感知器模型17 Mar 2025 | 4 分钟阅读 了解感知器模型以及诸如交叉熵、Sigmoid 梯度下降等关键术语至关重要。那么什么是感知器模型,它有什么作用? 让我们看一个例子来理解感知器模型。假设有一家医院每年对数千名患者进行手术,并要求你创建一个预测模型,该模型能够准确确定某人是否可能患有癌症。 借助先前确定的数据,我们根据他们的年龄(横坐标)和吸入的烟草量(纵坐标)来预测某人是否可能患有癌症。  因此,年龄较大且吸烟量较大的人患癌症的几率较高,而年龄较小且吸烟量较少的人患癌症的几率较低。 每个绿色点表示患癌症的几率较高,最初被分配标签为零;每个蓝色点表示患癌症的几率较低,最初被分配标签为一。  因此,我们将从一个随机模型开始,该模型无法正确分类我们的数据,但随后该模型将通过某种优化算法进行训练。该模型将经过多次迭代训练,直到达到可以正确分类我们数据的参数值。我们使用先前标记的数据,这里的一切都被标记为一,而这里的一切都被标记为零。  我们使用这些标记的数据来提出一个预测模型,该模型将我们的数据分类为两个离散类别。使用该模型,我们现在可以对新输入的没有标签的数据进行预测,基于该点是位于线下方还是上方。我们将训练我们的模型,该模型可以确定此人属于一类,因此他们最有可能健康。  现在,最大的问题是计算机如何知道如何提出这个线性模型。为此,我们将计算与此模型相关的误差,然后重新调整模型的参数以最小化误差并正确分类数据点。我们将使用 **交叉熵 ()** 函数来查找误差,并使用 **Sigmoid 梯度下降** 来优化参数。让我们开始实现代码,在其中我们将看到如何使用交叉熵函数和 Sigmoid 梯度下降。 因此,我们处理的是我们在上一节中创建的数据集。现在,借助此数据集,我们将开始实现我们的代码并创建一个基本的感知器模型。 首先,我们将 plt.scatter(x[y==0,0],x[y==0,1]) 和 plt.scatter(x[y==1,0],x[y==1,1]) 放入一个函数中,以供进一步使用,如下所示 要创建基本的感知器模型,我们必须按照以下步骤操作 步骤 1。 我们的第一步是创建一个线性模型。为此,我们必须创建我们的模型类,就像我们在具有 init() 方法和 forward() 方法的线性回归模型中实现的那样。 init() 方法类似,但 forward() 方法与线性回归模型完全不同。我们定义 forward () 如下,首先替换 self 作为第一个参数,然后我们需要传递输入 x。 之后,我们通过将我们的数据 x 传递到我们的线性模型中来进行预测。 这还不够,我们必须通过应用 sigmoid () 方法将值转换为概率,如下所示 我们的初始化已完成,现在我们可以使用它了。 步骤 2 我们将使用 Perceptron_model() 构造函数初始化一个新的线性模型,并将 input_size 和 output_size 作为参数传递。现在,打印分配给它的随机权重和偏差值,如下所示 在此之前,为了确保我们随机结果的一致性,我们可以使用 torch manual seed 为我们的随机数生成器播种,我们可以设置一个 seed 为 2,如下所示 步骤 3 我们的下一步是通过解包模型提取模型参数。这些参数以包含两个元素的列表形式提取,即 A、B,并打印两个值,如下所示 这里,A 是权重,B 是偏差。  为了简洁起见,我们使用函数以以下方式返回 A1.item()、A2.item() 和 B1[0].item() 的值 步骤 4 现在,我们使用我们以列表形式提取的参数绘制我们的线性模型。我们使用标题、直线方程等等。我们创建一个用户定义函数来绘制我们的数据。让我们看看绘制线性模型的代码。 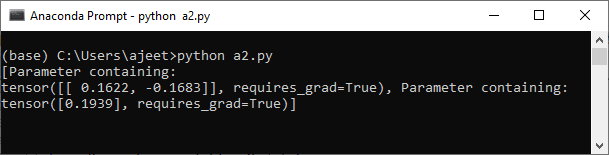  下一个主题感知器模型的训练 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
