Snowflake 列式数据库设计,面向实时分析2025年8月2日 | 阅读 10 分钟 什么是列式数据库?数据库管理系统 (DBMS),将数据存储在磁盘上的列中,称为列式数据库,有时也称为面向列的数据库。这种存储方式可以更快地搜索数据分析,而数据分析通常涉及对表列进行过滤和聚合。 将列式数据库与行式 数据库 进行对比,行式数据库将一行中的所有内容一起存储在磁盘上。这些数据库设计用于事务性、单一实体查找,而不是跨多个对象的分析。对于通常扫描或聚合大量数据集但只需要少数几列的分析查询,列式数据库尤其有用。 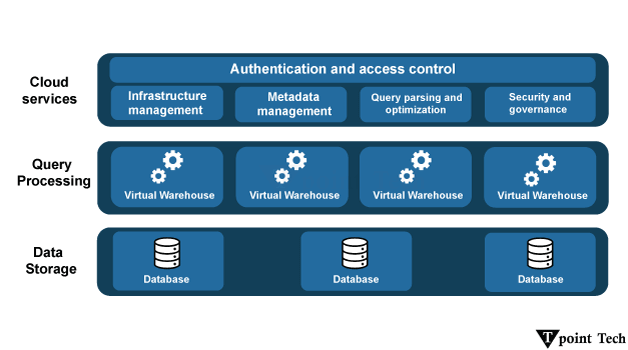 由于只需从存储中读取所需的列,因此 I/O 成本和时间得以降低,这使得它在分析应用程序中相对于传统的基于行的数据库具有优势。列式数据库为各种用例提供了更快的洞察并更好地利用系统资源。 对于数据分析,列式数据库非常出色。与行式数据库相比,它们处理的数据量更少,扫描的行数也更少。除了其数据存储能力外,列式数据库还提供了许多对时间序列数据或实时分析非常有益的特性,包括:
对于实时分析,请使用列式数据库。当需要高写入吞吐量和低延迟来处理复杂、分析性查询时,列式数据库在实时分析中通常表现出色。在事件驱动架构或事件溯源技术中,通过收集长时间戳事件的历史记录来维护状态,而不是在表中执行更新或替换。 最终,这都归结为基本物理原理。列式数据库的存储方式与行式数据库不同,大多数数据库都从磁盘上保存和检索数据。当您希望轻松访问列中的数据,同时又不牺牲使事务性、行式数据库有价值的某些优势时,分析型列式数据库具有明显优势。 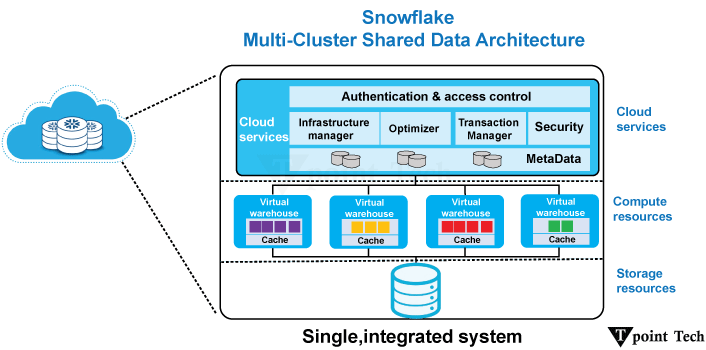 何时最好避免使用列式数据库?如果您希望保留事务性、标准数据库的优势,并且不打算进行复杂的分析,则应避免使用列数据库。
有哪些类型的数据库是列式的?以下是列式数据库的典型示例:
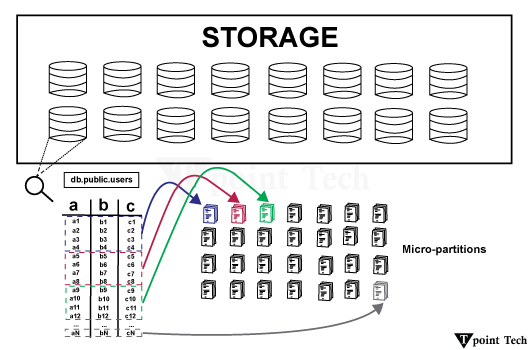
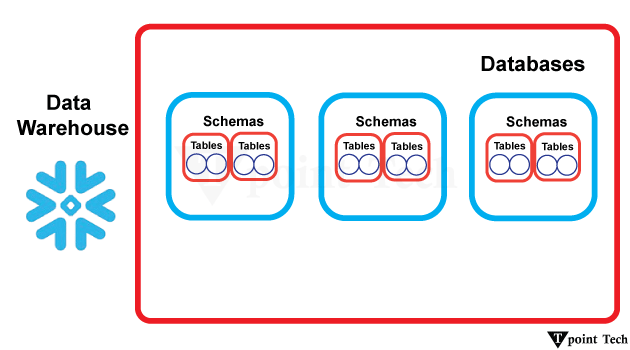
您可以在下方找到更多关于各种列式数据库的列表,包括专有和开源选项(以及托管或无服务器版本)。 *从技术上讲,这些被归类为“列族”数据库。为了减少读取时需要查询的列数,它们会将相关的列聚合到“族”中,而不是根据每个记录的主键按行存储数据。虽然它们不正式归类为列式数据库,但它们确实提供了一些列式数据库的优势。 哪个列式数据库最好?答案显而易见:这取决于。您的目标、用例和财务限制都将影响您对列式数据库的决策。Amazon Redshift、BigQuery 和 Snowflake 等云数据仓库是流行、强大且通常比其他解决方案更昂贵的。它们并非针对实时分析进行了优化,但它们在 商业智能 (BI) 方面表现出色。  ClickHouse、Apache Pinot 和 Apache Druid 等开源列式数据库虽然强大、灵活且(理论上)“免费”,但设置和管理可能非常耗时。如果您想利用列式存储的性能优势而不必担心基础设施,那么像 Tinybird(ClickHouse)或 DataStax(Cassandra)这样的开源列式数据库的托管版本可能是一个可行的选择。 Snowflake 数据库的结构是什么?除了其他列中的数据之外,此结构将每列中的所有数据保存在一起。这种独特的数据布局使得检索特定列的速度更快,并实现了有效的数据压缩。
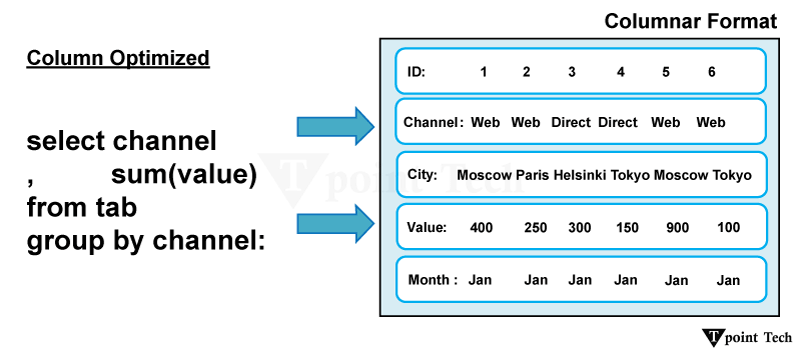
Snowflake 的列式格式对数据检索有何影响?Snowflake 的列式格式大大加快了数据检索速度。在运行查询时,只会访问和扫描相关的数据列,而不是整行。其结果是数据检索速度更快,这在处理大数据集时尤其有利。
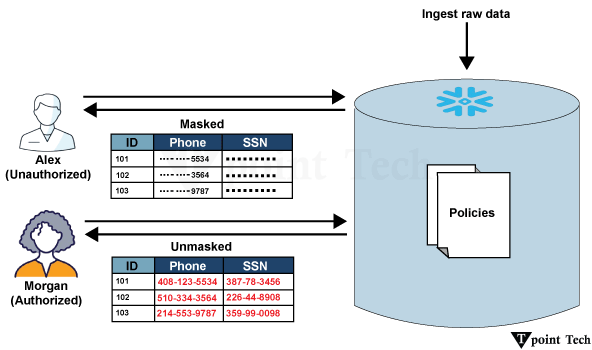
Snowflake 中反规范化的重要性反规范化是指有意在数据模型中添加冗余。复制数据似乎有悖常理,但对于某些分析需求,有意在 Snowflake 中进行反规范化可以大大提高查询速度。原因如下:
 优点
列式存储:革新性能Snowflake 的列式存储架构是数据建模的一个主要决定因素。与传统的基于行的 RDBMS 不同,Snowflake 是按列存储数据的。这种方法可以为分析工作负载带来显著的性能提升。
 列式存储与数据建模保持一致在为 Snowflake 进行数据建模时,请考虑您的数据模型如何适应列式存储架构。
RDBMS 与 Snowflake:数据建模差异Snowflake 的列式存储架构与传统的基于行的 RDBMS 不同。这种区别会影响数据建模。
说明RDBMS 方法优先考虑数据完整性,要求规范化。虽然这消除了冗余,但如果复杂查询需要连接 Orders 和 Customers 表,可能会影响性能。 通过将部分客户数据反规范化到 Sales 数据库,Snowflake 方法会故意添加冗余。对于一些按客户和日期(使用聚类键)检查销售数据的查询,这使得 Snowflake 能够利用其列式存储并避免联接。 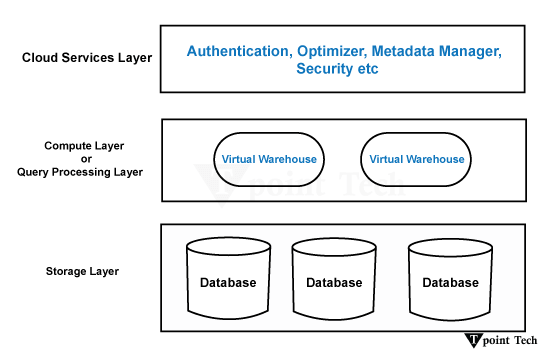 尽管这是一个简单的例子,但它说明了主要区别:
 列数据库是一种 数据库管理系统 (DBMS),它以列格式存储和排列数据,而不是像关系型数据库那样采用传统的面向行的格式。根据行,数据被加载到列中并存储在列数据库中。 使用列存储格式有许多优点,例如: 压缩:列数据库可以比行式数据库获得更高的压缩率。由于数据类型和值相似,列存储通常在列内显示出更高的数据冗余,从而可以实现更有效的压缩算法。
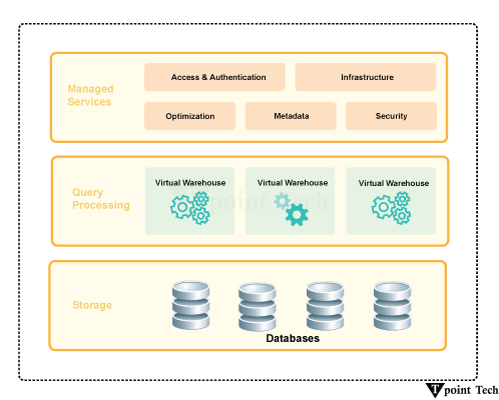 这些调整可以进一步降低存储需求并提高查询性能。在分析和数据仓库环境中,列式数据库通常被用于这些环境,其中重点是处理复杂查询、聚合和分析大型数据集。它们在数据量大且读密集型工作负载的情况下尤其有效。Google BigQuery、Apache Parquet、Apache ORC 和 Snowflake 是一些列式数据库的示例。 Snowflake 是一款基于云的列式数据库,专为高性能分析而设计。它采用分离计算、存储和服务的分离混合架构,以优化可伸缩性、并发性和效率。 1. Snowflake 的列式存储Snowflake 以列式格式存储数据,这意味着:
 2. Snowflake 的架构Snowflake 具有多集群共享数据架构,其中:
3. Snowflake 列式设计的最佳实践为了最大化成本和性能:
4. 针对列式存储优化 Snowflake 查询
在行式数据库中,数据以行的形式保存和检索,其中行的所有属性(列)都一起存储。这是传统关系型数据库(如 MySQL 或 Oracle)中的常见数据架构。另一方面,列式数据库独立存储每一列,并将给定属性的所有值存储在一起。这意味着单个列的值会顺序存储在内存或磁盘上。 结论Snowflake 凭借其列式存储设计,成为现代数据仓库和分析的强大、可伸缩且价格合理的解决方案。通过按列存储数据,Snowflake 优化了并行处理、查询性能和压缩。 借助 Snowflake 的分离式存储和计算方法,企业可以按需扩展,从而在无需手动调整的情况下确保经济高效的性能。聚类键、结果缓存和自动数据修剪等功能进一步提高了效率。 下一主题 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
