Snowflake Cortex LLM 功能2025年7月30日 | 阅读 10 分钟 Snowflake Cortex LLM 函数借助 Snowflake Cortex,您可以快速访问市场上顶尖的大型语言模型(LLM),包括 Snowflake Arctic。Arctic 是 Snowflake 创建的、面向企业的开源模型,由 Mistral、Reka、Meta 和 Google 的研究人员训练而成。 使用这些 LLM 无需任何准备,因为它们全部由 Snowflake 托管和管理。您的数据保留在 Snowflake 中,因此您可以继续获得所期望的性能、可扩展性和治理能力。 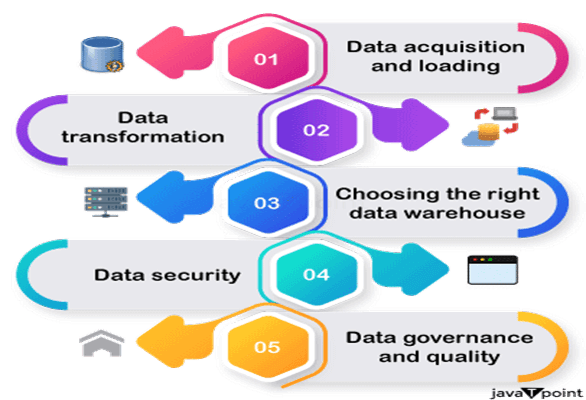 可用功能Snowflake Cortex 的功能可作为 Python 和 SQL 函数使用。Cortex LLM 函数可分为以下几类:
名为 COMPLETE 的通用函数能够执行用户指定的各种任务,包括基于方面的情感分类、生成合成数据和创建个性化摘要。在 COMPLETE 函数中,Cortex Guard 是一种安全参数,可用于过滤掉语言模型可能产生的危险回复。此功能也可应用于您的精调模型。 特定任务函数特定任务函数的设计和维护目的是为了自动化无需自定义的重复性操作,例如简短摘要和快速翻译。 CLASSIFY_TEXT:根据提示将文本分类到预定义的类别中。 EXTRACT_ANSWER:在给出问题和数据的情况下,如果能在非结构化数据中找到答案,则返回该答案。 SENTIMENT:提供一个介于 -1 到 1 之间的情感分数,表示文本识别出的积极或消极情感。 SUMMARISE:提供所提供文本的概要。 TRANSLATE:将提供的文本翻译成任何其他受支持的语言。 EMBED_TEXT_768:返回一个 768 维度的向量嵌入,该嵌入代表给定的文本片段。 EMBED_TEXT_1024:返回一个 1024 维度的向量嵌入,该嵌入代表给定的文本片段。 助手角色助手函数是为了最小化执行其他 LLM 函数时发生错误的几率而设计的,它们都有特定的用途。例如,它们可以计算输入提示中的 token 数量,并确保调用不超过模型限制。 基本权限账户中的所有用户现在都可以使用 Snowflake Cortex LLM 功能,因为所有用户和角色都会自动分配 PUBLIC 角色。如果您不希望所有用户都拥有此权限,则可以向特定角色授予访问权限,并撤销对 PUBLIC 角色的访问权限。 成本考虑
 选择模型通过选择适合您工作内容数量和复杂性的模型,可以获得每积分的最佳性能。以下是对可用模型进行的简要概述。 大型模型如果您不确定从何处开始,可以先尝试功能最强大的模型,以便建立一个基准,用于与其他模型进行比较。Snowflake Cortex 提供的最强大的模型是 reka-core 和 mistral-large2,它们可以帮助您了解尖端模型的强大功能。 它在代码生成、数学、逻辑和语言支持方面的能力远超 mistral-large。它非常适合需要强大推理能力或高度专业化的复杂任务,例如代码生成、多语言文本分析和合成文本生成。它尤其擅长处理长文档、支持多种语言、生成合成数据和精调模型。 使用 Snowflake Copilot本文概述了 Snowflake Copilot 及其在数据分析工作流中的应用。本文中的示例使用了工作表,但当在 Snowflake Notebook 中使用 Snowflake Copilot 时,相同的过程也适用。 引言 Snowflake Copilot 是一款支持 LLM 的助手,可轻松融入您现有的 Snowflake 工作流,并在保持强大数据治理的同时简化数据分析。 Snowflake 优化了 Snowflake Copilot 的底层模型,该模型在 Snowflake Cortex(Snowflake 最先进、完全托管的 人工智能服务)内安全运行。通过这种方式,Snowflake 始终能确保您的企业数据和元数据的安全。此外,Snowflake Copilot 严格遵守 RBAC,并且仅根据可访问的数据集提出建议。 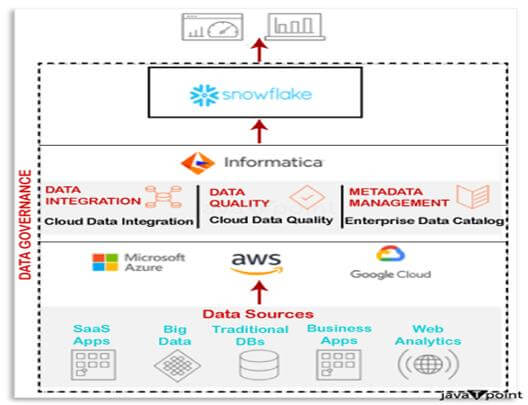 Copilot 通过自然语言请求简化了端到端的数据分析。首先,Copilot 可以协助您处理有关数据结构的问题,并在您检查新数据集时提供指导。然后,您可以指示 Copilot 创建和改进 SQL 查询,以便您能从数据中获得有价值的信息。Snowflake 甚至可以为 SQL 查询中的潜在问题提供优化或解决方法。 Copilot 还可以帮助您提高 SQL 熟练度并理解 Snowflake 功能。询问如何在 Snowflake 中执行某项任务,Copilot 将根据 Snowflake 文档提供响应。 访问控制要求允许用户使用 Snowflake Copilot 功能的权限位于 SNOWFLAKE 数据库中的 COPILOT_USER 数据库角色内。 PUBLIC 角色会自动分配 COPILOT_USER 角色。由于所有用户和角色都自动分配了 PUBLIC 角色,因此您账户中的所有用户都可以访问 Snowflake Copilot 功能。 当用户拥有此权限时,可以通过面板访问 Snowflake Copilot,并且“Ask Copilot”将出现在其工作表或笔记本的右下角。 支持的使用场景
局限性有限的语言支持:目前仅支持 SQL 和英语。无法访问您的数据
使用 Snowflake CopilotSnowflake Copilot 无需额外设置,即可立即使用。使用 Snowflake Copilot 时,请牢记以下几点:
包含特定说明您可以通过提供特定说明来更改 Snowflake Copilot 的响应方式。启用后,这些说明会改进提供给 Snowflake Copilot 模型的提示,并且 Copilot 在生成新响应时会考虑这些说明。自定义说明可以包含有关如何编写 SQL、如何以特定风格或特定语气进行回答,或者有关需要考虑的数据的更多详细信息。 添加自定义说明时,请牢记以下几点:
AI 文档什么是文档 AI? 文档 AI 是 Snowflake 的一项 AI 功能,它使用一种专有的 LLM(称为 Arctic-TILT)从文档中提取数据。文档 AI 可以读取各种文档格式,并从包含大量文本的段落以及以图形方式呈现的内容(如复选标记、徽标或手写文本(签名))中提取数据。您可以设置文档 AI 管道,以持续处理特定类型的文档,例如发票或财务报表。 此外,通过使用特定用例的文档训练模型,您可以精调 Snowflake Arctic-TILT 模型以优化您的发现。只有您才能访问精调后的模型(包括训练集),不会与其他 Snowflake 用户共享。 准备构建文档 AI 模型例如,用于从发票文档中提取数据的模型可以被视为反映了特定类型的文档或用例。文档 AI 模型构建包括模型、要提取的数据值以及用于测试和训练模型的文档。 您可以使用 Snowsight 的文档 AI 用户界面来准备模型构建。通过使用自然语言问题,该界面允许您定义数据值(要检索的信息)、测试和训练模型、评估模型、发布模型构建以及进行调整。 精调(Snowflake Cortex)使用 Snowflake Cortex 精调功能,您可以根据特定用例自定义大型语言模型。本文档将介绍如何使用该功能并开始构建您自己的优化模型。 概述 通过精调,用户可以利用参数高效精调(PEFT)为使用预训练模型处理更专业任务创建自定义适配器。如果您需要比快速工程甚至检索增强生成(RAG)方法更好的延迟和结果,但又不想承担从头开始训练大型模型的巨大成本,那么精调现有的大型模型是另一种选择。 提供 Cortex 精调功能的 Snowflake Cortex 函数 FINETUNE 接受以下参数: CREATE:使用提供的训练数据创建精调作业。 SHOW:列出当前角色有权访问的所有精调位置。 DESCRIBE:提供特定精调项目的状态和方向的概述。 CANCEL:终止特定的精调任务。 成本考虑Snowflake Cortex 精调功能的计算成本取决于训练期间使用的 token 数量。使用 COMPLETE 函数处理精调模型也会产生计算成本,这取决于处理的 token 数量。有关每百万 token 积分的成本信息,请参阅消耗量表。 Token 是 Snowflake Cortex 精调函数处理的最小文本单元,大约相当于四个文本字符。模型在原始输入或输出文本与 token 的比较方式上可能有所不同。对于生成新文本作为响应的 COMPLETE 函数,输入和输出 token 都会被计算在内。 Cortex Search 概述借助 Cortex Search,您可以对 Snowflake 数据进行高质量、低延迟的“模糊”搜索。Cortex Search 为 Snowflake 用户提供广泛的搜索体验,包括利用大型语言模型(LLM)的检索增强生成(RAG)应用。 借助 Cortex Search,您可以快速地在文本数据上建立混合搜索引擎,结合向量搜索和关键字搜索功能,而无需担心持续的索引刷新、基础设施维护、嵌入或搜索质量参数调整。这意味着您可以花更多时间创建出色的聊天和搜索体验,而花更少的时间优化基础设施和搜索质量。要获取有关如何使用 Cortex Search 为 AI 聊天和搜索应用程序提供支持的更多说明,请查看 Cortex Search 教程。 何时应用 Cortex Search
基本权限为了构建 Cortex Search 服务,您的角色需要具有 CORTEX_USER 数据库角色,这是 Cortex LLM 函数所必需的。有关分配和移除此角色的详细信息,请参阅 Cortex LLM 函数所需权限。 为了查询 Cortex Search 服务,查询用户的角色必须在服务所在的服务、数据库和架构上拥有 USAGE 权限。查看 Cortex Search 访问控制的要求。 结论总而言之,我们可以得出结论,Snowflake 通过其与 Google Vertex AI 和 AWS SageMaker 等第三方 ML 平台的无缝集成,以及通过 Snowpark 对 Python、Java 和 Scala 的支持,提供了一个全面的 AI 和 ML 平台。它除了促进自动化机器学习、实时分析和数据库内机器学习之外,还保证了健全的数据管理和安全性。这些功能使企业能够在 Snowflake 中有效地创建、训练和部署机器学习模型,从而能够大规模利用数据驱动的见解,而不会牺牲安全性和功能性。 下一主题 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
