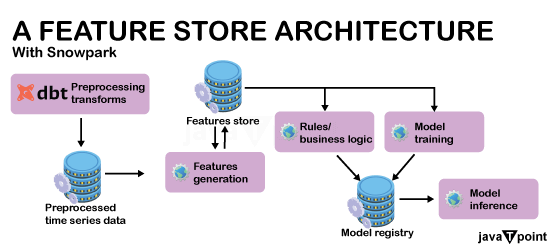
Snowflake 中的未来功能30 Jul 2025 | 13 分钟阅读 NVIDIA 合作及 AI 的最新动态峰会前夕,NVIDIA 和 Snowflake 宣布了旨在开发定制化 AI 应用的新合作。Snowflake 计划将 Snowflake Cortex AI 与 NVIDIA 的 AI Enterprise 平台相结合。 这种结合包括 Triton 推理服务器,它可以大规模部署和执行 AI 推理,以及 NVIDIA 的 NeMo Retriever,它将提供高性能的信息检索,用于构建 RAG(检索增强生成)应用。 NVIDIA NIM 推理微服务的预构建 AI 容器也将作为原生应用程序部署在 Snowflake 内的 Snowpark Container Services 中。此外,由于 Snowflake Arctic LLM 可作为 NVIDIA NIM 使用,Snowflake 的合作伙伴和客户将能够快速开始 AI 实验。 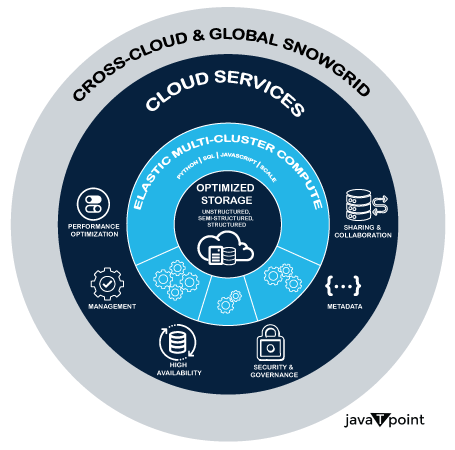 Snowflake Cortex AI 的更新生成式 AI 正在以极快的速度改变各行各业的组织。同样,在 Snowflake Summit 2024 上,Snowflake Cortex AI 也不乏引人注目的新功能。如果您还不熟悉 Snowflake Cortex AI,请参阅这篇博客了解其入门介绍。 以下是峰会上公布的一些即将推出的功能: Cortex Analyst:Cortex Analyst 是一款未来的产品,它允许业务用户在 Snowflake 上与他们的数据进行交互。它使用了 Meta 的 Llama 3 和 Mistral Large 模型进行开发。即将发布的 Snowflake Copilot(正式可用)允许技术用户将查询转化为 SQL。Cortex Analysts 将能够同时回答业务查询。 Cortex Search:Snowflake 负责此功能的所有搜索方面,包括数据摄取、嵌入、检索、重排序和生成。此功能的应用场景包括多文档综合和推理,以及“大海捞针”式的查找。 Cortex Fine-tuning:另一个重要功能是 Cortex Fine-Tuning,它提供了一个低代码或无代码的交互式界面,供用户针对特定用例进行模型微调。此功能将使组织和行业能够更好地定制模型以满足其独特的需求。  Snowflake AI & ML Studio:即将推出的新功能将允许所有经验水平的用户在 Snowflake 中测试 LLM,并在类似沙盒的环境中比较多个模型的结果。这些特性与已有的用于在 UI 中快速简便地执行异常检测、分类和预测的工具相一致。 Snowflake Cortex Guard:生成式 AI 存在风险,特别是可能产生破坏性和不安全的回答。作为回应,Snowflake 打算提供这个新工具,它将允许企业识别和消除此类信息。  开发工具和改进并非所有令人兴奋的新功能和更改都仅限于 AI。Snowflake 推出了许多将增强协作和开发的新功能。 Snowflake Notebooks:Snowflake Notebooks 目前处于公开预览阶段,它提供了一个笔记本界面,使数据团队能够在一个地方使用 Python 和 SQL 进行协作。此外,Snowflake Notebooks 也可以以计划方式使用。 Snowflake 命令行界面 (CLI):备受期待的 Snowflake CLI 功能允许数据和基础设施团队直接从命令行创建、管理和部署 Snowflake 对象和基础设施。 Snowflake Python API:随着 Snowflake Python API 的普遍可用,除了改进的 CLI 之外,团队很快将有另一种选择,可以使用 Python 来管理 Snowflake 资源和数据管道。 Snowpark Pandas API:此功能已发布公开预览。它允许熟悉 Pandas 和 Python 的数据工程师以分布式和可扩展的方式执行他们的 Pandas 代码。为了让客户能够利用熟悉的 Pandas 功能处理大型数据集,Snowflake 利用了开源的 Modin API。 Snowflake Trail:数据和基础设施团队可以利用 Snowflake Trail(一套新的可观测性功能)来增强其应用程序和数据管道的洞察力和警报。这些功能包括 Snowpark 分析、自动 Python DataFrame 跟踪、Python 代码剖析器、日志功能和无服务器警报。其中一些功能已在公开预览和私有预览中提供。 Snowpark Python 更新
创建 Python 存储过程本文介绍如何创建 Python 存储过程。您可以在存储过程中使用 Snowpark 库来查询、更新和处理 Snowflake 表。 概述使用 Snowflake 数据仓库作为计算框架,您可以创建和执行 Snowflake 内的数据管道,实现 Snowpark 存储过程。通过编写 Snowpark API for Python 的存储过程来创建数据管道。任务用于计划这些存储过程的执行。 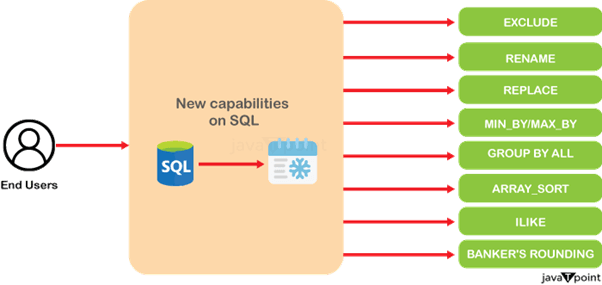 本地编写存储过程的要求
编写存储过程的 Python 代码您编写的 handler 代码将在调用存储过程时运行,并包含存储过程的逻辑。本节将介绍 handler 的设计。 您可以通过多种方式使用 handler 代码来构建存储过程:
局限性以下是 Snowpark 存储过程的限制:
准备编写您的已保存过程
编写过程或函数编写存储过程的方法或函数时,请记住以下几点:
 管理错误您可以使用标准的 Python 异常处理方法来识别过程中发生的错误。 Snowflake 会引发一个错误,其中包含方法内发生的任何未捕获异常的堆栈跟踪。当启用了未捕获异常的日志记录时,Snowflake 会在事件表中记录有关未捕获异常的信息。 为您的代码提供依赖项如果您的 handler 代码需要访问 handler 外部的代码(例如模块中的代码)或资源文件,您可以将这些依赖项上传到 stage,以便您的 handler 代码可以访问它们。有关使依赖项可用于您的代码的说明,请参阅为 Python 工作簿添加来自 Stage 的 Python 文件。
 数据访问示例以下示例展示了一个 Python 方法,该方法将给定数量的行从一个表复制到另一个表。该方法接受以下参数:
矢量化 Python UDTF 概述矢量化的 Python 用户定义表函数 (UDTF) 允许对行进行批量操作。
 使用矢量化 end_partition 方法的 UDTFUDTF 具有矢量化 end_partition 函数,可轻松实现按分区处理。这些方法将分区作为 pandas DataFrame 进行操作,并返回 pandas DataFrame、pandas Series 列表或 pandas Series 作为输出。这使得与使用 pandas 数组或 DataFrames 的库集成更加容易。 对以下任务应用矢量化 end_partition 方法:
 对以下任务应用矢量化 process 方法:
必需条件
使用矢量化 process 方法创建 UDTF。

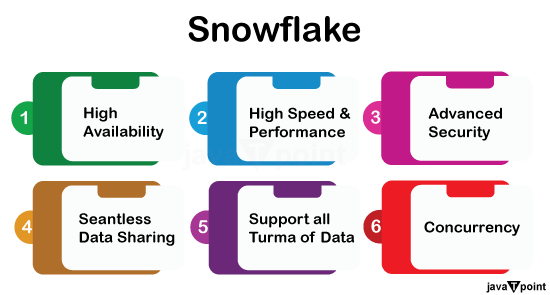
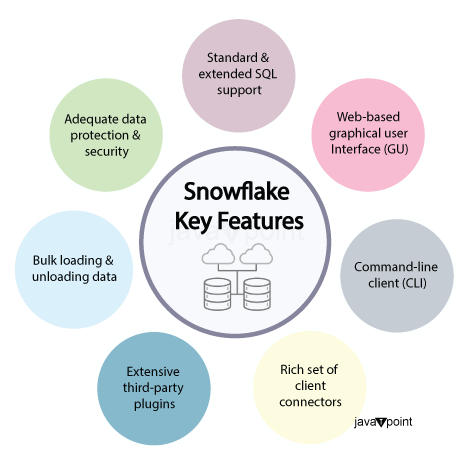
DevOpsDevOps:轻松部署和管理 Snowflake 对象和代码。 现在,EXECUTE IMMEDIATE FROM 命令已处于公开预览阶段,您可以直接从 Stage 上的文件(例如从 VS Code)运行 Snowflake Native App 或 SQL 脚本。 此功能使您能够有控制地管理和部署 Snowflake 对象和代码。例如,您可以运行一个已保存的脚本来设置所有帐户的默认 Snowflake 环境。 EXECUTE IMMEDIATE FROMEXECUTE IMMEDIATE FROM 在 Stage 中运行文件中的 SQL 语句。文件可能包含 Snowflake Scripting 块或 SQL 语句。SQL 语句必须在语法上有效。使用 EXECUTE IMMEDIATE FROM 命令从任何 Snowflake 会话运行文件中的语句。 此功能使您能够有控制地管理和部署 Snowflake 对象和代码。例如,您可以运行一个已保存的脚本来设置所有帐户的默认 Snowflake 环境。对于每个新帐户,配置脚本可能包含创建数据库、模式、角色和用户的语句。 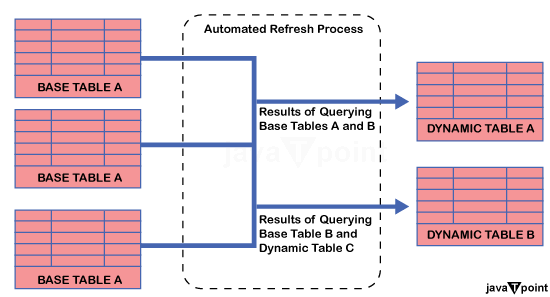 Snowflake 的主要特点是:1. 灵活性
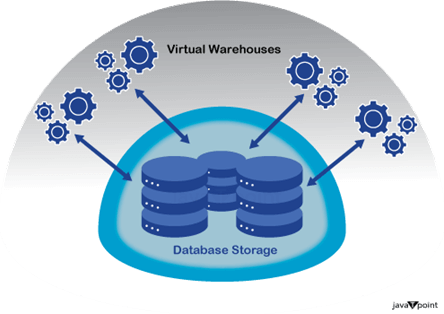
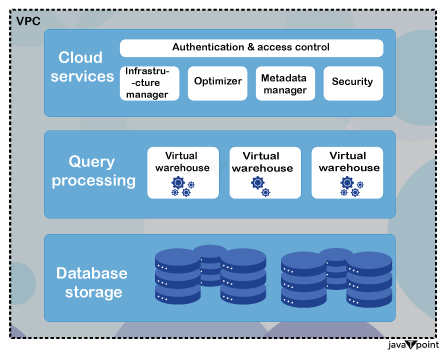
2. 计算和存储分离
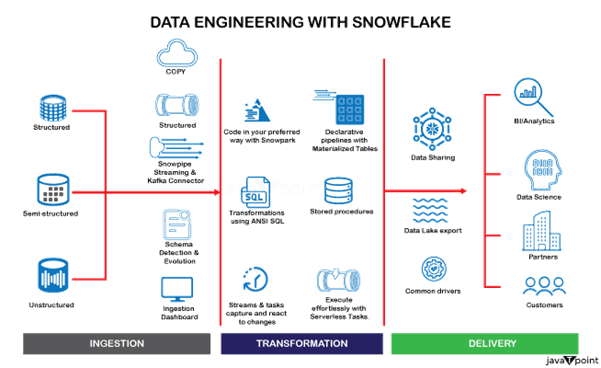
 作为云数据仓库平台,Snowflake 正在不断发展以适应现代数据环境的需求。基于云数据行业的趋势和最新进展,即使未来功能通常在 Snowflake Summit 或通过产品更新发布,以下是 Snowflake 可能关注的一些领域: 1. 增强的数据治理和安全功能
2. 增强的 AI/ML 能力
3. 对非结构化数据和复杂工作流的支持
4. 与数据湖和开源的增强集成
5. 边缘和物联网分析
6. 数据应用程序市场的扩展
 7. 对混合云和多云系统的改进支持
8. 加强对实时数据分析的关注
9. 自动化和 DataOps 功能
10. 高级协作工具
结论总而言之,我们可以得出结论,Snowflake 定位为能够满足数据驱动型企业不断增长的需求。即将推出的改进很可能会侧重于增强的 AI/ML 功能、与开源工具和数据湖的更深入集成、更强大的数据治理以及对非结构化数据的更多支持。此外,实时分析、边缘计算、自动化和多云兼容性预计将在很大程度上影响平台的发展轨迹。只要 Snowflake 不断创新,它就有望在云数据生态系统中占据主导地位,并使企业能够从其数据中提取更多价值。 下一主题 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
