深度学习算法2025年3月17日 | 阅读 10 分钟  什么是深度学习算法?深度学习可以定义为一种机器学习和人工智能的方法,旨在基于人类大脑的某些功能,模仿人类及其行为,以做出有效的决策。它是数据科学的一个非常重要的元素,它在预测建模和统计的指导下,将建模基于数据驱动的技术。为了驱动这种类人的适应和学习能力并相应地发挥作用,必须有一些强大的力量,我们通常称之为算法。 深度学习算法动态地通过神经网络的多个层运行,这些神经网络只不过是一组经过预训练以执行任务的决策网络。然后,这些网络中的每一个都通过简单的分层表示,并进入下一层。然而,大多数机器学习都被训练为在具有数百个特征或列的数据集上运行良好。对于结构化或非结构化数据集,机器学习往往会失败,主要是因为它们无法识别一个维度为 800x1000 的 RGB 简单图像。对于传统的机器学习算法来说,处理如此深度的数据是相当不可行的。这就是深度学习的用武之地。 深度学习的重要性深度学习算法在确定特征方面发挥着关键作用,并且可以处理大量可能结构化或非结构化数据。尽管如此,深度学习算法可能会对某些涉及复杂问题的任务过度使用,因为它们需要访问大量数据才能有效运行。例如,有一个流行的图像识别深度学习工具,名为 Imagenet,它可以在其数据集驱动的算法中访问 1400 万张图像。它是一个高度全面的工具,为以图像作为数据集的深度学习工具定义了新的基准。 深度学习算法是高度渐进的算法,通过将其通过每个神经网络层来学习我们之前讨论过的图像。这些层对检测图像的低级特征(如边缘和像素)高度敏感,然后组合层获取这些信息并通过与之前的数据进行比较来形成整体表示。例如,中间层可能被编程为检测照片中物体的某些特殊部分,而其他经过深度训练的层则被编程为检测特殊物体,如狗、树、餐具等。 然而,如果谈到涉及较少复杂性和数据驱动资源的简单任务,深度学习算法无法推广简单数据。这是深度学习不被认为像线性或增强树模型那样有效的主要原因之一。简单模型旨在处理自定义数据、跟踪欺诈性交易以及处理具有较少特征的复杂性较低的数据集。此外,在各种情况下,如多类别分类,深度学习可能有效,因为它涉及较小但结构化的数据集,但通常不首选。 话虽如此,让我们来了解下面给出的一些最重要的深度学习算法。 深度学习算法深度学习算法如下 1. 卷积神经网络 (CNN)CNNs,俗称 ConvNets,主要由多个层组成,专门用于图像处理和目标检测。它由 Yann LeCun 于 1998 年开发,最初被称为 LeNet。当时,它被开发用于识别数字和邮政编码字符。CNN 在卫星图像识别、医学图像处理、序列预测和异常检测方面有广泛应用。 CNN 通过将数据通过多个层并提取特征来执行卷积操作。卷积层由修正线性单元 (ReLU) 组成,用于修正特征图。池化层用于将这些特征图修正到下一个输入。池化通常是一种下采样算法,它会减少特征图的维度。然后,生成的结果由二维数组组成,该数组由在图中扁平化的单个、长、连续和线性向量组成。下一层,即全连接层,它将从池化层获取的扁平矩阵或二维数组作为输入,并通过分类来识别图像。  2. 长短期记忆网络 (LSTM)LSTM 可以定义为循环神经网络 (RNN),它被编程为学习和适应长期依赖关系。它可以在较长时间内记忆和回忆过去的数据,默认情况下,这是它的唯一行为。LSTM 被设计为随着时间的推移保留记忆,因此它们主要用于时间序列预测,因为它们可以保留记忆或以前的输入。这种类比来自于它们由四个以不同方式相互通信的交互层组成的链状结构。除了时间序列预测的应用之外,它们还可以用于构建语音识别器、药物开发以及音乐循环的组成。 LSTM 以事件序列工作。首先,它们不会记住前一状态中获得的不相关细节。接下来,它们选择性地更新某些单元状态值,最后生成单元状态的某些部分作为输出。下面是它们操作的示意图。  3. 循环神经网络 (RNN)循环神经网络(或 RNN)包含一些有向连接,这些连接形成一个循环,允许来自 LSTM 的输入在 RNN 的当前阶段用作输入。这些输入被深深地嵌入为输入,并强制 LSTM 的记忆能力让这些输入在内部存储器中吸收一段时间。因此,RNN 依赖于 LSTM 保留的输入,并在 LSTM 的同步现象下工作。RNN 主要用于图像字幕、时间序列分析、手写数据识别和数据机器翻译。 RNN 遵循的工作方法是,如果时间定义为 t,则将输出馈入 (t-1) 时间。接下来,由 t 确定的输出在输入时间 t+1 处馈入。类似地,这些过程对包含任何长度的所有输入重复。关于 RNN 还有一点是它们存储历史信息,即使模型大小增加,输入大小也不会增加。展开后的 RNN 看起来像这样。  4. 生成对抗网络 (GAN)GAN 被定义为深度学习算法,用于生成与训练数据匹配的新数据实例。GAN 通常由两个组件组成,即学习生成虚假数据的生成器和通过从虚假数据中学习来适应自身的判别器。随着时间的推移,GAN 得到了广泛的应用,因为它们经常用于澄清天文图像和模拟引力暗物质的引力透镜。它还用于视频游戏中,通过将其以 4K 等更高分辨率重新创建来增加 2D 纹理的图形。它们还用于创建逼真的卡通角色以及渲染人脸和3D 对象渲染。 GAN 通过生成和理解虚假数据和真实数据来进行模拟。在训练以理解这些数据的过程中,生成器生成不同类型的虚假数据,判别器迅速学习适应并将其响应为虚假数据。然后 GAN 将这些识别结果发送进行更新。请考虑下图以可视化其功能。  5. 径向基函数网络 (RBFN)RBFN 是一种特殊类型的神经网络,它遵循前馈方法并使用径向函数作为激活函数。它们由三个层组成,即输入层、隐藏层和输出层,主要用于时间序列预测、回归测试和分类。 RBFN 通过测量训练数据集中存在的相似性来执行这些任务。它们通常有一个输入向量,将这些数据馈入输入层,从而通过比较以前的数据集来确认识别并输出结果。准确地说,输入层有对这些数据敏感的神经元,层中的节点可以有效地对数据进行分类。神经元最初存在于隐藏层中,但它们与输入层紧密集成。隐藏层包含高斯传递函数,其与输出与神经元中心的距离成反比。输出层具有基于径向数据的线性组合,其中高斯函数作为参数传递到神经元中,并生成输出。请考虑下图以彻底理解此过程。  6. 多层感知机 (MLP)MLP 是深度学习技术的基础。它属于一类具有各种感知器层的前馈神经网络。这些感知器具有各种激活函数。MLP 还具有连接的输入和输出层,它们的数量相同。此外,在这两层之间还有一个隐藏层。MLP 主要用于构建图像和语音识别系统或其他类型的翻译软件。 MLP 的工作原理是从输入层输入数据开始。层中的神经元形成一个图,以建立一个单向连接。此输入数据的权重存在于隐藏层和输入层之间。MLP 使用激活函数来确定哪些节点已准备好激活。这些激活函数包括 tanh 函数、sigmoid 和 ReLU。MLP 主要用于训练模型,以了解这些层正在服务于哪种关联,以从给定数据集中获得所需的输出。请参阅下图以更好地理解。  7. 自组织映射 (SOM)SOM 由 Teuvo Kohenen 发明,用于实现数据可视化,通过人工和自组织神经网络理解数据的维度。通过数据可视化解决问题的尝试主要由人类无法可视化的情况完成。这些数据通常是高维的,因此人类参与的机会较小,当然错误也较少。 SOMs 通过初始化不同节点的权重,然后从给定的训练数据中选择随机向量来帮助可视化数据。它们检查每个节点以找到相对权重,以便可以理解依赖关系。决定获胜节点,这被称为最佳匹配单元(BMU)。随后,SOMs 发现这些获胜节点,但节点会随着时间从样本向量中减少。因此,节点越接近 BMU,识别权重和执行进一步活动的机会就越大。还进行了多次迭代以确保不会遗漏任何靠近 BMU 的节点。一个这样的例子是我们日常任务中使用的 RGB 颜色组合。请考虑下图以了解它们的功能。  8. 深度信念网络 (DBN)DBN 被称为生成模型,因为它们具有多层潜在变量和随机变量。潜在变量被称为隐藏单元,因为它们具有二进制值。DBN 也被称为玻尔兹曼机,因为 RGM 层彼此堆叠以建立与前一层和后续层的通信。DBN 用于视频和图像识别以及捕获运动物体等应用。 DBN 由贪婪算法提供支持。通过自上而下的方法逐层学习以生成权重是 DBN 最常见的功能方式。DBN 在顶部的隐藏两层上使用逐步的 Gibbs 采样方法。然后,这些阶段使用遵循祖先采样方法的模型从可见单元中提取样本。DBN 通过遵循自下而上的传递方法从每层中存在的潜在值中学习。  9. 受限玻尔兹曼机 (RBM)RBM 由 Geoffrey Hinton 开发,类似于随机神经网络,它从给定输入集中的概率分布中学习。该算法主要用于维度降维、回归和分类、主题建模领域,并被认为是 DBN 的构建块。RBM 由两层组成,即可见层和隐藏层。这两层通过隐藏单元连接,并具有连接到生成输出的节点的偏置单元。通常,RBM 有两个阶段,即前向传播和反向传播。 RBM 的功能通过接受输入并将其转换为数字来实现,以便在正向传播中对输入进行编码。RBM 考虑每个输入的权重,而反向传播获取这些输入权重并将其进一步转换为重建的输入。然后,将这些转换后的输入以及各个权重组合起来。然后将这些输入推送到可见层,在那里执行激活并生成可以轻松重建的输出。要理解此过程,请考虑下图。 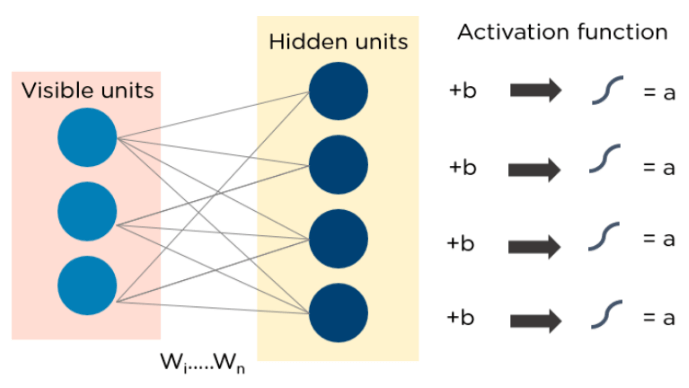 自动编码器自编码器是一种特殊类型的神经网络,其中输入和输出通常是相同的。它主要旨在解决与无监督学习相关的问题。自编码器是经过高度训练的神经网络,可以复制数据。这就是为什么输入和输出通常相同的原因。它们用于实现药物发现、图像处理和人口预测等任务。 自编码器由三个组成部分构成,即编码器、代码和解码器。自编码器以这样的结构构建,它们可以接收输入并将其转换为各种表示。通过重建尝试复制原始输入更准确。它们通过编码图像或输入,减小大小来做到这一点。如果图像无法正确显示,它们会传递到神经网络进行澄清。然后,澄清后的图像被称为重建图像,这与之前的图像一样准确。要理解这个复杂的过程,请参阅下面提供的图像。  总结在本文中,我们主要使用了深度学习以及深度学习背后的算法。首先,我们了解了深度学习如何以动态的速度改变工作,旨在创建可以重建和像人脑一样运作的智能软件。然后,在本文中,我们学习了一些最常用的深度学习算法,并了解了驱动这些算法的组件。通常,要理解这些算法,一个人需要对一些算法中讨论的数学函数有很高的清晰度。这些函数非常关键,这些算法的工作方式主要取决于使用这些函数和公式进行的计算。一个有抱负的深度学习工程师了解所有这些算法,强烈建议初学者在进入人工智能之前理解这些算法。 下一主题3D 深度学习入门 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
