Snowflake 中的存储过程2025 年 7 月 29 日 | 阅读 10 分钟 存储过程概述要添加在系统中运行 SQL 的过程代码,您可以编写存储过程。可以使用编程结构在存储过程中执行循环和分支。一个存储过程可以创建一次,然后重复使用。其中一种支持的语言用于编写过程的处理程序,即逻辑。 在获得处理程序后,您可以使用 `BUILD PROCEDURE` 命令来构建过程,并使用 `CALL` 语句来调用它。 您可以从存储过程返回单个值或表格式数据(如果由处理程序语言支持)。有关支持的返回类型的更多详细信息,请参阅 CREATE PROCEDURE。 注意:使用 CALL(带有匿名过程)来创建和调用匿名过程。创建和调用匿名方法不需要具有 CREATE PROCEDURE 架构权限的角色。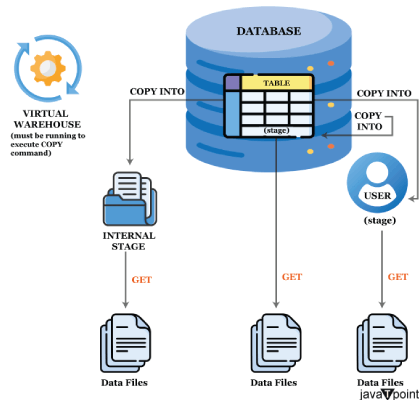 注意:虽然存储过程和 UDF 相似,但它们并不相同。有关更多详细信息,请参阅决定是编写用户定义函数还是存储过程。什么是存储过程?您可以为存储过程定义逻辑,并从 SQL 调用它。在大多数情况下,存储过程的逻辑使用 SQL 语句来执行数据库操作。存储过程允许您额外执行
安全性存储过程对数据的访问以及可能的操作范围可能会受到其是在调用者的权限下还是在所有者的权限下执行的影响。有关更多详细信息,请参阅存储过程理解调用者权限和所有者权限。一些安全问题在用户定义函数(UDF)和存储过程之间是相似的。有关更多详细信息,请参阅
 处理程序代码发布在构建过程时,您可以在 CREATE PROCEDURE 语句内指定运行的代码,也可以在语句外指定运行的代码,例如已生成、打包并复制到暂存区中的代码。 Snowflake 存储过程遵循哪些协议?可以从 SQL 直接调用的逻辑集合称为 Snowflake 存储过程。其主要用途是运行多个 SQL 语句以执行数据库任务。通过存储过程,用户可以使用调用者的角色权限(而不是所有者的角色权限)来运行和动态生成 SQL。这种权限转移使得更安全和更受控的操作成为可能。 Snowflake 存储过程通常用于自动化繁琐的操作,例如通过删除超过一定年龄的条目来清理数据。过程非常适合任何需要协调多个 SQL 语句之间步骤的过程。存储过程对变量、控制流和错误处理的强大支持使得在 Snowflake 中存储复杂的数据库逻辑成为可能。 支持 Snowflake 存储过程编程的语言Snowflake 支持多种编程语言来创建其存储过程的逻辑。这些语言包括:
注意:您选择的语言主要取决于您对它的熟悉程度、当前代码库以及它可能提供的任何独特功能或库。Snowflake 存储过程的语法分解为以下部分:名称: 指示 Snowflake 存储过程的名称。除非用双引号括起来,否则名称应以字母字符开头,并避免使用空格或其他字符。 输入参数 [,...]): 存储过程可以接受一个或多个参数作为输入参数,也可以不接受任何参数。定义了存储过程将生成的返回值的类型。 语言 SQL: 此字段指示用于存储过程的语言,因为 Snowflake 支持多种语言。对于 Snowflake JavaScript,值为 `javascript`;也可以是 Scala、Python、Java 或 Snowflake Scripting (SQL)。 过程体如下: Snowflake 存储过程的逻辑在过程体中定义。过程体流可以包括变量声明、SQL 语句等。 Snowflake 存储过程的结构通过使用 Snowflake 的高级存储过程,开发人员可以将多个 SQL 查询合并为一个可调用的例程。这提高了 SQL 操作 的效率,并鼓励代码重用。现在让我们更详细地检查 Snowflake 存储过程的结构。 Snowflake 存储过程的命名约定建议坚持一致且描述性的命名风格,尽管 Snowflake 不强制执行严格的限制,以保持清晰并便于将来的维护和方法调用。 在 Snowflake 存储过程中声明返回类型在创建过程时,必须指定 Snowflake 存储过程将返回的值的类型。在此过程中,选择的数据类型用于 RETURNS 关键字之后。  返回类型确保过程生成所需的输出,该输出随后可以被进一步应用或处理。STRING、NUMBER、FLOAT BOOLEAN 等是常见的返回类型。 以下是 Snowflake 存储过程的典型 JavaScript 返回类型的列表,包括示例:
Snowflake 存储过程中的调用者和所有者权限Snowflake 存储过程可以与所有者或调用者权限同时执行,但不能同时拥有两者。 调用者权限: 因为 Snowflake 存储过程以与调用它的个人或角色相同的权限运行,所以它可以访问调用者或调用者当前会话的信息。例如,它可以读取调用者的会话变量并在查询中使用它们。 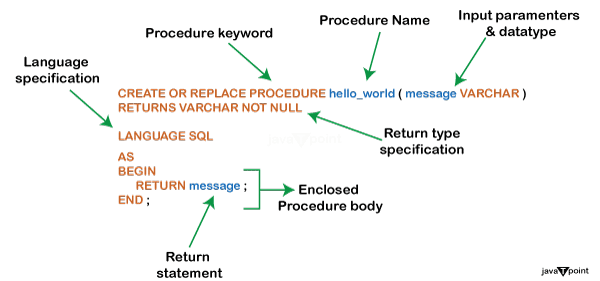 选择调用者或所有者权限在使用所有者或调用者权限之前,必须满足以下条件: 所有者权限: 选择此选项可将工作分配给其他用户或角色,从而授予他们所有者权限。当您希望他们拥有受限访问权限而无需授予更多权限时,此功能非常有用。 调用者权限: 如果您希望 Snowflake 存储过程仅在调用者拥有或拥有必要访问权限的对象上运行,请选择此选项。当过程需要使用调用者的环境时,例如会话变量。 Snowflake 存储过程的限制
注意:嵌套调用或递归调用可能导致超出最大堆栈深度。为了避免潜在的堆栈溢出错误,嵌套调用或使用递归时必须谨慎。如何使用 Snowflake Scripting 创建 Snowflake 存储过程
如果 Snowflake 存储过程变量有意义,该怎么办?具有存储特定数据类型的值的能力的命名对象是 Snowflake 变量。在执行存储过程时,存储在变量中的值可能会发生变化。在 Snowflake 存储过程中,变量用于存储可以在过程内部重复引用的结果。 与普通编程语言相比,Snowflake 脚本(SQL)中的变量不需要在使用前声明。尽管如此,在 Snowflake 存储过程的开头声明所有变量被认为是最佳实践。声明变量可以提高可读性,并有助于防止任何未来的问题。关于 Snowflake 存储过程中的变量的关键细节: 注意:如果您可以使用 DEFAULT 关键字设置初始值,Snowflake 将自动检测变量的数据类型。1. Snowflake 存储过程中的游标声明 在 Snowflake 存储过程中,游标充当允许数据库记录导航的控制结构。将其视为结果行组内单个行的指针。就像编程语言中的迭代器一样,它允许您遍历查询结果集中的行集,并一次处理一行。 在 Snowflake 存储过程中使用游标 以下描述了如何在 Snowflake 存储过程中使用游标:
2. 在 Snowflake 存储过程中包含循环 循环编程的基本原则是根据预定义的重复次数或条件重复执行一组指令。Snowflake 存储过程支持多种循环结构,每种结构都有独特的属性和应用。 Snowflake Scripting 支持的循环类型如下:
3. Snowflake 存储过程中的 RESULTSETs 在 Snowflake 存储过程中,用户可以使用 RESULTSET 数据类型存储和操作 SELECT 语句的结果集。 此强大功能为您如何处理查询结果提供了灵活性,允许您使用游标遍历它们或将它们作为表返回。 RESULTSET 代表什么? 在 Snowflake 中,RESULTSET 是查询结果集的指针。与仅存储一个值的标准变量相比,RESULTSET 可以保留多行数据。因此,需要处理或返回多行数据的过程将发现它非常有用。 如何在 Snowflake JavaScript 中编写 Snowflake 存储过程 对于了解 JavaScript 的开发人员来说,Snowflake 作为存储过程语言的支持开启了一个全新的可能性世界。本节将指导您完成使用 Snowflake JavaScript 创建 Snowflake 存储过程的过程,确保您充分理解每一步。 注意:虽然 Snowflake JavaScript 支持提供了更大的灵活性和功能,但它在存储过程中本质上仍在使用 SQL。必需条件
认识 Snowflake 存储过程 在开始创建过程之前,理解 Snowflake 存储过程的结构至关重要。Snowflake 中的存储过程
开发 Snowflake 存储过程的最佳方法
SQL 存储过程和 JavaScript 之间的主要区别
与 Snowflake 存储过程相关的要点
结论Snowflake 存储过程是一种实用的解决方案,可让用户轻松地集成执行 SQL 的过程代码。这些过程不仅仅是一系列 SQL 语句;它们提供了一个动态环境,其中的编程结构支持分支和循环。它们真正的力量在于其可重用性;一旦创建了一个过程,就可以一次又一次地调用它,从而确保每次都能进行可靠高效的操作。 下一主题 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
