 输出  在 Cosmos DB 中存储事件 输出  为大规模事件处理设置 Kafka概述为大规模事件处理设置 Kafka 包括安装 Kafka、配置代理、设置主题和优化性能。本节将介绍
步骤 1:安装和启动 Kafka下载并解压 Kafka 启动 Zookeeper 启动 Kafka 代理 步骤 2:为高吞吐量配置 Kafka修改 config/server.properties 以优化性能 步骤 3:创建 Kafka 主题创建一个针对高吞吐量进行优化的主题 验证主题创建 输出  步骤 4:运行 Kafka 生产者和消费者Kafka 生产者(Python) 输出  Kafka 消费者 输出  步骤 5:为大规模数据处理进行性能调优为高吞吐量配置 Cosmos DB设置 Azure Cosmos DB 帐户使用 Azure CLI 创建 Cosmos DB 帐户 输出  配置吞吐量设置启用自动缩放吞吐量 手动设置预配吞吐量 输出  创建数据库和容器创建数据库 创建带分区键的容器 输出 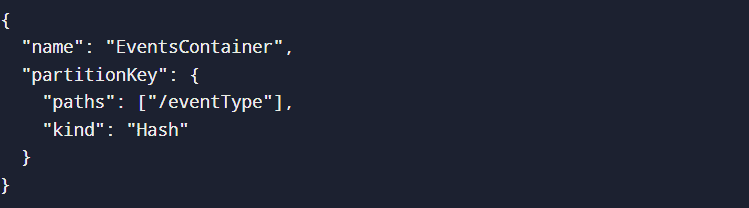 将数据写入 Cosmos DBPython 代码插入数据 输出  优化 Cosmos DB 以实现大规模摄取启用索引策略以加快查询速度 启用 TTL(生存时间)以实现自动数据过期 输出  开发用于大规模事件的 Kafka 生产者编写高性能 Kafka 生产者Kafka 生产者负责将数据发送到主题。它连接到代理并实时推送消息。 基本 Kafka 生产者 输出  此示例创建一个简单的生产者,它连接到 Kafka 并发送 JSON 格式的事件。 配置生产者优化为了有效处理大规模事件数据,必须配置诸如批处理、压缩和重试等优化。 优化的 Kafka Producer 配置 优化说明
高效发送大量事件 输出  批处理消息通过减少发送到 Kafka 的请求数量来提高性能。 监控和错误处理Kafka 生产者必须处理诸如代理故障、网络问题或超时等错误。 处理消息发送失败 输出(成功和失败的消息传递示例)  关键错误处理策略
构建 Kafka 消费者以在 Cosmos DB 中存储事件编写高效的 Kafka 消费者Kafka 消费者监听一个主题并读取消息进行处理。 Python 中的基本 Kafka 消费者 输出  将消费者连接到 Cosmos DB设置 Cosmos DB 连接 将 Kafka 事件存储到 Cosmos DB 输出  高效处理大规模事件数据 批处理以实现高吞吐量 输出  监控和错误处理处理消息处理失败 输出(示例错误处理)  为大规模数据处理优化性能
|
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
