Pandas Dataframe.sample()2025年3月17日 | 阅读 3 分钟 Pandas 的 sample() 用于从 DataFrame 中随机选择行和列。 如果我们要从一个大型数据集构建模型,我们必须随机选择一个较小的数据样本,这可以通过 sample 函数完成。 语法参数
返回值它返回一个与调用者相同的类型的新对象,该对象包含从调用者对象随机采样的 n 个项目。 示例 1输出 data1 data2 data3 John 2 2 10 William 0 0 8 示例 2在本例中,我们取一个 csv 文件,并通过使用 sample 从 DataFrame 中提取随机行。 csv 文件名为 aa,其中包含以下数据集 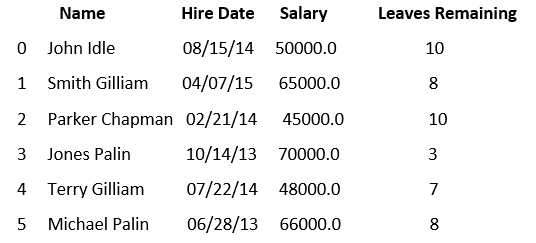 让我们编写一个代码,从上述数据集中提取随机行 输出 Name Hire Date Salary Leaves Remaining 2 Parker Chapman 02/21/14 45000.0 10 5 Michael Palin 06/28/13 66000.0 8 下一个主题DataFrame.shift() |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
