Awk 命令用法2025年3月17日 | 阅读 12 分钟 Awk 是一种通用脚本语言,专为高级数据处理和报表生成而设计。Awk 脚本语言被广泛用作报告和分析工具包。与各种过程式编程语言不同,awk 是数据驱动的。这意味着用户可以定义一组操作,对输入文本执行任务。 Awk 命令不需要编译,并允许用户使用变量、字符串函数、数字函数和逻辑运算。它接收数据作为输入,相应地执行操作,并将结果作为标准输出返回。 Awk 是一种实用程序,它使程序员能够编写小巧而令人印象深刻的程序,这些程序是以定义文本模式的语句的形式存在的。定义的文本模式应该能够在文档的每一行中搜索,当在一行中找到匹配项时,将应用一个操作。 Awk 命令广泛用于模式扫描和处理。它搜索系统中的一个或多个文件,并检查它们是否包含指定的模式。如果文件中的指定模式匹配,它将执行相应的操作。 它的名字是如何变成 awk 的?这种脚本语言的名字是根据 1977 年编写其初始版本的三个人的姓氏字母命名的。这三个人是Alfred Aho、Peter Weinberger 和 Brian Kernighan。这三个人来自 AT&T Bell Laboratories 的 Unix 部门。在 1977 年的初始 awk 版本之后,自那时以来还有许多其他贡献,awk 不断发展。 Awk 是一种完整的脚本语言,也是一个完整的文本处理工具包,允许从命令行操作文本文件。 使用 awk 命令我们可以执行什么操作?使用 awk 命令,我们可以执行以下活动 1. Awk 操作
2. 适用于
3. 编程结构
Awk 的规则、模式和操作编写 awk 命令有一些规则、模式和操作。每个 awk 命令都包含模式和操作。操作在与输入模式匹配的文本上执行,该模式用花括号 ({}) 括起来。当模式和操作一起出现在 awk 命令中时,称为一条规则。每个 awk 程序都写在单个单引号 (') 内。 当一条规则不包含任何模式时,整个记录(行)都被视为匹配。我们甚至可以在操作中输入多个语句,它们之间用分号 (;) 或换行符分隔。如果规则中没有操作,默认情况下,它会打印整个记录。 常用的 awk 语句。awk 命令中有不同类型的语句,包括输入、条件、表达式、输出语句等。然而,最常用的 awk 语句是
注释 (#): 井号 (#) 之后的任何句子或程序,直到结束,都被视为注释。注释仅用于用户理解该行或作为提示,它在 awk 命令执行中不起任何作用。 反斜杠 (\): 使用反斜杠 (\) 键,我们可以将任何长行分解为多行。 让我们看一个简单的 awk 命令来打印字符串 只需在控制台中键入以下 awk 命令然后按 Enter 键。  在上面的命令中,print 语句只是将给定的字符串“Welcome to awk command”打印到屏幕上。双引号 (") 括起来的语句表示一个字符串值,它会原样打印到屏幕上。 Awk 特殊字段标识符特殊字段标识符返回指定标识符位置的可用值。一些特殊字段标识符代表行中的特定字段和数据位置。
考虑一个 'txt' 文件 "awk_file.txt",其中包含以下语句:“Awk 是一种通用脚本语言,专为高级数据处理和报表生成而设计。” 现在,使用 awk 特殊字段标识符,我们将检索相应的值。 输入文本文件在命令屏幕上在处理和读取文件数据之前,我们必须将此文件输入到命令屏幕。首先,我们将文本文件 "awk_file.txt" 输入到我们的命令中以从中检索值。要输入文件,请使用命令 as  在上面的命令中,/home/jtp1234 是包含文本文件 "awk_file.txt" 的目录结构。现在,要使用 awk 特殊字段标识符和 print 语句从文本文件中读取和打印值,请使用以下命令 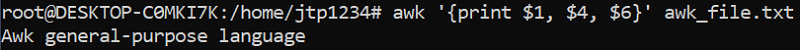 上面的命令 print 语句将打印 "awk_file.txt" 文件中第 1st ($1)、第 4th ($4) 和第 6th ($6) 位置的数据。如果你想打印文件中最后一个(结束)位置的数据,请使用标识符 $NF。查看下面的命令,它打印文件中最后一个位置的数据  Awk 的特殊模式 BEGIN 和 END 规则。Awk 包含两个特殊的模式,称为 BEGIN 和 END。BEGIN 规则在执行任何命令操作之前执行一次。它在 awk 读取任何文本文件之前运行。END 规则在对记录执行完所有操作后执行。我们可以在命令中使用多个 BEGIN 和 END 规则,并且它们都将按定义的顺序执行。 例如:让我们打印文本文件 "awk_file.txt" 开头的“Process Starting”字符串和结尾的“Process End”。  如果一个 awk 脚本程序只包含一个 BEGIN 模式,它会执行一个动作,并且输入不会继续。  如果一个 awk 程序只包含一个 END 模式,它只会继续输入,然后执行规则操作。  Awk 内置变量Awk 有几个内置变量,它们包含有关文件的信息并允许我们控制程序执行。以下是一些最常用的内置 awk 变量
让我们看一个打印当前正在使用的文件名及其总行数的示例  Awk 内置函数Awk 包含几个内置函数,我们可以在我们的程序中使用和调用它们。我们可以从命令行 shell 和脚本程序调用这些内置函数。下面是一些常用的内置 awk 函数
看看在命令行 shell 中调用 awk 函数的基本方法。在示例中,我们将使用一些数字函数。 Awk 数字函数以下是所有与数字一起工作的内置数字函数的列表。额外的参数通过方括号([])传递。
Awk 数字函数示例 使用 int() 函数打印整数  使用 sqrt() 函数计算 100 的平方根  使用 sin() 函数打印正弦值  使用 cos() 函数打印余弦值  使用 exp() 函数打印指数值  使用 log() 函数打印对数值;如果输入值为负数,则会发出警告并显示 nan。  使用 atan2() 函数打印反正切值。函数 atan2() 返回给定值的反正切值。在此命令中,我们计算 0(零)和 -1 的反正切值,它等于数学常数 PI。  使用 rand() 函数打印 0 和 1 之间的随机值。rand() 函数的值在零和一之间均匀分布。  Awk 脚本如果你在使用命令行时遇到困难,特别是对于较长的程序(命令),并且你熟悉传统的脚本程序,你可以将你的 awk 命令转移到脚本程序中。 在我们的脚本示例中,我们将执行以下所有操作
awk 的 BEGIN 规则完成初始步骤,而其 END 规则返回计数器值。另一方面,中间规则没有名称,也没有模式,因此它匹配每一行并修改第二个字段并递增计数器。  我们提供以下脚本作为文本,以便你可以将其复制并粘贴到你的程序中并执行 将上述脚本保存为 omit.awk 文件,然后使用 chmod 按如下方式键入以下命令来执行此脚本 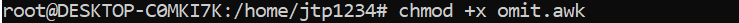 现在,我们运行此脚本并将 /etc/passwd 文件传递给脚本。“passwd" 文件将处理 omit.awk 脚本。  脚本文件继续执行并打印并显示每一行,如下所示  让我们看另一个使用表达式和控制流语句打印 1 到 5 的平方数的示例  如果你觉得阅读、编写和理解像上面那样的一行命令有困难,你可以创建一个单独的长脚本程序,并在你的 awk 命令中执行该程序。 让我们看看上面的平方打印命令是如何写成脚本程序并在命令中使用的。将上面的程序写成脚本程序,并将其保存为 program.awk 文件。 program.awk 通过将文件名 program.awk 传递给 awk 解释器来执行上面的脚本  我们还可以通过使用指令并设置 awk 解释器来运行 awk 脚本程序作为可执行程序 program2.awk 将上面的脚本文件保存为 program2.awk 并执行以下命令来运行程序  一些其他的 awk 命令考虑一个包含以下数据的文本文件 "employee.txt",我们将在此文件上应用一些 awk 命令并进行处理。 employee.txt 1. 打印文件 awk 命令的默认行为是打印输入文件中的每一行记录。  输出 John Manager Account 48000 Michel Content Developer 35000 Ashutosh Content Developer 30000 James Manager Sales 50000 Akash Software Developer 40000 John Manager Marketing 45000 Mike Product Manager 40000 2. 打印与输入数据匹配的行 awk 命令打印所有与 'Content' 词匹配的行。  输出 Michel Content Developer 35000 Ashutosh Content Developer 30000 3. 打印所有不与输入数据匹配的行 awk 命令打印所有不与输入数据 'Content' 词匹配的行。  输出 John Manager Account 48000 James Manager Sales 50000 Akash Software Developer 40000 John Manager Marketing 45000 Mike Product Manager 40000 4. 将一行分割成字段 awk 命令在遇到默认的空格字符时会分割每行的记录,并将它们存储在 $n 变量中。例如,一行包含五个单词,awk 分别将每个记录存储在 $1、$2、$3、$4 和 $5 中。完整的行代表 $0。让我们分割行并打印 $1 和 $4 中的值,分别代表姓名和薪资字段。  输出 John 48000 Michel 35000 Ashutosh 30000 James 50000 Akash 40000 John 45000 Mike 40000 使用 NR 内置变量(显示行号) 带有 NR 内置变量的 awk 命令会打印所有行以及行号。  输出 1 John Manager Account 48000 2 Michel Content Developer 35000 3 Ashutosh Content Developer 30000 4 James Manager Sales 50000 5 Akash Software Developer 40000 6 John Manager Marketing 45000 7 Mike Product Manager 40000 使用 NF 内置变量(显示最后一个字段) 带有 NF 内置变量的 awk 命令将打印最后一个字段,即记录的薪资。  输出 John 48000 Michel 35000 Ashutosh 30000 James 50000 Akash 40000 John 45000 Mike 40000 使用 NR 内置变量的另一个用法(显示第 2 到第 5 行) awk 'NR==2, NR==5 {print NR,$0}' employee.txt  输出 2 Michel Content Developer 35000 3 Ashutosh Content Developer 30000 4 James Manager Sales 50000 5 Akash Software Developer 40000 考虑另一个文件 test.txt,其中包含以下数据。 test.txt 1) 打印 test.txt 中每行的第一个项目,并用“-”分隔行号 (NR)  输出 1 - James 2 - Shiv 3 - Ratan 2) 从 test.txt 打印第二行/项目  输出 A12 B6 M42 3) 查找文件中最长行的长度  输出 12 4) 计算文件中的总行数  输出 3 下一主题如何在 Linux 中解压文件 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
