Snowflake 微分区2025年8月1日 | 阅读 6 分钟 什么是微分区?Snowflake 表会自动将所有数据分区到称为微分区的连续存储单元中。在表中,行组按列排列并映射到不同的微分区。由于其大小和结构,非常大的表(可能包含数百万甚至数亿个微分区)可以被高度细粒度地剪枝。 Snowflake 保存了每个微分区中行的所有元数据,包括
 微分区优势使用 Snowflake 的表数据分区方法具有以下优势:
自动聚类剪枝查询在查询运行时,Snowflake 维护的微分区元数据可以实现微分区中列(包括包含半结构化数据的列)的精确剪枝。例如,假设一个包含日期和小时列的大型表存储了一年的历史数据。 这种程度的剪枝使得范围内的查询(也称为“切片”)可以精细到一小时或更短,对于时间序列数据可能实现亚秒级的响应速度。 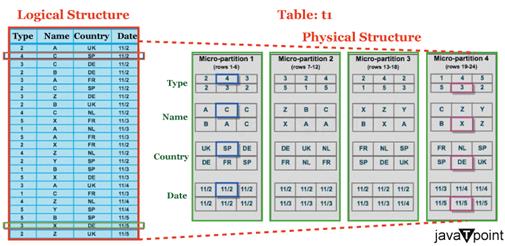 并非所有谓词语句都可以进行剪枝。例如,即使子查询产生一个常量,Snowflake 也不会根据带有子查询的谓词来剪枝微分区。 什么是数据聚类?表中的数据通常根据自然维度进行组织,例如日期和/或地理区域。由于部分或完全排序的表数据会影响查询性能,尤其是在非常大的表上,“聚类”是查询的一个重要组成部分。 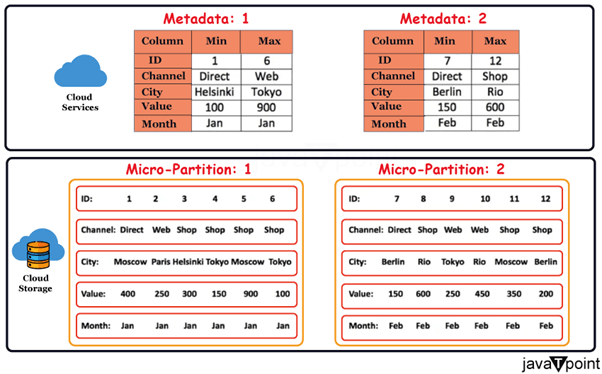 Snowflake 在微分区中使用的数据聚类在此图表中仅在小范围内概念性地表示。一个普通的 Snowflake 表可能包含数十个甚至数百万个微分区。 查询性能微分区对于提高 Snowflake 的查询性能至关重要。当您运行查询时,Snowflake 可以分析该查询,并使用查询过滤器来确定哪些微分区包含相关数据。通过避免读取不相关的微分区,Snowflake 的查询优化器会大大减少查询运行时需要扫描的数据量。 自动数据优化Snowflake 会自动对微分区应用数据压缩和优化方法。数据在进入 Snowflake 时以混合列式格式存储,从而实现高效的列级压缩。 可扩展性和并发性得益于微分区,Snowflake 可以有效管理多个并发查询并在需要时水平扩展。Snowflake 可以通过同时处理不同的微分区来处理多个查询。Snowflake 可以通过其并行性将查询工作分配给多个计算资源,从而加快查询执行速度并最大限度地利用资源。 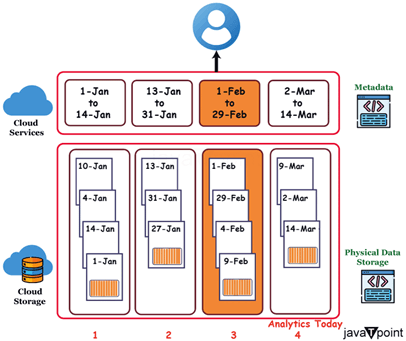 想象一下,几个人同时在一个整理有序的房间里寻找不同的东西。如果您将任务分配给几个人,您可以更快、更有效地完成任务。与此类似,Snowflake 由于能够同时处理多个微分区,因此可以处理繁重的工作负载并水平扩展以适应不断增长的需求。 保持最佳尺寸微分区不应过大或过小。过小的微分区可能会导致过多的元数据开销。想象一下,就像一堆小书架。处理和标记每个盒子可能效率低下且耗费资源。 通过明确定义聚类键,用户可以控制 Snowflake 如何生成微分区。 Snowflake 聚类聚类是 Snowflake 的一种方法,通过组织和存储表中的数据来提高查询性能。它涉及将一个或多个具有相似值的列物理地组合在一起。 聚类的优势:更好的查询性能在 Snowflake 中,聚类表意味着其内容被物理地组织起来,以将相似的值分组。这种组织方式提供了以下直接影响查询性能的优势:
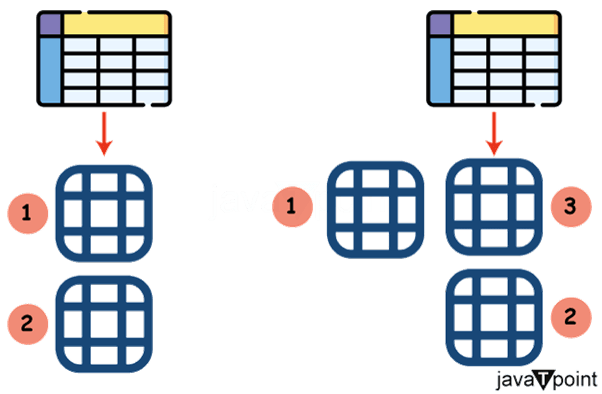 减少存储空间:通过提供以下优势,聚类除了提高查询性能外,还有助于优化存储使用。
Snowflake 一旦将相同的值保存在一个微分区内,而不是重复存储。这种高效的存储利用也有助于降低总存储成本。 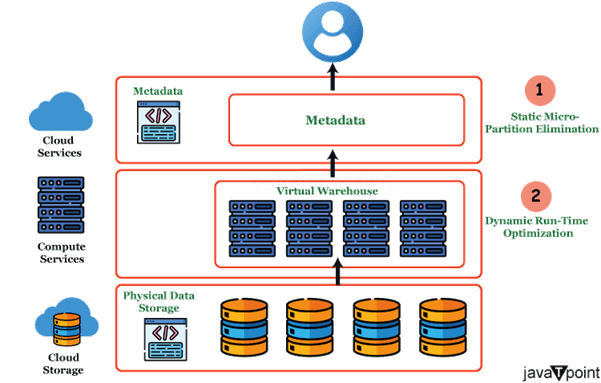 选择聚类的列在选择要用于聚类的列时,选择经常在过滤或搜索查询中使用的列至关重要。目标是将经常一起检索的相关值分组。例如,如果您经常使用“产品”列查找销售信息,则按“产品”列对表进行分组会很有用。 在构建聚类键时,应考虑以下事项:
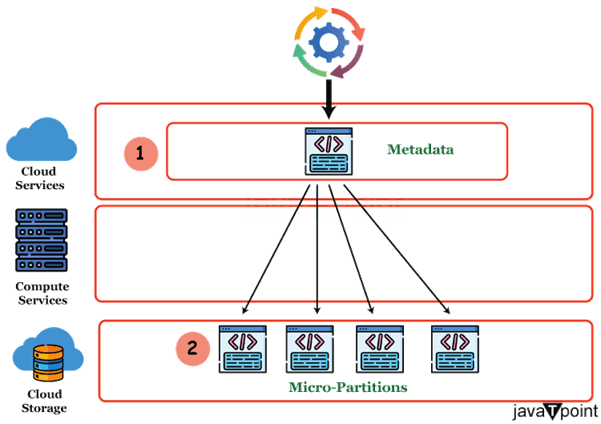 在加载数据时,应考虑以下事项:
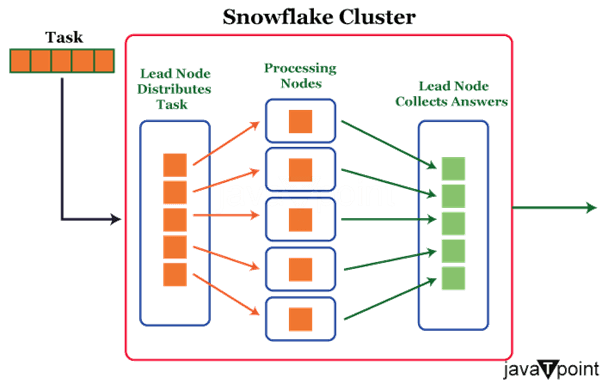 在处理数据修改时,应考虑以下事项:
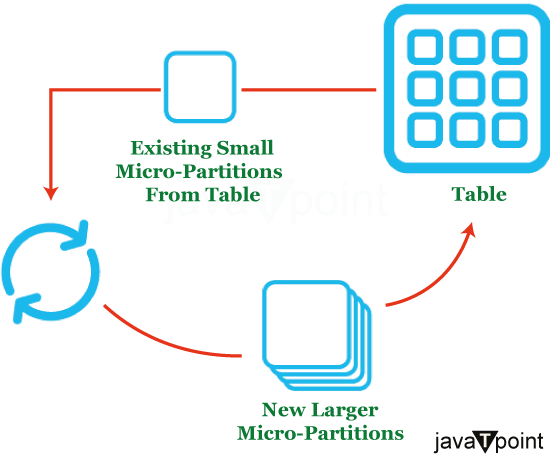
注意:对于更新较少表,初始微分区将具有更长的生命周期。重新聚类可能有助于经常更新的表。结论总之,我们可以得出结论,聚类和微分区是两种关键的 Snowflake 功能,可显著提高可扩展性和性能。微分区是数据存储的基本单元,它提供了更好的查询性能、自动数据优化以及更高的可扩展性和并发性等优势。 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
