流水线中的执行、阶段和吞吐量2025年03月17日 | 阅读 9 分钟 我们可以通过以下两种方式来提高 CPU 的性能
由于更快的电路成本很高,并且硬件的速度也是有限的。由于这些缺点,第二种选择对我们来说是好的。 流水线流水线可以将一种技术描述为在执行过程中重叠多个指令。流水线有五个阶段,所有这些阶段都相互连接,形成管道状结构。在流水线中,有两端,一端用于输入指令,另一端用于输出指令。由于流水线,指令的整体吞吐量得到提高。流水线系统的每个段都有输入寄存器,后跟组合电路。数据由寄存器保存,对该数据的操作由该组合电路执行。组合电路的结果将应用于下一段的输入寄存器。  流水线系统也像现代工厂中的装配线一样运作。例如:假设有一个汽车制造行业,其中设置了大量的装配线,并且在每个点上都有机器人手臂执行特定的任务。之后,汽车将被移到下一个手臂。 在流水线过程中, CPU 的硬件元件会以一种可以提高整体性能的方式进行排列。在流水线过程中,可以同时执行多个指令。 例如:这里,我们将通过一个真实生活的例子来学习流水线操作的概念。在这个例子中,我们将假设一个瓶装水厂。瓶子需要经过三个阶段。第一阶段是装瓶(I)。第二阶段是灌装水到瓶子(F)。第三阶段是密封瓶子(S)。现在我们将这些阶段称为第一阶段、第二阶段和第三阶段,以便于理解此示例。我们将假设每个阶段的操作需要 1 分钟。 假设我们有一个非流水线操作。在这里,第一阶段先将瓶子插入工厂。插入 1 分钟后,瓶子将进入第二阶段,在那里为其灌装水。此时,第一阶段没有任何操作。同样,当瓶子进入第三阶段时,在这种情况下,第二阶段和第三阶段都是空闲的。因此,在非流水线操作中制造 1 个瓶子的平均时间是 现在假设我们有一个流水线操作。在这里,当一个瓶子处于第二阶段时,我们可以同时将另一个瓶子装入第一阶段。同样,当瓶子处于第三阶段时,此时第一阶段和第二阶段各有一个瓶子。因此,在第三阶段结束时,我们每分钟都会得到一个新瓶子。因此,在流水线操作中制造 1 个瓶子的平均时间是 因此,通过流水线操作,可以提高系统的效率。 基本流水线设计
流水线处理器执行在流水线处理器中,我们可以使用时空图来可视化指令的执行顺序。例如:我们假设处理器包含 4 个阶段,并且我们需要执行 2 条指令。通过以下时空图,我们可以可视化执行顺序如下 现在重叠执行
总时间 = 8 个周期 重叠执行
总时间 = 5 个周期 流水线阶段在 RISC 处理器中,我们可以通过 5 个指令阶段来执行 RISC 指令集的所有指令。第一个阶段是指令获取,在此阶段从内存中获取指令。第二个阶段是指令解码,在此阶段解码指令并读取寄存器。第三个阶段是指令执行,在此阶段计算地址或执行操作。第四个阶段是内存访问阶段,在此阶段访问内存操作数。第五个阶段是写回阶段,在此阶段将结果写回寄存器。下面将详细解释 RISC 流水线的所有这 5 个阶段及其操作 第一阶段 阶段 1 是指令获取。在这里,从内存(I-Memory)读取指令。在此阶段,程序计数器用于包含内存的值。通过递增当前 PC,我们可以计算 NPC。通过将指令写入 PR 来更新流水线寄存器。指令获取阶段的过程如下  第二阶段 阶段 2 是指令解码阶段。在这里,解码指令,并为操作码位生成控制信号。在此阶段,从寄存器文件中读取源操作数。通过指定符,对寄存器文件进行索引。流水线寄存器会将操作数和立即数发送到下一阶段。它还将 NPC 和控制信号传递到下一阶段。指令解码器阶段的过程如下  阶段 3 阶段 3 是指令执行阶段。在此阶段执行 ALU(算术逻辑单元)操作。它需要两个操作数来执行 ALU 操作。第一个操作数用于包含寄存器的内容,第二个操作数用于包含立即数或寄存器。在此阶段,可以通过以下公式计算分支目标 流水线寄存器(PR)将更新 ALU 结果、分支目标、控制信号和目标。指令执行过程如下  阶段 4 阶段 4 是内存访问阶段。在这里,内存操作数能够读取和写入指令中存在的内存。流水线寄存器(PR)将更新来自执行的 ALU 结果、目标寄存器以及来自 D-Memory 的加载数据。内存访问过程如下  第五阶段 阶段 5 是写回阶段。在这里,将获取的值写回到指令中存在的寄存器。此阶段只需要一个写端口,该端口可用于将加载的数据写入寄存器文件,或将 ALU 的结果写入目标寄存器。 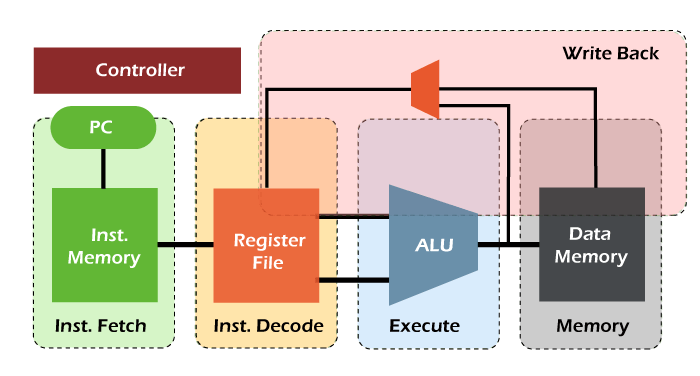 流水线处理器性能这里我们将一个段流水线表示为‘k’,时钟周期时间表示为‘Tp’。假设流水线处理器需要完成‘n’个任务。现在,第一条指令将在花费‘k’个周期后退出流水线。另一方面,‘n-1’条指令每条只需要‘1’个周期。这意味着‘n-1’条指令总共需要‘n-1’个周期。在流水线处理器中,当我们尝试执行‘n’条指令时,所需时间如下 ET pipeline = k + n -1 cycle
= (k + n -1) Tp
在非流水线处理器中,当我们进行相同的情况并尝试执行‘n’条指令时,所需时间如下 ET non-pipeline = n * k * Tp 因此,当我们在同一处理器上执行‘n’个任务时,流水线处理器相对于非流水线处理器的加速比(S)如下 S = Performance of pipeline processor / Performance of Non-pipelined processor 由于执行时间和过程性能成反比。因此,我们有以下关系 S = ET non-pipeline / ET pipeline S = [n * k * Tp] / [(k + n -1) * Tp] S = [n * k] / [k + n - 1] 如果‘n’个任务大于‘k’,即 n >> k,则将出现以下关系。 S = n * k / n S = k 这里 K 用来表示流水线中的阶段数。 Also, Efficiency = S / Smax 这里 S 用来表示最大加速比,Smax 表示最大加速比。 We know that Smax = k So, Efficiency = S / k 现在吞吐量可以这样描述 Throughput = Number of instruction / Total time to complete the instruction So throughput = n / (k + n + 1) * Tp 注意:对于理想的流水线处理器,每条指令的周期(CPI)为 1。流水线冲突流水线的性能受到各种因素的影响。以下是其中一些因素 时间变化 我们知道流水线不能为所有阶段花费相同的时间。当处理一些指令,而不同的指令需要不同的操作数并花费不同的处理时间时,会发生时间变化问题。 数据冒险 当多条指令并行执行,并且这些指令引用相同数据时,就会发生数据冒险问题。因此,我们应该注意,下一条指令不要尝试访问当前指令已访问过的数据。如果出现这种情况,将产生不正确的结果。 分支 在我们尝试获取和执行下一条指令之前,应该了解该指令。假设当前指令包含条件分支,并且该指令的结果将导致下一条指令。在这种情况下,只要当前指令正在执行,我们就无法知道下一条指令。 中断 由于中断,不受欢迎的指令将被插入指令流中。中断也会影响指令的执行。 数据依赖 当上一条指令的结果将导致下一条指令,但该结果尚未可用时,就会发生数据依赖情况。 流水线的优势
流水线的缺点
下一个主题流水线延迟和停顿的类型 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
