Snowflake 数据验证2025年7月30日 | 阅读 14 分钟 在你的数据管道中,数据验证需要成为一个常驻居民,而不是仅仅一个过客。Snowflake 为数据管道增加了两个新且引人注目的功能——动态表以及告警和通知。借助 Snowflake 的动态表,你可以使用 SQL 语句、子查询、聚合、窗口函数和 Python 函数(包括 Snowpark)轻松构建可靠的数据管道。 这个强大的工具也可以用于数据验证,无论表中的数据是移动的还是静态的。让我们举一个例子来更好地解释这个想法。虽然 Snowflake 的快速入门指南有一个详尽的动态表快速入门指南,但我们将通过展示一个数据验证用例来提供预览。 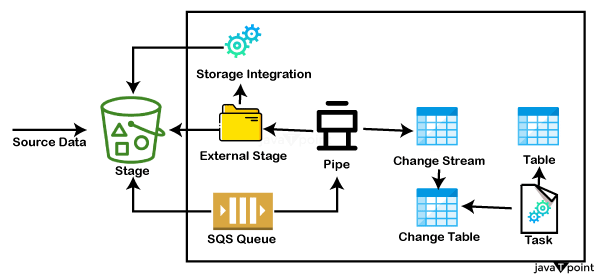 假设你是一家互联网零售商的数据工程师或数据治理开发人员。你的目标是确保业务团队能及时收到库存预警,以便他们能够补货低库存产品。你定期从一个事实表中生成一个详细的 SALESREPORT。此表记录了产品的详细信息和相应的销售数量。 同时,你的产品表包含了截至上次补货日期的重要库存信息。在生成我们的 SALESREPORT 事实表后,你将在每次运行时使用这两个表进行一些简单的 SQL 查询。 我们的主动方法是通过我们的数据收集来确定某个产品的库存是否低于 10%。让我们在 Snowflake 中一个新的“数据验证动态表” SQL 工作表中实现这一点。 现在让我们检查一下是否有任何产品的库存不足 你可以使用告警和通知来帮助你的产品采购和库存人员通过发送电子邮件告警来补充必要的商品。别忘了在下面的代码中更新仓库和电子邮件地址。 只有当新信息添加到动态数据库(低库存产品)时,这些通知才会激活。因此,在 Snowflake 中维护和管理实时数据的告警非常简单。 这些告警可以暂停、恢复和监控。 Snowflake 云数据仓库迁移从主要基于云的 Snowflake 事实数据仓库迁移到传统的 Netezza 信息数据仓库涉及几个步骤。数据验证是数据迁移项目成功的关键。在数据迁移的每个阶段以及端到端数据验证情况下的数据间隙,都可以利用 DataFlow 来验证数据。 步骤 1:从遗留数据仓库提取数据 数据通常在提取为 CSV 或 Parquet 格式后传输到 AWS S3 登陆区域。AWS 提供了几种将文件传输到 S3 的选项,具体取决于数据量。 在数据发送到 AWS S3 后,必须进行数据验证,以确保所有数据都已正确检索并传输到 AWS S3。这些测试通常是 AWS S3 登陆区域中的文件数据与遗留数据仓库中的表数据的逐一比较,因为在此步骤中转换不多。 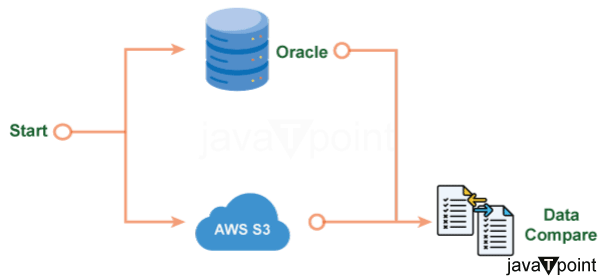
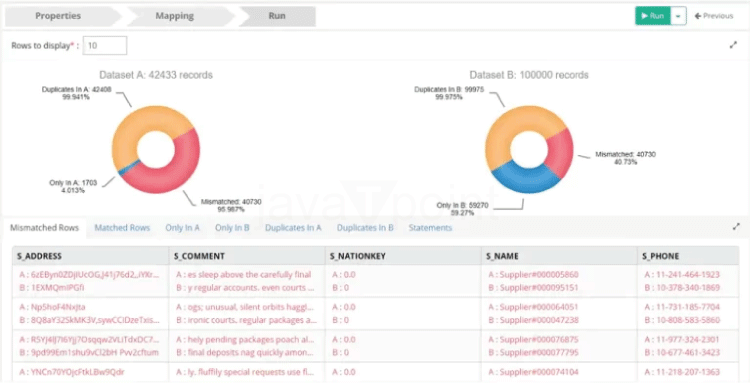 步骤 2:数据转换 测试用例图示例如右所示。可以通过 JDBC 组件读取遗留数据仓库。可以使用文件组件从 AWS S3 读取数据。最后,可以使用数据比较组件比较这两个数据集。下面是数据比较组件输出的示例。 在将数据加载到 Snowflake 之前,还可以使用数据整理来提高数据质量。为了在整理数据之前发现数据问题,对数据进行剖析并进行数据质量测试至关重要。这些任务可以通过 DataFlow 来完成。 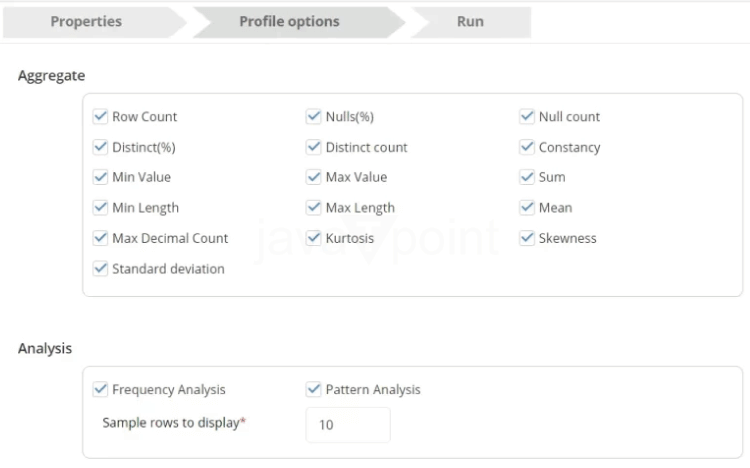
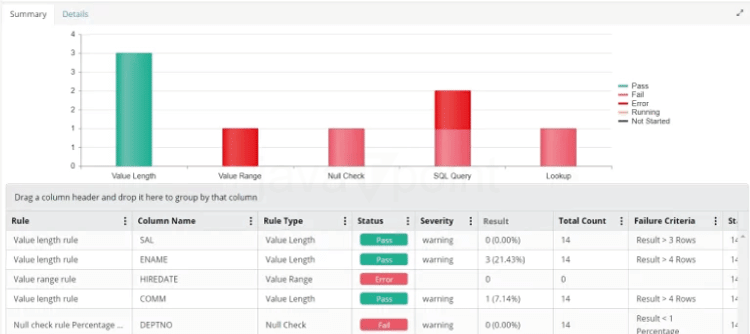 步骤 3:将数据复制到 Snowflake 假设 Snowflake 表已建立,复制数据到 Snowflake 是最后一步。使用 VALIDATE 函数来验证数据文件并查找任何错误。加载后,可以使用 DataFlow 来比较 Snowflake 和暂存区域(S3)文件之间的数据。
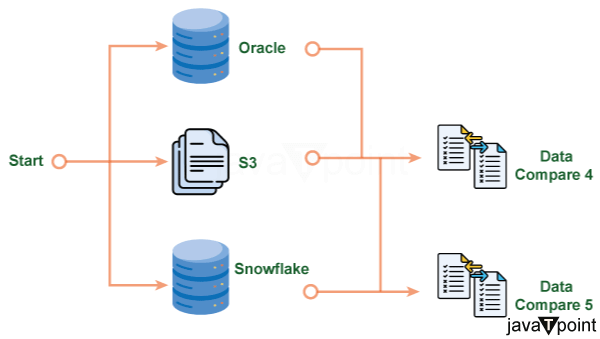 如右图所示,可以使用 DataFlow 在一个测试中完成端到端数据验证。可以使用单个 DataFlow 比较遗留数据仓库和 S3 的数据,以及遗留数据仓库和 Snowflake 的数据。 步骤 4:通过修改 Snowflake 来修改报表 完成这些调整后,必须进行严格的测试程序,将遗留数据仓库生成的报表与其对应的 Snowflake 生成的报表进行比较。
使用 Datagaps BI Validator(一种无代码 BI 测试解决方案)可以自动执行支持的 BI 工具的所有这些测试。有必要验证是否所有数据都已有效迁移。许多哈希函数——包括 Snowflake 中提供的函数(例如 Oracle 中的 ORA_HASH、Snowflake 中的 HASH 等)——被用来尝试验证迁移,但哈希输出不匹配。本教程提供了将数据迁移到 Snowflake 以验证数据的方法。 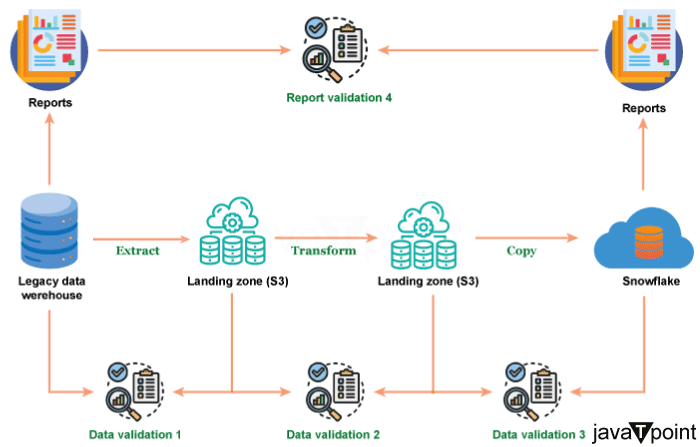 由于不同数据库中的方法和函数是专有的,使用不同的方法创建,并且产生的哈希结果与 Snowflake 中的哈希函数不同,因此无法使用其 HASH 等效函数来比较不同数据库中的数据完整性验证。迁移后验证来自不同数据库的数据完整性(表中的行)的解决方案是使用非数据库特定的函数,如 MD5 校验和,该函数将产生相同的哈希输出。 示例 如果行中没有 null 值 select seq,first_name,last_name, md5(concat(seq,first_name,last_name)) as hash from my stable;
如果行中有 null 列,则使用 coalesce Snowflake 数据质量验证有效利用数据需要信任和高质量的数据。借助 DataBuck,Snowflake 用户可以通过为每个数据资产分配信任分数来评估其数据质量。DataBuck 通过自动检测每个数据集独特的数据质量,将发现、调查和创建数据验证标准所需的工作量减少了 95%。 从手动模型转向基于信任的自动化策略。DataBuck 利用其机器学习功能,为每个数据资产(模式、表和列)确定客观的数据信任分数。数据驱动的信任将不再基于受欢迎程度。无需让人们对表或文件的质量进行主观评分。客观的数据信任分数被所有各方广泛理解。 工作原理
数据质量的维度级别结果摘要中显示了信任分数的偏差。它显示了用户可以信任数据的程度以及自上次两次研究以来质量和健康状况的变化。 有关更多详细信息,请双击找到的任何违规项用户可以放大维度,以查看哪些列受到数据资产级别的at影响。要查看列的特定维度,请单击其名称。有关更多信息,请单击列级别的维度名称。之后,用户可以确定特定的数据质量违规是应被忽略还是应报告进行进一步检查,无论是针对整个数据资产还是单个列。 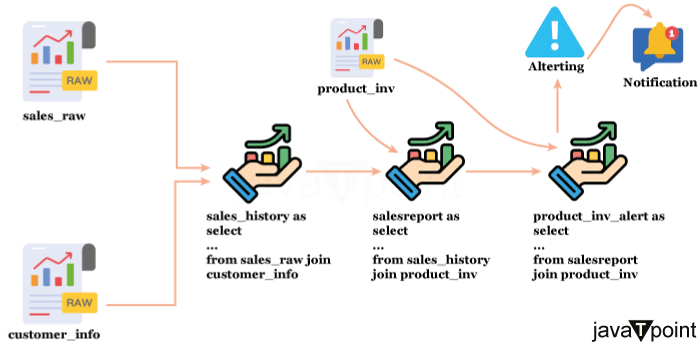 为了保证数据质量和完整性,可以在 Snowflake 数据模型中应用数据验证约束和检查。数据验证过程可防止不准确或不一致的数据进入数据库,并有助于强制执行业务标准。可以使用以下方法将限制和数据验证检查合并到 Snowflake 中 1. 检查限制Snowflake 支持检查约束,即在数据被添加到表或在表中修改之前必须评估为真的条件。可以对特定列或一组列应用检查约束。它们有助于根据预定标准实现数据验证规则。 示例 2. NOT NULL 约束使用 NOT NULL 约束来强制要求特定列必须具有非空值。这确保在数据插入期间始终提供必要的数据。 3. UNIQUE 限制UNIQUE 要求规定,指定列中的值在整个表中必须是唯一的。这有助于维护数据完整性并避免重复条目。 示例 4. 外键约束外键约束通过确保一个表中的数据与另一个表中的数据匹配来维护参照完整性。它们强制表之间的关系并防止孤立记录。 5. 正则表达式 (REGEXP)您可以使用正则表达式来验证和强制执行文本数据中的特定模式。 6. 用户定义函数 (UDFs)Snowflake 允许您设计 UDFs 来根据业务逻辑执行复杂的检查和个性化数据验证。 7. 物化视图预先聚合数据和根据预定义标准执行数据验证检查是物化视图的两种用途。它们在提高查询性能的同时保持数据质量。 通过将这些数据验证检查和约束合并到 Snowflake 数据模型中,您可以保证数据质量,维护数据完整性,并强制执行业务规则。通过采取这些预防措施,您可以阻止不准确的数据被添加,并提高数据的整体质量和可靠性。  确保导入到 Snowflake 或从 Snowflake 查询的数据是准确、一致并符合必要的数据完整性标准或业务规则,这就是 Snowflake 数据验证。以下是在 Snowflake 中验证数据的通用方法 1.模式验证
2. 数据完整性验证
3. 业务规则验证
4. 数据质量验证
5. ETL/ELT 流程验证
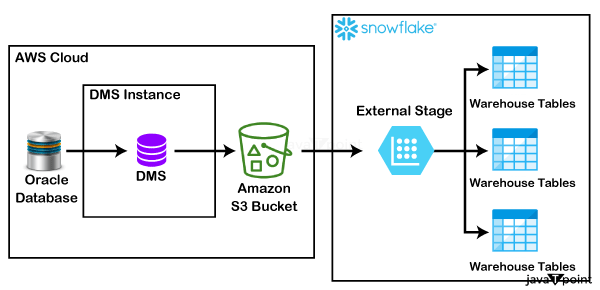 6. Snowflake 特有的验证工具
7. 性能验证
8. 性能和一致性评估
9. 自动化验证和测试
可以使用 Snowflake Tasks 和 Streams(一种调度和监控工具)来安排基于 SQL 的数据验证检查。 10. 错误处理和记录
Snowflake 数据验证工具
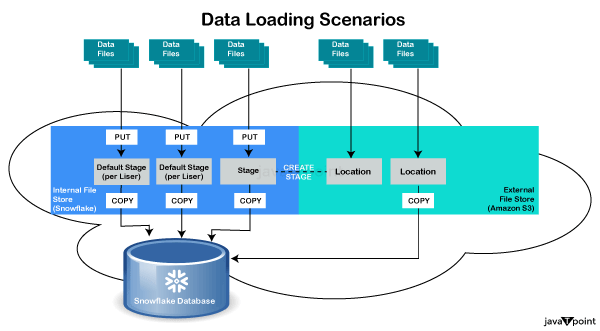 最佳实践
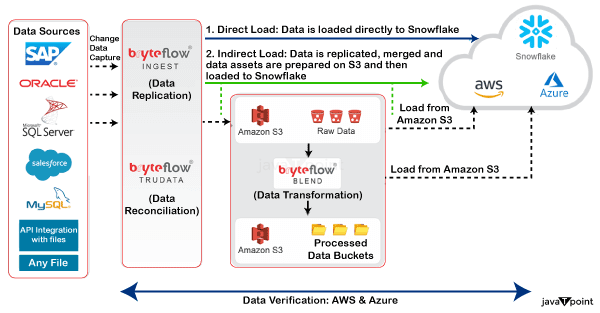 验证的示例 SQL 查询行数检查 目标行数 空值检查 范围检查 重复检查 数据转换验证 除了保护您免受潜在问题的侵害,定期监控和验证您的数据还可以帮助您对数据仓库提供的信息建立信任。使用最佳实践并将验证包含在您的 ETL/ELT 管道中将有助于确保您的公司数据始终是可靠的资产。 结论总而言之,我们可以得出结论,Snowflake 中的元数据验证是一项基本程序,用于保证数据的准确性、一致性和可靠性。通过实施强大的验证方法,从验证数据加载到执行质量检查,确保正确进行转换,以及自动化测试,您可以维护高数据完整性并促进更好的决策。利用 Talend、dbt 以及 Snowflake 的内置功能等技术可以进一步简化这些过程,这将提高验证效率并降低错误率。 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
