数据挖掘中的聚类17 Mar 2025 | 5 分钟阅读 聚类是一种基于无监督机器学习的算法,它将数据点分成若干组,使得同一组中的对象彼此相似。 聚类有助于将数据分割成几个子集。这些子集中的数据彼此相似,这些子集称为簇。一旦我们的客户数据被分割成簇,我们就可以就哪些客户最适合该产品做出明智的决定。  让我们举个例子来理解这一点。假设我们是一家市场经理,我们有一个诱人的新产品要出售。我们确信该产品只要卖给合适的人就能带来巨额利润。那么,我们如何才能从公司庞大的客户群中找出最适合该产品的人呢? 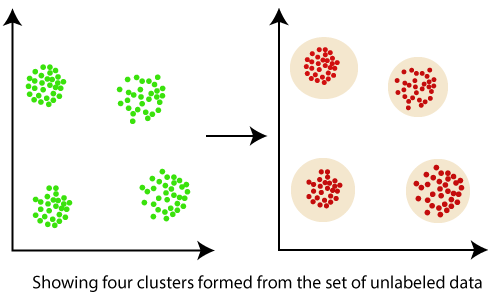 聚类属于无监督机器学习类别,是机器学习算法解决的问题之一。 聚类仅利用输入数据来确定输入数据中的模式、异常或相似性。 一个好的聚类算法旨在获得簇,这些簇具有
什么是簇?
数据挖掘中的聚类是什么?
要点
数据挖掘中聚类分析的应用
为什么在数据挖掘中使用聚类?由于其多样化的应用,聚类分析一直是数据挖掘中一个不断发展的问题。近年来各种数据聚类工具的出现及其在图像处理、计算生物学、移动通信、医学和经济学等广泛应用中的综合使用,必定促进了这些算法的普及。数据聚类算法的主要问题在于无法标准化。高级算法可能对一种数据集给出最佳结果,但对另一种数据集可能会失败或表现不佳。尽管已经付出了许多努力来标准化在所有情况下都能良好运行的算法,但迄今为止尚未取得显著成就。到目前为止,已经提出了许多聚类工具。然而,每种算法都有其优点和缺点,并且不能在所有现实情况下工作。 1. 可扩展性 聚类中的可扩展性意味着,当我们增加数据对象的数量时,执行聚类所需的时间应该大致遵循算法的复杂度阶数。例如,如果我们执行 K-Means 聚类,我们知道它是 O(n),其中 n 是数据中的对象数量。如果我们数据对象的数量增加 10 倍,那么聚类它们所需的时间也应该大约增加 10 倍。这意味着应该存在线性关系。如果不是这种情况,那么我们的实现过程可能存在一些错误。  数据应该是可扩展的,如果不可扩展,我们就无法获得适当的结果。该图说明了可能导致错误结果的图形示例。 2. 可解释性 聚类结果应该是可解释、可理解和可用的。 3. 发现具有属性形状的簇 聚类算法应能够找到任意形状的簇。它们不应仅限于倾向于发现小尺寸球形簇的距离测量。 4. 能够处理不同类型的属性 算法应能应用于任何数据,例如基于区间(数值)的数据、二进制数据和分类数据。 5. 能够处理噪声数据 数据库包含噪声、缺失或不正确的数据。一些算法对这些数据敏感,可能导致聚类质量较差。 6. 高维性 聚类工具不仅应该能够处理高维数据空间,还应该能够处理低维空间。 下一个主题文本数据挖掘 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
