| 序号 | 类和模块 | 描述 |
|---|
| 1. | torch.nn.Parameter | 它是一种张量,被视为模块参数。 |
| 2. | 容器 | |
| 1) torch.nn.Module | 它是所有神经网络模块的基类。 |
| 2) torch.nn.Sequential | 它是一个顺序容器,模块将按照它们在构造函数中传递的相同顺序添加。 |
| 3) torch.nn.ModuleList | 这将在列表中保存子模块。 |
| 4) torch.nn.ModuleDict | 这将在目录中保存子模块。 |
| 5) torch.nn.ParameterList | 这将在列表中保存参数。 |
| 6) torch.nn.parameterDict | 这将在目录中保存参数。 |
| 3. | 卷积层 | |
| 1) torch.nn.Conv1d | 此包将用于对由多个输入平面组成的输入信号应用一维卷积。 |
| 2) torch.nn.Conv2d | 此包将用于对由多个输入平面组成的输入信号应用二维卷积。 |
| 3) torch.nn.Conv3d | 此包将用于对由多个输入平面组成的输入信号应用三维卷积。 |
| 4) torch.nn.ConvTranspose1d | 此包将用于对由多个输入平面组成的输入图像应用一维转置卷积运算符。 |
| 5) torch.nn.ConvTranspose2d | 此包将用于对由多个输入平面组成的输入图像应用二维转置卷积运算符。 |
| 6) torch.nn.ConvTranspose3d | 此包将用于对由多个输入平面组成的输入图像应用三维转置卷积运算符。 |
| 7) torch.nn.Unfold | 它用于从批量输入张量中提取滑动局部块。 |
| 8) torch.nn.Fold | 它用于将滑动局部块数组组合成一个大的包含张量。 |
| 4. | 池化层 | |
| 1) torch.nn.MaxPool1d | 它用于对由多个输入平面组成的输入信号应用一维最大池化。 |
| 2) torch.nn.MaxPool2d | 它用于对由多个输入平面组成的输入信号应用二维最大池化。 |
| 3) torch.nn.MaxPool3d | 它用于对由多个输入平面组成的输入信号应用三维最大池化。 |
| 4) torch.nn.MaxUnpool1d | 它用于计算 MaxPool1d 的部分逆。 |
| 5) torch.nn.MaxUnpool2d | 它用于计算 MaxPool2d 的部分逆。 |
| 6) torch.nn.MaxUnpool3d | 它用于计算 MaxPool3d 的部分逆。 |
| 7) torch.nn.AvgPool1d | 它用于对由多个输入平面组成的输入信号应用一维平均池化。 |
| 8) torch.nn.AvgPool2d | 它用于对由多个输入平面组成的输入信号应用二维平均池化。 |
| 9) torch.nn.AvgPool3d | 它用于对由多个输入平面组成的输入信号应用三维平均池化。 |
| 10) torch.nn.FractionalMaxPool2d | 它用于对由多个输入平面组成的输入信号应用二维分数最大池化。 |
| 11) torch.nn.LPPool1d | 它用于对由多个输入平面组成的输入信号应用一维幂平均池化。 |
| 12) torch.nn.LPPool2d | 它用于对由多个输入平面组成的输入信号应用二维幂平均池化。 |
| 13) torch.nn.AdavtiveMaxPool1d | 它用于对由多个输入平面组成的输入信号应用一维自适应最大池化。 |
| 14) torch.nn.AdavtiveMaxPool2d | 它用于对由多个输入平面组成的输入信号应用二维自适应最大池化。 |
| 15) torch.nn.AdavtiveMaxPool3d | 它用于对由多个输入平面组成的输入信号应用三维自适应最大池化。 |
| 16) torch.nn.AdavtiveAvgPool1d | 它用于对由多个输入平面组成的输入信号应用一维自适应平均池化。 |
| 17) torch.nn.AdavtiveAvgPool2d | 它用于对由多个输入平面组成的输入信号应用二维自适应平均池化。 |
| 18) torch.nn.AdavtiveAvgPool3d | 它用于对由多个输入平面组成的输入信号应用三维自适应平均池化。 |
| 5. | 填充层 | |
| 1) torch.nn.ReflectionPad1d | 它将使用输入边界的反射来填充输入张量。 |
| 2) torch.nn.ReflactionPad2d | 它将使用输入边界的反射来填充输入张量。 |
| 3) torch.nn.ReplicationPad1 | 它将使用输入边界的复制来填充输入张量。 |
| 4) torch.nn.ReplicationPad2d | 它将使用输入边界的复制来填充输入张量。 |
| 5) torch.nn.ReplicationPad3d | 它将使用输入边界的复制来填充输入张量。 |
| 6) torch.nn.ZeroPad2d | 它将用零填充输入张量边界。 |
| 7) torch.nn.ConstantPad1d | 它将用一个常数值填充输入张量边界。 |
| 8) torch.nn.ConstantPad2d | 它将用一个常数值填充输入张量边界。 |
| 9) torch.nn.ConstantPad3d | 它将用一个常数值填充输入张量边界。 |
| 6. | 非线性激活(加权和,非线性) | |
| 1) torch.nn.ELU | 它将用于应用逐元素函数
ELU(x)=max(0,x)+min(0,α*(exp(x)-1)) |
| 2) torch.nn.Hardshrink | 它将用于应用逐元素硬收缩函数
 |
| 3) torch.nn.LeakyReLU | 它将用于应用逐元素函数
LeakyReLu(x)=max(0,x) +negative_slope*min(0,x) |
| 4) torch.nn.LogSigmoid | 它将用于应用逐元素函数
 |
| 5) torch.nn.MultiheadAttention | 它用于允许模型关注来自不同表示子空间的信息 |
| 6) torch.nn.PReLU | 它将用于应用逐元素函数
PReLU(x)=max(0,x)+a*min(0,x) |
| 7) torch.nn.ReLU | 它将用于逐元素应用修正线性单元函数
ReLU(x)=max(0,x) |
| 8) torch.nn.ReLU6 | 它将用于应用逐元素函数
ReLU6(x)=min(max(0,x),6) |
| 9) torch.nn.RReLU | 它将用于逐元素应用论文中描述的随机泄漏修正线性单元函数
 |
| 10) torch.nn.SELU | 它将用于应用逐元素函数,例如
SELU(x)=scale*(max(0,x)+ min(0,a*(exp(x)-1)))
其中 α= 1.6732632423543772848170429916717 且 scale = 1.0507009873554804934193349852946。 |
| 11) torch.nn.CELU | 它将用于应用逐元素函数,例如
 |
| 12) torch.nn.Sigmoid | 它将用于应用逐元素函数,例如
 |
| 13) torch.nn.Softplus | 它将用于应用逐元素函数,例如
 |
| 14) torch.nn.Softshrink | 它将用于逐元素应用软收缩函数,例如
 |
| 15) torch.nn.Softsign | 它将用于应用逐元素函数,例如
 |
| 16) torch.nn.Tanh | 它将用于应用逐元素函数,例如
 |
| 17) torch.nn.Tanhshrink | 它将用于应用逐元素函数,例如
Tanhshrink(x)=x-Tanh(x) |
| 18) torch.nn.Threshold | 它将用于对输入张量的每个元素进行阈值处理。阈值定义为
 |
| 7. | 非线性激活(其他) | |
| 1) torch.nn.Softmin | 它用于对 n 维输入张量应用 softmin 函数以重新缩放它们。之后,n 维输出张量的元素位于 0, 1 范围内,并且总和为 1。Softmin 定义为
 |
| 2) torch.nn.Softmax | 它用于对 n 维输入张量应用 softmax 函数以重新缩放它们。之后,n 维输出张量的元素位于 0, 1 范围内,并且总和为 1。Softmax 定义为
 |
| 3) torch.nn.Softmax2d | 它用于对每个空间位置的特征应用 SoftMax。 |
| 4) torch.nn.LogSoftmax | 它用于对 n 维输入张量应用 LogSoftmax 函数。LofSoftmax 函数可以定义为
 |
| 5) torch.nn.AdaptiveLogSoftmaxWithLoss | 这是一种用于训练具有大型输出空间的模型的策略。当标签分布高度不平衡时,它非常有效 |
| 8. | 归一化层 | |
| 1) torch.nn.BatchNorm1d | 它用于对二维或三维输入应用批量归一化。
 |
| 2) torch.nn.BatchNorm2d | 它用于对四维输入应用批量归一化。
 |
| 3) torch.nn.BatchNorm3d | 它用于对五维输入应用批量归一化。
 |
| 4) torch.nn.GroupNorm | 它用于对小批量输入应用组归一化。
|
| 5) torch.nn.SyncBatchNorm | 它用于对 n 维输入应用批量归一化。
|
| 6) torch.nn.InstanceNorm1d | 它用于对三维输入应用实例归一化。
|
| 7) torch.nn.InstanceNorm2d | 它用于对四维输入应用实例归一化。
|
| 8) torch.nn.InstanceNorm3d | 它用于对五维输入应用实例归一化。
|
| 9) torch.nn.LayerNorm | 它用于对小批量输入应用层归一化。
|
| 10) torch.nn.LocalResponseNorm | 它用于对由多个输入平面组成的输入信号应用局部响应归一化,其中通道占据第二维。 |
| 9. | 循环层 | |
| 1) torch.nn.RNN | 它用于将具有 tanh 或 ReLU 非线性的多层 Elman RNN 应用于输入序列。每个层为输入序列中的每个元素计算以下函数
ht=tanh(Wih xt+bih+Whh tt-1+bhh) |
| 2) torch.nn.LSTM | 它用于将多层长短期记忆 (LSTM) RNN 应用于输入序列。每个层为输入序列中的每个元素计算以下函数
 |
| 3) torch.nn.GRU | 它用于将多层门控循环单元 (GRU) RNN 应用于输入序列。每个层为输入序列中的每个元素计算以下函数
 |
| 4) torch.nn.RNNCell | 它用于将具有 tanh 或 ReLU 非线性的 Elman RNN 单元应用于输入序列。每个层为输入序列中的每个元素计算以下函数
h'=tanh(Wih x+bih+Whh h+bhh)
ReLU 用于代替 tanh |
| 5) torch.nn.LSTMCell | 它用于将长短期记忆 (LSTM) 单元应用于输入序列。每个层为输入序列中的每个元素计算以下函数

其中 σ 是 sigmoid 函数,* 是 Hadamard 积。 |
| 6) torch.nn.GRUCell | 它用于将门控循环单元 (GRU) 单元应用于输入序列。每个层为输入序列中的每个元素计算以下函数
 |
| 10. | 线性层 | |
| 1) torch.nn.Identity | 它是一个与参数无关的占位符恒等运算符。 |
| 2) torch.nn.Linear | 它用于对传入数据应用线性变换
y=xAT+b |
| 3) torch.nn.Bilinear | 它用于对传入数据应用双线性变换
y=x1 Ax2+b |
| 11. | Dropout 层 | |
| 1) torch.nn.Dropout | 它用于正则化和防止神经元共适应。训练期间的因子 会缩放输出。这意味着模块在评估期间计算恒等函数。 会缩放输出。这意味着模块在评估期间计算恒等函数。 |
| 2) torch.nn.Dropout2d | 如果特征图内的相邻像素是相关的,则 torch.nn.Dropout 将不会正则化激活,并且会降低有效学习率。在这种情况下,torch.nn.Dropout2d() 用于促进特征图之间的独立性。 |
| 3) torch.nn.Dropout3d | 如果特征图内的相邻像素是相关的,则 torch.nn.Dropout 将不会正则化激活,并且会降低有效学习率。在这种情况下,torch.nn.Dropout2d () 用于促进特征图之间的独立性。 |
| 4) torch.nn.AlphaDropout | 它用于对输入应用 Alpha Dropout。Alpha Dropout 是一种 Dropout 类型,它保持自归一化特性。 |
| 12. | 稀疏层 | |
| 1) torch.nn.Embedding | 它用于存储词嵌入并使用索引检索它们。模块的输入是索引列表,输出是相应的词嵌入。 |
| 2) torch.nn.EmbeddingBag | 它用于计算嵌入“包”的总和或平均值,而无需实例化中间嵌入。 |
| 13. | 距离函数 | |
| 1) torch.nn.CosineSimilarity | 它将返回 x1 和 x2 之间的余弦相似度,沿 dim 计算。
 |
| 2) torch.nn.PairwiseDistance | 它使用 p 范数计算向量 v1、v2 之间的批量成对距离
 |
| 14. | 损失函数 | |
| 1) torch.nn.L1Loss | 它用于一个准则,该准则测量输入 x 和目标 y 中每个元素之间的平均绝对误差。未缩减的损失可以描述为
l(x,y)=L={l1,...,ln },ln=|xn-yn |,
其中 N 是批量大小。 |
| 2) torch.nn.MSELoss | 它用于一个准则,该准则测量输入 x 和目标 y 中每个元素之间的均方误差。未缩减的损失可以描述为
l(x,y)=L={l1,...,ln },ln=(xn-yn)2,
其中 N 是批量大小。 |
| 3) torch.nn.CrossEntropyLoss | 此准则将 nn.LogSoftmax() 和 nn.NLLLoss() 组合在一个类中。当我们训练具有 C 个类别的分类问题时,它很有用。 |
| 4) torch.nn.CTCLoss | Connectionist Temporal Classification 损失计算连续时间序列和目标序列之间的损失。 |
| 5) torch.nn.NLLLoss | 负对数似然损失用于训练具有 C 个类别的分类问题。 |
| 6) torch.nn.PoissonNLLLoss | 具有目标 t 的泊松分布的负对数似然损失
target~Poisson(input)loss(input,target)=input-target*log(target!)he target. |
| 7) torch.nn.KLDivLoss | 它是一种用于连续分布的有用距离度量,当我们对连续输出分布空间执行直接回归时,它也很有用。 |
| 8) torch.nn.BCELoss | 它用于创建一个准则,该准则测量目标和输出之间的二元交叉熵。未缩减的损失可以描述为
l(x,y)=L={l1,...,ln },ln=-wn [yn*logxn+ (1-yn )*log(1-xn)],
其中 N 是批量大小。 |
| 9) torch.nn.BCEWithLogitsLoss | 它将 Sigmoid 层和 BCELoss 组合在一个类中。我们可以通过将操作组合到一个层中来利用对数和指数技巧以实现数值稳定性。 |
| 10) torch.nn.MarginRankingLoss | 它创建一个准则,该准则测量给定输入 x1、x2(两个一维小批量张量)和包含 1 或 -1 的标签一维小批量张量 y 的损失。小批量中每个样本的损失函数如下
loss(x,y)=max(0,-y*(x1-x2 )+margin |
| 11) torch.nn.HingeEmbeddingLoss | HingeEmbeddingLoss 测量给定输入张量 x 和包含 1 或 -1 的标签张量 y 的损失。它用于测量两个输入是相似还是不相似。损失函数定义为
 |
| 12) torch.nn.MultiLabelMarginLoss | 它用于创建一个准则,该准则优化输入 x 和输出 y 之间的多类多分类铰链损失。
 |
| 13) torch.nn.SmoothL1Loss | 它用于创建一个准则,如果绝对逐元素误差低于 1 则使用平方项,否则使用 L1 项。它也称为 Huber 损失
 |
| 14) torch.nn.SoftMarginLoss | 它用于创建一个准则,该准则优化输入张量 x 和包含 1 或 -1 的目标张量 y 之间的两类分类逻辑损失。
 |
| 15) torch.nn.MultiLabelSoftMarginLoss | 它用于创建一个准则,该准则根据输入 x 和大小为 (N, C) 的目标 y 之间的最大熵优化多标签一对多损失。
 |
| 16) torch.nn.CosineEmbeddingLoss | 它用于创建一个准则,该准则测量给定输入张量 x1、x2 和值为 1 或 -1 的张量标签 y 的损失。它用于使用余弦距离测量两个输入是相似还是不相似。
 |
| 17) torch.nn.MultiMarginLoss | 它用于创建一个准则,该准则优化输入 x 和输出 y 之间的多类分类铰链损失。
 |
| 18) torch.nn.TripletMarginLoss | 它用于创建一个准则,该准则测量给定输入张量 x1、x2、x3 和值大于 0 的边距的三元组损失。它用于测量样本之间的相对相似性。一个三元组由一个锚点、一个正例和一个负例组成。
L(a,p,n)=max{d(ai,pi )-d(ai,ni )+margin,0} |
| 15. | 视觉层 | |
| 1) torch.nn.PixelShuffle | 它用于将形状为(*,C×r2,H,W) 的张量中的元素重新排列为形状为 (*,C,H×r,W,r) 的张量 |
| 2) torch.nn.Upsample | 它用于上采样给定的多通道一维、二维或三维数据。 |
| 3) torch.nn.upsamplingNearest2d | 它用于对由多个输入通道组成的输入信号应用二维最近邻上采样。 |
| 4) torch.nn.UpsamplingBilinear2d | 它用于对由多个输入通道组成的输入信号应用二维双线性上采样。 |
| 16. | DataParallel 层(多 GPU,分布式) | |
| 1) torch.nn.DataParallel | 它用于在模块级别实现数据并行性。 |
| 2) torch.nn.DistributedDataParallel | 它用于在模块级别实现分布式数据并行性,该并行性基于 torch.distributed 包。 |
| 3) torch.nn.DistributedDataParallelCPU | 它用于在模块级别实现 CPU 的分布式数据并行性。 |
| 17. | 实用工具 | |
| 1) torch.nn.clip_grad_norm_ | 它用于裁剪可迭代参数的梯度范数。 |
| 2) torch.nn.clip_grad_value_ | 它用于将可迭代参数的梯度范数裁剪到指定值。 |
| 3) torch.nn.parameters_to_vector | 它用于将参数转换为一个向量。 |
| 4) torch.nn.vector_to_parameters | 它用于将一个向量转换为参数。 |
| 5) torch.nn.weight_norm | 它用于对给定模块中的参数应用权重归一化。
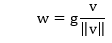 |
| 6) torch.nn.remove_weight_norm | 它用于从模块中移除权重归一化和重参数化。 |
| 7) torch.nn.spectral_norm | 它用于对给定模块中的参数应用谱归一化。 |
| 8) torch.nn.PackedSequence | 它将用于保存打包序列的数据和 batch_sizes 列表。 |
| 9) torch.nn.pack_padded_sequence | 它用于打包包含可变长度填充序列的张量。 |
| 10) torch.nn.pad_packed_sequence | 它用于填充可变长度序列的打包批次。 |
| 11) torch.nn.pad_sequence | 它用于用填充值填充可变长度张量列表。 |
| 12) torch.nn.pack_sequence | 它用于打包可变长度张量列表 |
| 13) torch.nn.remove_spectral_norm | 它用于从模块中移除谱归一化和重参数化。 |
