数据挖掘中的分类和预测2025年3月17日 | 阅读 7 分钟 有两种数据分析方法可用于提取描述重要类别的模型或预测未来数据趋势。这两种方法如下:
我们使用分类和预测来提取模型,该模型代表数据类别以预测未来数据趋势。分类模型使用预测模型来预测数据的类别标签。这种分析使我们能够大规模地最好地理解数据。 分类模型预测分类类别标签,而预测模型预测连续值函数。例如,我们可以构建一个分类模型来将银行贷款申请归类为安全或风险,或者构建一个预测模型来根据潜在客户的收入和职业来预测他们在计算机设备上的支出(以美元为单位)。  什么是分类?分类的目的是识别新观测的类别或类标签。首先,使用一组数据作为训练数据。输入数据及其对应的输出集被提供给算法。因此,训练数据集包括输入数据及其相关的类标签。使用训练数据集,算法会导出模型或分类器。导出的模型可以是决策树、数学公式或神经网络。在分类中,当向模型提供无标签数据时,它应该找到其所属的类。提供给模型的新数据是测试数据集。 分类是分类记录的过程。一个简单的分类示例是检查是否下雨。答案可以是“是”或“否”。因此,有特定数量的选择。有时可能存在两个以上的类别需要分类。这称为多类别分类。 银行需要分析向特定客户提供贷款是否有风险。例如,基于多个贷款借款人的可观察数据,可以建立一个分类模型来预测信用风险。数据可以跟踪工作记录、房屋所有权或租赁情况、居住年限、存款的数量和类型、历史信用评级等。目标将是信用评级,预测因子将是其他特征,数据将代表每个消费者的案例。在此示例中,构建了一个模型来查找分类标签。标签是“风险”或“安全”。 分类是如何工作的?上面已经提到了在银行贷款申请的协助下分类的运作方式。数据分类系统有两个阶段:分类器或模型创建和分类应用。 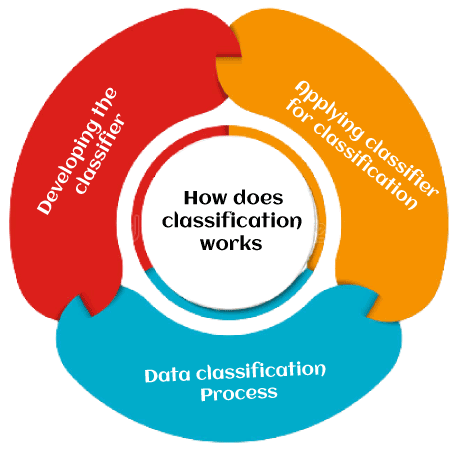
什么是数据分类生命周期?数据分类生命周期为控制企业数据的流动提供了出色的结构。企业需要在每个级别考虑数据安全和合规性。借助数据分类,我们可以在每个阶段执行此操作,从源头到删除。数据生命周期具有以下阶段: 
什么是预测?数据分析的另一个过程是预测。它用于查找数值输出。与分类一样,训练数据集包含输入和相应的数值输出值。算法根据训练数据集导出模型或预测器。当提供新数据时,模型应该找到一个数值输出。与分类不同,此方法没有类标签。模型预测一个连续值函数或有序值。 回归通常用于预测。例如,根据房间数量、总面积等事实预测房屋的价值,这是一个预测的例子。 例如,假设营销经理需要预测某个客户在促销期间将在其公司花费多少。在这种情况下,我们关心的是预测一个数值。因此,数值预测的一个例子是数据处理活动。在这种情况下,将开发一个模型或预测器,该模型或预测器可以预测一个连续或有序的值函数。 分类与预测问题主要问题是准备用于分类和预测的数据。数据准备涉及以下活动: 
注意:还可以通过其他方法(如小波变换、分箱、直方图分析和聚类)来约简数据。分类与预测方法比较以下是比较分类和预测方法的标准: 
分类与预测的区别应用于现有数据的决策树是一个分类模型。通过将其应用于类未知的新数据,我们可以获得类预测。假设新数据来自与我们用于构建决策树的数据相似的分布。在许多情况下,这是一个正确的假设,因此我们可以使用决策树来构建预测模型。分类或预测是查找描述信息类别或概念的模型的过程。目的是使用此模型来预测类标签未知对象的类。以下是分类和预测之间的一些主要区别。
下一个主题数据挖掘任务原语 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
