CIFAR-10 数据集的 LeNet 模型测试17 Mar 2025 | 5 分钟阅读 在上一篇中,我们发现我们的卷积神经网络 LeNet 模型能够对 MNIST 数据集图像进行分类。MNIST 数据集包含灰度图像,但在 CHIFAR-10 数据集中,图像是彩色的并且包含不同的物体。所以我们最大的问题是,我们的 LeNet 模型是否能够对 CIFAR-10 数据集的图像进行分类。我们将复制上一篇的代码,即 CNN 的测试,并对图像变换、实现、训练、验证和代码的测试部分进行以下更改 注意:如果你是第一次来这里,那么你必须先了解我们之前的文章,才能有效地理解这一点。图像变换部分的更改在图像变换部分,我们将进行以下更改 步骤 1 在此,我们使用 CIFAR-10 数据集,所以我们的第一步是加载 CIFAR-10 数据集而不是 MNIST 数据集。我们通过以下方式更改训练数据集和验证数据集来加载 CIFAR-10 数据集 步骤 2 在下一步中,我们将更改我们的变换语句。我们知道 MNIST 图像的大小是 28 x 28 像素,但 CIFAR10 图像的大小是 32 x 32 像素。所以我们将更改 transform.compose() 方法的第一个参数 现在,如果我们绘制我们的 CIFAR-10 图像,它将给出以下输出  步骤 3 在 CIFAR10 图像中,我们知道图像被分成不同的类别。为了更好地理解和可视化,我们用它的类别指定每个图像。因此,我们声明一个类列表,在 im_convert () 方法之后,我们按顺序指定类,如下所示 步骤 4 标签代表这些类的有序数值表示,因此我们将使用每个相应的标签来索引我们的类列表,输出将是相应的类。我们将更改 set_title() 方法 它将提供以下输出  实现、训练和验证部分的更改我们的 Lenet 模型是为 MNIST 图像实现的。MNIST 图像是灰度图像,但我们必须为 CIFAR-10 数据集实现我们的模型,其中包含彩色图像。因此,我们必须在我们的代码中进行以下更改 步骤 1 以前,我们使用的是单通道灰度图像,现在我们使用传递到神经网络中的三通道彩色图像。因此,在第一个卷积层中,我们将设置 3 而不是 1,如下所示 步骤 2 现在,我们必须训练大量的参数。在 5 x 5 内核的卷积之后,图像变为 28 x 28,然后在下一个池化中,14 x 14 执行另一个相同大小内核的卷积。图像再次缩小 4 x 4 递减,变为 10 x 10。最后,通过另一个最大池化,然后馈入全连接网络的向量将是 5 x 5 x 50。 因此,我们必须将我们的第一个全连接层更改为 步骤 3 现在,我们还必须更改我们的输出的形状。为此,我们必须在 forward 函数中更改我们的 view 语句 现在,我们找到了总损失和验证损失以及准确率和验证准确率,并绘制出来,然后它将给我们以下输出   步骤 4 现在,我们将使用它来预测来自网络的图像,以简单地获得模型准确性的视觉角度。我们将使用以下图像:https://3c1703fe8d.site.internapcdn.net/newman/gfx/news/hires/2018/2-dog.jpg 当我们绘制这张图像时,它将显示为  步骤 5 在下一步中,我们将删除我们的 invert 和 convert 方法,因为这一次我们的图像将被转换为生物级别的格式,并且我们的网络是在彩色图像上训练的。我们将转换图像并绘制图像,如下所示 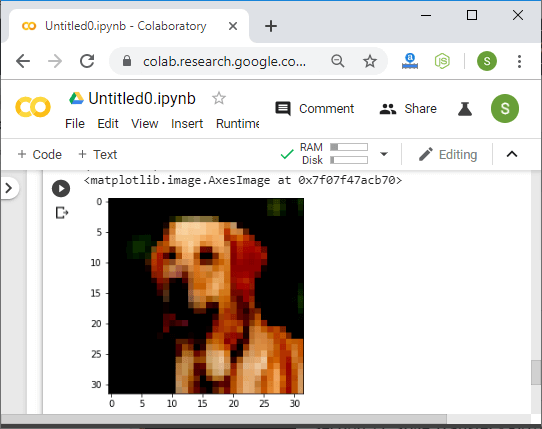 在变换后,我们获得了图像的更抽象的表示。它缩小到更小的 32 x 32 表示。 步骤 6 现在,我们对这张图像进行预测,因此我们将挤压图像并使用类来找到预测  测试部分的更改测试部分将与之前相同。将遵循与 CNN 相同的测试过程,但在彩色图像中,我们将使用类来预测每个验证图像,如下所示  它似乎可以准确地预测大多数图像。总的来说,我们的模型能够根据其训练的参数将其自身推广到新数据是非常好的。 完整代码下一篇超参数调整技术 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India

{kind=link}