预测 LL(1) 分析器2025 年 7 月 15 日 | 阅读 7 分钟 在本文中,我们将通过各种示例来理解预测 LL(1) 解析器的概念。 引言在 LL(1) 中,第一个 L 意味着输入是从左到右扫描的,下一个 L 意味着它使用最左推导,而 1 表示预测解析过程的超前符号。 如果它是非递归类型,则它是一种自顶向下的解析算法。在这种类型的解析中,会创建一个解析表。这是实现递归下降解析的有效方法。 在这种语法中,解析过程中将预测非终结符扩展的正确选项。因此不需要回溯。 预测 LL(1) 解析器的组成部分以下是预测 LL(1) 解析器的各种组成部分的列表 输入缓冲区输入缓冲区保存要由解析器处理的输入符号。它提供了一种前瞻机制,允许解析器检查下一个输入符号而不使用它。它包含要解析的字符串,后跟一个结束标记$,该标记表示字符串的结尾。 下图表示输入缓冲区的运作方式。 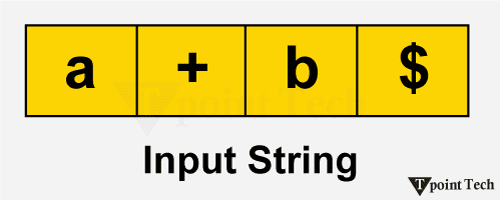 在上图中,输入缓冲区显示为终结符和非终结符的集合。输入缓冲区的末尾用“$”符号标记。基于解析堆栈的顶部和当前的输入符号,解析表指示解析器的操作。解析器要处理的下一个输入符号由输入缓冲区中的箭头符号指示。当解析器从输入缓冲区读取符号并处理每个符号直到标记的末尾时,箭头向右移动。 Stack它也被称为解析堆栈,解析器用它来跟踪当前状态。它在堆栈底部包含“$”。在解析开始时,堆栈由语法的初始符号组成,后跟$。 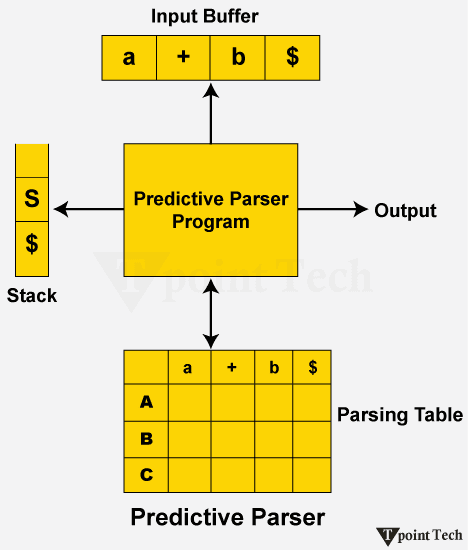 预测解析表这是一个用于预测解析的数据结构。它将非终结符和超前符号的组合映射到产生式规则。 下表将解析表表示为行和列的组合。行表示非终结符,列表示终结符和($)。 解析表
解析器的运作方式解析程序读取堆栈顶部和当前的输入符号,然后确定解析动作。
构建预测 LL1 解析器的步骤它基于两个函数,例如 FIRST 和 FOLLOW。 为了构建 LL(1) 解析器,我们必须遵循以下步骤 步骤 1:在第一步中,检查所有重要条件,例如语法不包含左递归,语法不应模棱两可且进行左因子分解。 步骤 2:然后计算语法中所有非终结符的 first 和 follow 函数。 步骤 3:使用 FIRST 和 FOLLOW 函数创建一个谓词解析表。对于语法中的每个产生式规则 A --> α。
步骤 4:在最后一步中,借助解析表解析输入字符串。 示例 1:以具有一组产生式规则的以下语法为例解决方案步骤 1:在第一步中,检查所有重要条件,例如语法不包含左递归,语法不应模棱两可且进行左因子分解。 上述语法包含左递归。因此,在删除后考虑以下语法 步骤 2:计算上述语法的 First 和 Follow 集 下表表示语法的 First 集。
下表表示语法的 Follow 集。
步骤 3:之后,构建预测 (LL1) 解析表。
什么是 FIRST 函数?First 函数是首次出现在 alpha 推导中右侧的终结符的集合。 示例 1:考虑以下语法并计算 FIRST 函数。产生式规则集是 解决方案终结符集是:id, *, +, ε, (, ) 非终结符集是:A, A’, B, B’, C 上述语法的 first 和 follow 如下所示 找到“A”的 first。A -> BA’ 在上面的规则中,产生的右侧是非终结符,所以我们转到下一个产生式规则 B -> CB',其中第一个元素又是非终结符,所以我们转到下一个产生式规则 C->(ε)/id,其中第一个元素是终结符,这将是 A 的 first。 找到“A’”的 first。A’ -> +BA’/ε 在上面的规则中,产生的右侧是非终结符,所以我们转到下一个产生式规则 B -> CB',其中第一个元素又是非终结符,所以下一个产生式规则 C->(ε)/id,其中第一个元素是终结符,这将是 A' 的 first。 找到“B”的 first。B -> CB’ 在上面的规则中,产生的右侧是 C,它是一个非终结符,但我们必须找到终结符,所以我们转到下一个产生式规则 C->(ε)/id,其中第一个元素是终结符,这将是 B 的 first。 找到“B’”的 first。B’ -> *CB’/ε 在上面的规则中,产生式 C 的右侧是非终结符,但我们必须找到终结符,所以我们转到产生式规则 C->(ε)/id,其中第一个元素是终结符,这将是 B' 的 first。 找到“C”的 first。C->(ε)/id 在上面的规则中,第一个元素是终结符,这将是 C’ 的 first。
什么是 Follow 函数?这是可以显示在产生式的非终结符右侧的终结符的集合。 找到“A”的 followA -> BA’ 在上述产生式规则中,我们找到 C 在产生式的右侧的产生式,即 B -> CB’ C->(ε)/id 因此,follow 将是下一个非终结符,后跟终结符 ')’,并且在 follow 中,始终添加“$”。 (A) 的 follow 是 ={$,)} 注意:通过使用上述方法来计算其他非终结符的 follow。
FIRST 和 FOLLOW 函数在 LL(1) 解析中的重要性这两个函数在 LL(1) 解析和语法分析中都起着重要作用,具有许多重要的应用
这有助于创建 LL(1) 解析器使用的解析表。
如果解析表中没有任何非终结符和输入符号的重叠条目,我们可以检查语法是否满足 LL(1) 条件。
当可以获得非终结符 ε 时,FIRST 集中包含空字符串。 预测解析的局限性预测解析的各种局限性如下
关于 LL(1) 解析的常见问题解答1. 编译器设计中 first 和 follow 函数的必要性是什么? 答案:这两个函数帮助解析器在正确的位置应用所需的规则。 2. 列出 first 函数的一些好处? 答案
下一个主题语法制导翻译 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
