Snowflake 分步指南2025年7月31日 | 阅读10分钟 Snowflake有什么用?Snowflake在全球为8900多家客户提供服务,每天处理39亿次查询。这种利用率数据绝非偶然。 以下列出了Snowflake的顶级优势: 1. 基于云的架构由于Snowflake在云中运行,企业无需担心物理基础设施(硬件),并且可以根据需求扩展或缩减资源。平台还负责日常维护任务,包括硬件管理、软件更新和性能调优。通过这样做,维护开销得以减少,使组织能够专注于真正重要的事情——从数据中获取价值。 2. 可扩展性和弹性Snowflake将计算层和存储层分离,用户可以根据其存储需求扩展其处理能力。这种灵活性使得有效处理各种工作负载成为可能,实现峰值性能和最小开销。  3. 性能和并发性Snowflake可以轻松处理高并发;多个用户可以访问和查询数据而不会遇到任何性能问题。 4. 信息交换Snowflake的安全措施使得内部部门、外部合作伙伴、客户和其他利益相关者之间的数据交换成为可能。无需复杂的数据传输。 5. 时光穿梭Snowflake将数据版本控制称为“时光穿梭”。每次修改数据库时,Snowflake都会拍摄快照。用户现在可以访问不同时间的历史数据。 关于数据仓库例如,数据分析师和营销团队可以使用销售表为新的营销活动进行A/B测试。人力资源专业人员可以通过查询员工数据来监控绩效。 这些是全球企业如何使用数据仓库来促进增长的一些例子。然而,如果数据仓库没有在Snowflake等程序的帮助下正确实施和管理,它们仍然是复杂的概念。  电子商店数据是Snowflake的重要组成部分。以下是该层的一些显著特点: 列式存储格式:Snowflake使用列式格式优化数据存储以进行分析查询。与Postgres等程序使用的传统行式格式不同,列式格式非常适合数据聚合。由于查询只访问所需的列,因此列式存储效率更高。 然而,对于计算平均值等基本任务,行式格式需要访问内存中的每一行。 微分区:Snowflake使用一种称为微分区的方法将表存储在内存中的微小片段中。由于每个片段通常是不可变的,并且只有几千兆字节大小,因此查询执行和优化显著加速。 零拷贝克隆:Snowflake的独特功能之一是它能够创建数据的虚拟副本。克隆是即时发生的,并且在修改新副本之前不会使用更多内存。 可扩展性和弹性:通过添加更多服务器来分散负载,存储层可以适应不断增长的数据量,因为它水平扩展。 计算层顾名思义,计算层是运行查询的引擎。它与存储层协作处理数据并执行各种计算活动。以下是该层功能的一些进一步详细信息: 虚拟仓库可以被认为是专门为执行查询而创建的计算机组或计算节点。由于每个团队成员专注于查询的不同方面,因此执行速度快且并行。Snowflake提供XS、S、M、L和XL等各种大小的虚拟仓库,因此成本也不同。 多集群、多节点架构:为了实现高并发性并允许多个用户同时访问和查询数据,计算层采用具有多个节点的多集群。 自动查询优化:Snowflake的技术使用历史数据分析每个查询,以查找可以优化的模式。选择最有效的执行路径、使用元数据和删除过多数据是标准优化的示例。 结果缓存:计算层有一个缓存,用于保存频繁运行查询的输出。当再次执行相同的查询时,结果几乎立即返回。 所有这些计算层设计理念都让Snowflake能够管理云中的各种具有挑战性的工作负载。 云服务层云服务构成了最后一层。由于此层集成到Snowflake架构的每个部分,因此关于其工作原理有一些具体细节。除了与层相关的特征外,它还具有以下额外的职责: 数据共享:此层为跨帐户甚至外部组织交换数据实施安全程序。数据消费者无需数据传输即可访问数据,从而鼓励协作和数据货币化。  配置SnowflakeSQL SnowflakeSQL是SQL的一种特定于Snowflake的变体。它与不同的SQL方言的区别类似于英语口音的区别。在DDL(数据定义语言)指令中存在细微差异,但您在PostgreSQL等方言中运行的许多分析查询保持不变。 Snowsight:一个用于平台的在线用户界面。SnowSQL是一个数据库管理和查询CLI(命令行界面)客户端。转到Snowflake网页并选择“免费开始”以开始使用Snowsight。输入您的数据并从列表中的任何云提供商中进行选择。无论您选择哪个选项都无关紧要,因为免费试用版为所有选项提供400美元的积分(您无需自行设置云凭据)。 以下是开始使用Snowflake的分步指南: 步骤1:如果您是新用户,Standard或免费试用版效果很好。选择您的云提供商:Snowflake可在AWS、Azure和Google Cloud上使用。选择适合您需求或与您组织设置匹配的提供商。 步骤2:设置您的Snowflake环境。登录Snowflake:通过您的帐户URL访问Snowflake控制台。
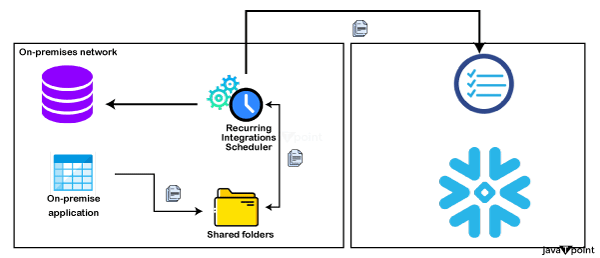 步骤3:将数据加载到Snowflake 建立存储位置:如果您从外部源(如AWS S3)加载,请授予Snowflake访问权限。 使用Snowflake Web UI上传数据
处理大数据加载时,请使用SnowSQL
步骤4:控制您扩展的Snowflake环境 监控和管理仓库
步骤5:使用物化视图自动化和优化(扩展) 为了更快地访问预计算数据,物化视图保存查询结果并定期更新。  使用任务进行自动化Snowflake任务可以按计划运行查询以自动化工作流。 创建每天运行以刷新表的任务 检查查询性能
高级步骤1:有效的数据摄取让大数据集焕发生机使用针对大型数据集优化的加载策略,以降低成本并提高性能 批量加载:要批量从外部存储加载数据,请使用COPY INTO。此命令将大文件分成更小、更易于管理的数据块。 文件压缩:加载前压缩文件(例如GZIP或BZIP2)。由于Snowflake会自动解压缩,因此缩短了加载时间并降低了存储开销。 并行加载:Snowflake可以在加载时同时处理多个文件。将多个文件放在一个步骤中并同时加载它们 使用流和任务加载数据 为了实现近实时摄取,请使用流和任务 流跟踪表上的数据更改,捕获插入、更新和删除。 任务按照定义的计划或事件触发器执行SQL代码,处理来自流的新数据 高级步骤2:查询优化方法查询缓存 Snowflake缓存查询结果以节省资金并加快重复请求 结果缓存:默认情况下,它将查询结果保留24小时。如果使用相同的参数再次执行查询,Snowflake会快速返回缓存的结果。 仓库缓存:通过在计算集群的本地存储中缓存数据来加速单个会话中的重复查询。 集群和分区Snowflake会自动处理数据拆分,但可以使用集群优化大型数据集 集群键:通过根据常用列排列数据,集群键可以提高查询性能。 重新集群:尽管Snowflake会根据需要自动重新集群数据,但您可以手动启动大型表的集群。 查询配置文件分析 要优化复杂查询,请使用查询配置文件 查询配置文件:检查SQL查询的执行方式,包括扫描、连接、过滤和聚合。这有助于定位瓶颈。 最佳实践
高级步骤3:合规性和数据安全数据加密Snowflake通过端到端加密保护数据 静态:使用AES-256加密数据。 传输中:TLS加密可确保您的环境与Snowflake之间的数据安全。 基于角色的访问控制 (RBAC) 使用RBAC控制数据访问 创建您的角色:根据用户职责建立角色(例如data_engineer和data_analyst)。 分配角色权限 行级安全性:要管理行级访问,特别是对于敏感数据,请使用ROW ACCESS POLICY。 数据掩码 数据掩码根据用户角色隐藏敏感信息 使用动态数据掩码将掩码规则应用于敏感字段,例如财务信息或社会安全号码。 外部访问和数据共享Snowflake支持安全数据交换,无需数据复制或传输 数据共享:通过使用共享,授予外部帐户只读访问权限。 数据市场:其他组织可以通过在Snowflake市场发布和共享数据来访问您的数据。 高级步骤4:分析和机器学习集成R与Python结合 为了进行更复杂的分析,Snowflake与R和Python连接 Snowpark:Snowflake的开发基础设施使R和Python程序可以直接在Snowflake中运行。 UDF或用户定义函数:为复杂的计算或更改创建独特的Python或JavaScript函数。 BI工具,与Snowflake结合Snowflake直接连接的流行BI工具包括
通过以下方式使用Snowflake的机器学习功能:
高级步骤5:成本管理和监控仓库使用管理 恢复和自动暂停:通过设置短暂的自动暂停时间,在不使用仓库时停止仓库,从而降低开销。 多集群仓库:为了有效管理工作负载,请使用多集群仓库。当使用量下降时,集群会缩减,并根据需求进行扩展。 关注账户使用情况 可以使用Snowflake的账户使用模式查看账户活动、仓库利用率和查询性能 查询监控:使用QUERY_HISTORY视图检查查询执行时间、扫描数据和仓库利用率。 成本分析:要跟踪计算成本并找出昂贵的工作负载,请使用WAREHOUSE_METERING_HISTORY。 资源监控和警报
结论总之,我们可以得出结论,Snowflake提供了一个坚实而灵活的数据平台,用于在各种环境中处理和评估数据。Snowflake的设计基于云存储和计算分离,使得各种规模的企业能够以可扩展和经济的方式处理数据。通过利用缓存、集群和物化视图,您可以提高查询效率并通过利用Snowflake强大的数据摄取功能加快数据加载。通过数据加密、RBAC、数据掩码和无缝数据交换等安全技术,提供了全面的数据保护和合规性功能。 下一主题 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
