Python中的冒泡排序2025年8月5日 | 阅读 6 分钟 在 Python 中,冒泡排序是一种排序算法,它通过迭代检查相邻的元素并根据需要进行交换来对元素列表进行排序。然而,对于大量数据,此算法效率不高。在本文中,我们将讨论冒泡排序,并展示其在 Python 中的实现。 冒泡排序如何工作?冒泡排序通过重复地比较元素与相邻的元素,并在元素不在正确位置时进行交换,从而开始排序。首先比较前两个元素,并在需要时交换。然后,我们移至下一个元素对,直到数组末尾。这构成了一趟。这个过程会重复多趟,直到给定的数组完全排序。 这是冒泡排序算法的工作原理 考虑输入数组 [5, 3, 2, 4] 步骤 1:找出第一个最大的元素 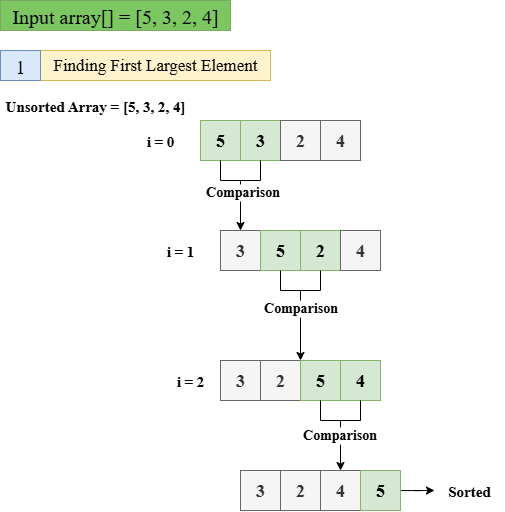 步骤 2:找出第二个最大的元素 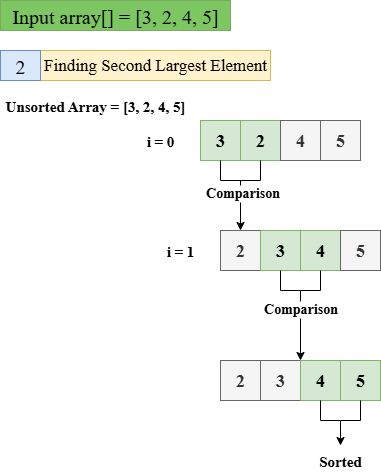 步骤 3:找出第三个最大的元素,它已在正确的位置 在此趟中,未排序的数组为:[2, 3, 4, 5] i = 0:[2, 3, 4, 5],比较 2 和 3,2 较小,因此不进行交换,数组已排序。  冒泡排序的伪代码冒泡排序的伪代码会检查相邻的元素,并在它们不在正确顺序时进行交换。此过程将一直重复,直到整个列表排序完成。 Python 中的冒泡排序实现让我们看一个用于实现冒泡排序对给定数组进行排序的 Python 代码示例。 示例输出 [3, 9, 12, 21, 45, 56, 78] 说明 在上面的代码中,`sort_number` 函数接受一个列表 `data` 作为参数,并就地对 `data` 中的元素进行排序。函数内的嵌套循环用于比较相邻元素,并在它们不在正确位置时执行交换操作。外层循环确保过程一直迭代,直到 `data` 的所有元素都被排序。 冒泡排序的时间复杂度了解任何算法的时间复杂度都很重要,因为它显示了算法的效率,尤其对于大数据。冒泡排序的时间复杂度在所有情况下均为 O(n²),其中 n 表示列表的长度。
优化 Python 中的冒泡排序由于与其他排序算法相比,冒泡排序对于大型数据来说不是理想选择,因此有几种方法可以改进冒泡排序算法。冒泡排序算法可以通过标记冒泡排序、使用递归和鸡尾酒排序来进行优化。这里有详细的讨论 标记冒泡排序在这种优化方法中,我们设置一个标志变量来跟踪每趟的交换情况。如果没有发生交换,则列表已排序,可以退出算法。以下代码演示了标记冒泡排序 示例输出 [1, 2, 4, 5, 8] 说明 在上面的代码中,`flagged_bubble_sort` 函数使用 `swapped` 标志来停止循环,如果数组已排序。它连续比较并交换所有元素,如果它们顺序不正确。每趟之后,最大的未排序元素会移到其正确的位置。如果在某趟中没有发生交换,则循环会中断。 递归冒泡排序这是冒泡排序算法的递归版本,它将列表分为两部分:列表的第一个元素和列表的其余未排序元素。然后递归地对列表的其余部分进行排序,直到整个数组被排序。这是演示冒泡排序递归版本的 Python 代码。 示例输出 [1, 2, 4, 5, 8] 说明 递归冒泡排序算法接受一个数组作为输入,并将“n”设置为 None。如果将 n 设置为 None,我们首先找到 n 的值,即数组的长度。基本情况是 n = 1,表示数组的长度为 1,这已经排序并返回。我们执行第一趟的交换或排序,然后使用递归语句处理其余的趟。 此算法优化方法在最佳情况下的时间复杂度为 O(n),在平均和最坏情况下的 时间复杂度 为 O(n²),因为每趟需要 O(n) 时间来比较相邻元素并交换元素,然后进行 n 次递归调用,这些调用执行 O(n) 次比较,使得时间复杂度为 O(n²)。 鸡尾酒排序它是冒泡排序的一个变体,也称为双向冒泡排序,是冒泡排序的改进版本,它以两个方向对给定列表的元素进行排序,从而减少所需的趟数并提高算法的性能。请参阅下面的鸡尾酒排序示例。 示例输出 [1, 2, 4, 5, 8] 说明 在提供的代码中,定义了 `cocktail_shaker_sort` 函数,该函数在每趟中沿两个方向对数组进行排序。它通过将较大的元素移到末尾,将较小的元素移到开头来对数组进行排序。它会持续进行,直到不需要交换为止,表明数组已排序。 冒泡排序与其他排序算法的比较排序算法很重要,并且已经引入了各种优化算法来有效地组织数据。为了理解它们之间的差异和性能,让我们来看看冒泡排序与其他算法的比较。
下一主题Python 中的插入排序 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
