Snowflake 集成2025 年 1 月 29 日 | 阅读 15 分钟 引言Snowflake 是一款基于云的数据仓库解决方案,以其分离存储和计算的架构而闻名,可实现无缝的可扩展性和性能优化。Snowflake 专为支持各种数据工作负载而设计,提供强大的数据集成功能,是企业利用数据进行分析、机器学习和商业智能的理想平台。 本指南将探讨如何将 Snowflake 与 Talend 和 Informatica 等流行 ETL 工具以及 AWS、Azure 和 GCP 等主要云平台集成,并深入探讨实时数据集成和流处理。 理解 Snowflake 集成Snowflake 是一个基于云的数据平台,它提供了一种现代化的数据仓库方法。它允许组织在多个工作负载和用户之间存储、分析和共享数据。将 Snowflake 与 ETL 工具集成可以通过实现从各种数据源的无缝数据移动和转换来增强其功能。
Snowflake 集成架构Snowflake 的架构独特设计,旨在充分利用云计算的优势,提供高性能、可扩展性和易用性。理解其架构对于将 Snowflake 与各种数据源、ETL 工具和云平台有效集成至关重要。以下是 Snowflake 集成架构的详细说明。 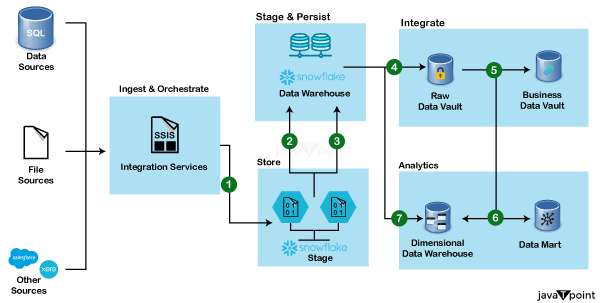 Snowflake 架构的核心组件多集群共享数据架构Snowflake 的架构建立在多集群共享数据模型之上,该模型将存储和计算分离。这种分离允许这两个资源的独立扩展,确保最佳性能和成本效益。 集中式存储:所有数据都以压缩的列式格式集中存储。此存储层是可扩展的,并且独立于计算资源进行管理。 计算集群(虚拟仓库):虚拟仓库负责查询处理,并且可以根据工作负载需求进行扩展或缩减。多个仓库可以无冲突地访问相同的数据,从而实现并发处理。 云服务层 云服务层是 Snowflake 架构的大脑。它处理各种服务,例如身份验证、元数据管理、查询解析和优化以及基础设施管理。 关键函数
Snowflake 提供各种连接器和 API,可促进与外部系统、ETL 工具和编程环境的集成。 关键集成
方法 COPY 命令:用于将数据从 AWS S3、Azure Blob Storage 和 Google Cloud Storage 等外部源批量加载。 Snowpipe:提供连续数据摄取,在数据到达阶段后自动加载数据。 外部表:这些表允许在不将数据加载到 Snowflake 的情况下查询外部存储的数据,这对于大型、不常访问的数据集很有用。 第三方工具:Snowflake 与众多第三方工具集成,用于数据集成、转换和可视化,从而增强其功能和可用性。 数据集成:Fivetran、Stitch 和 Segment 等工具可实现自动化数据管道的创建和管理。 数据转换:dbt(数据构建工具)允许直接在 Snowflake 中进行数据转换,利用其计算能力。 数据治理:Alation 和 Collibra 提供数据目录和治理功能,并与 Snowflake 无缝集成。 将 Snowflake 与 Talend 集成Talend 是一款开源 ETL 工具,提供一套完善的数据集成、数据质量和数据治理功能。它提供 Snowflake 的原生连接器,可轻松与平台集成并执行复杂的数据转换。  集成不同的数据源移动数据
API
企业数据
Web 数据
实现步骤
使用 Snowflake 批量加载:使用 Snowflake 的批量加载功能批量加载数据,从而最大限度地减少加载时间和提高性能。 实现错误处理:在 Talend 作业中纳入错误处理机制,以处理异常并确保 ETL 过程中的数据完整性。 将 Snowflake 与 Informatica 集成Informatica 是一款领先的数据集成工具,以其可扩展性、可靠性和全面的功能集而闻名。它提供 Snowflake 的原生连接器,可与该平台实现无缝集成,用于数据移动和转换。  实现步骤
从本地数据库摄取数据
与云平台的数据集成Snowflake,领先的云数据平台,与 Amazon Web Services (AWS)、Microsoft Azure 和 Google Cloud Platform (GCP) 等主要云平台无缝集成。此集成使组织能够利用这些云平台的扩展性、可靠性和高级服务,以及 Snowflake 强大的数据仓库和分析功能。在本指南中,我们将探讨如何将 Snowflake 与 AWS、Azure 和 GCP 集成,以实现高效的数据集成和管理。 将 Snowflake 与 Amazon Web Services (AWS) 集成Amazon Web Services (AWS) 是一个全面的云计算平台,提供广泛的计算、存储和分析服务。将 Snowflake 与 AWS 集成使组织能够利用 AWS 强大的基础设施和服务进行数据存储、处理和分析。 集成功能
实现步骤
将 Snowflake 与 Microsoft Azure 集成Microsoft Azure 是一个分布式计算平台,提供广泛的服务,用于应用程序开发、数据存储和分析。将 Snowflake 与 Azure 集成使组织能够利用 Azure 的高级数据服务以及 Snowflake 的可扩展数据仓库功能。  Azure Blob Storage:Snowflake 可以直接与 Azure Blob Storage 进行数据暂存和加载。组织可以将数据存储在 Azure Blob Storage 中并将其加载到 Snowflake 进行分析,从而利用 Azure 可扩展且持久的对象存储服务。 Azure Data Factory (ADF):Azure Data Factory 是一项基于云的 ETL 服务,可以协调和自动化从各种源到 Snowflake 的数据移动和转换。ADF 提供 Snowflake 的内置连接器,简化了数据集成过程。 Azure Functions:Azure Functions 可用于创建与 Snowflake 应用程序交互的无服务器应用程序。这支持实时数据处理、事件驱动架构以及 Snowflake 与其他 Azure 服务的集成。 Power BI 集成:对于分析和报告,Power BI 可以连接到 Snowflake 以提供实时洞察和仪表板。此集成允许用户利用 Snowflake 的数据进行交互式报告和分析。 实现步骤 设置 Azure Blob Storage:配置 Azure Blob Storage 用于数据暂存和加载。确保 Snowflake 拥有访问存储帐户和容器的必要权限。 配置 Azure Data Factory 管道:使用 Azure Data Factory 创建移动和转换数据的管道。定义源和目标连接、转换逻辑,并安排管道以在指定的时间间隔或响应事件时运行。 实现 Azure Functions:开发 Azure Functions 以实时处理数据。基于事件触发 Azure Functions 或安排它们在特定时间运行以自动化数据工作流并将 Snowflake 与其他 Azure 服务集成。 将 Power BI 连接到 Snowflake:使用 Power BI 的原生连接器建立与 Snowflake 的连接。创建利用 Snowflake 数据进行实时分析和可视化的交互式报告和仪表板。 Google Cloud Platform (GCP) 是由 Google 提供的一套分布式计算服务,包括数据存储、分析、机器学习等。将 Snowflake 与 GCP 集成使组织能够利用 GCP 的高级数据服务以及 Snowflake 的可扩展数据仓库功能。  Google Cloud Storage (GCS):Snowflake 可以与 Google Cloud Storage 进行数据暂存和加载。组织可以将数据存储在 GCS 中并将其加载到 Snowflake 进行分析,从而利用 GCS 的可扩展性、持久性和成本效益。 Google Dataflow:Dataflow 是一项完全托管的流和批处理服务,可在数据加载到 Snowflake 之前对其进行处理。它提供了一种灵活有效的方法来处理大量数据并执行复杂转换。 BigQuery 集成:Snowflake 可以与 Google 完全托管的数据仓库 BigQuery 集成,使组织能够利用这两个平台各自的优势。此集成支持跨平台数据分析和共享。 Google Pub/Sub:Google Pub/Sub 可用于将实时数据流式传输到 Snowflake,从而实现低延迟数据集成。这对于需要实时数据处理和分析的应用程序非常理想。 实现步骤 配置 Google Cloud Storage:设置 Google Cloud Storage 存储桶用于数据暂存和加载。确保 Snowflake 拥有访问存储桶和对象的必要权限。 设置 Google Dataflow 作业:创建 Dataflow 作业以在数据加载到 Snowflake 之前对其进行处理。在 Dataflow 中定义处理逻辑、转换和数据流,并安排作业以在指定时间间隔或根据事件运行。 利用 Google Pub/Sub:设置 Pub/Sub 主题以将实时数据流式传输到 Snowflake。配置 Snowflake 从 Pub/Sub 主题消耗数据并实时处理,以供即时使用。 将 Snowflake 与 BigQuery 集成:使用 Snowflake 的集成功能与 BigQuery 连接。配置必要的连接器和数据共享逻辑,以实现 Snowflake 和 BigQuery 之间的跨平台数据分析和共享。 实时数据集成和流数据对于旨在获得即时洞察并及时做出数据驱动决策的组织来说,实时数据集成和流处理变得越来越重要。
及时洞察:实时集成使组织能够根据最新数据快速做出决策,提高响应能力和敏捷性。 改善客户体验:实时数据允许即时响应客户操作,提高满意度和参与度。 运营效率:持续的数据处理有助于及时检测和解决问题,确保运营顺畅。 挑战 数据量和速度:以高速度管理大量数据需要强大的基础设施和优化的处理。 延迟:确保数据处理和集成中的低延迟对于实时应用程序至关重要。 复杂性:实时集成设置可能很复杂,需要专门的技能和工具。 实时集成工具和技术 Apache Kafka Kafka 是一个分布式事件流平台,能够处理高吞吐量和低延迟的数据流。它可以用于实时将数据流式传输到 Snowflake,从而实现即时数据处理和分析。 AWS Kinesis Kinesis 是 AWS 提供的实时数据流服务。它与 Snowflake 集成,可实现流数据的摄取,使组织能够实时处理和分析到达的数据。 Apache Spark 结构化流 Spark Structured Streaming 是一个多功能且容错的流处理引擎。它可以处理数据流并将结果写入 Snowflake,支持实时分析和数据处理。 Snowpipe Snowpipe 是 Snowflake 的连续数据摄取服务。它在数据到达暂存区后立即自动加载数据,并确保低延迟数据集成,非常适合实时应用程序。 变更数据捕获 (CDC) 变更数据捕获会捕获数据源中的更改,并实时将其应用于目标数据库。可以使用 Debezium 等工具实现与 Snowflake 的 CDC,确保 Snowflake 始终拥有最新数据。 案例研究案例研究 1:电子商务分析 一家电子商务公司使用 Kafka 将其网站的点击流数据流式传输到 Snowflake。此设置允许实时分析客户行为和偏好,使公司能够立即个性化用户体验并优化营销策略。 案例研究 2:金融交易 一家金融服务公司利用 AWS Kinesis 将交易数据流式传输到 Snowflake。这种实时集成有助于在几秒钟内检测欺诈活动,从而降低财务风险并加强安全措施。 设计可扩展性:确保您的架构能够随着组织的增长处理不断增加的数据量。使用可扩展的工具和服务来满足不断增长的需求。 优化低延迟:专注于在数据处理和集成的每个阶段减少延迟。这包括优化数据管道,最大限度地减少数据传输时间,并使用高效的处理算法。 监控和维护:持续监控您的实时集成管道,以及时检测和解决问题。使用监控工具跟踪性能并识别瓶颈。 利用云服务:利用云提供商的托管服务来简化实时数据集成和管理的实现。这些服务通常提供内置的可扩展性、安全性和可靠性功能。 优点和缺点
安全与合规
性能优化自动聚类:Snowflake 自动管理数据聚类,无需手动干预即可优化查询性能。 结果缓存:Snowflake 缓存查询结果,允许后续查询立即返回结果,前提是底层数据未更改。 数据压缩:Snowflake 以高度压缩的列式格式存储数据,降低存储成本并提高查询性能。 监控和管理
理解 Snowflake 的架构和集成机制,使组织能够充分发挥其全部能力,确保高效有效的数据管理、处理和分析。 下一主题Snowflake 实时数据处理 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
