Snowflake 数据压缩2025年1月29日 | 阅读10分钟 引言数据压缩是通过使用比原始表示更少的比特来编码信息。在数据库和数据仓库的背景下,压缩可以减少存储在磁盘上的数据大小,从而显著节省成本并提高性能。打包的信息需要更少的额外空间,并且可以比未压缩的数据更快地从磁盘读取和通过网络传输。 压缩类型Snowflake 结合使用多种压缩算法,根据数据类型和特性选择最合适的算法。 主要的压缩技术包括  内部数据压缩自动压缩 Snowflake 会自动压缩存储在其内部存储中的数据。当您将数据加载到 Snowflake 中时,它会自动使用各种压缩技术进行压缩。这对用户是透明的,这意味着您在加载数据时无需指定压缩设置。 压缩技术: Snowflake 使用多种复杂的算法和技术,包括
数据存储格式
外部数据压缩文件格式 Snowflake 支持各种可以压缩的外部文件格式,以节省存储空间并减少传输时间。支持的格式包括
外部阶段AWS S3、Google Cloud Storage、Azure Blob Storage
压缩和解压缩函数Snowflake 提供了几个内置函数,以方便在 SQL 查询中对数据进行压缩和解压缩。这些函数在处理大量数据时非常有用,可以实现更高效的存储和检索。以下是 Snowflake 中与压缩和解压缩相关的主要函数
让我们更详细地探讨这些函数:它们的语法、用例和实际示例。 COMPRESS 函数Snowflake 中的 COMPRESS 函数用于将数据压缩为二进制格式。此函数可以显著减小数据大小,这对于存储和性能非常有利,尤其是在处理大型数据集时。 语法
示例 假设我们有一个要压缩的重要文本字符串 此查询压缩输入字符串并以二进制格式返回。然后可以将压缩数据存储在表中以供以后使用。 DECOMPRESS_BINARY 函数DECOMPRESS_BINARY 函数解压缩以前使用 COMPRESS 函数压缩的二进制数据。此函数在检索和使用原始数据以其压缩二进制形式时是正确的。 语法
示例 假设我们有一个压缩表,其中包含一个存储压缩二进制数据的列“compressed_data”,我们可以按如下方式解压缩它: 此查询从表中检索压缩数据并将其解压缩为原始二进制格式。 DECOMPRESS_STRING 函数DECOMPRESS_STRING 函数用于将二进制数据解压缩为字符串格式。当原始数据为文本格式并需要以这种方式检索时,这非常有用。 语法
示例 使用相同的压缩表,我们可以将二进制数据解压缩回字符串 此查询检索压缩数据并将其解压缩为原始字符串格式。 选择正确的压缩策略 虽然 Snowflake 会自动处理许多压缩优化,但您仍然可以遵循一些最佳实践来充分利用压缩和解压缩
高效数据加载 确保数据已正确分区和索引,以优化压缩过程。Snowflake 的自动微分区可以提供帮助,但提供与自然数据边界对齐的数据可以提高压缩效率。 Snowflake 中支持的文件格式Snowflake 支持各种结构化和半结构化数据的文件格式。这些格式可以在将数据加载到 Snowflake 表中或创建外部表以查询存储在外部阶段中的数据时使用。下表总结了所支持的记录设计以及相关注意事项。 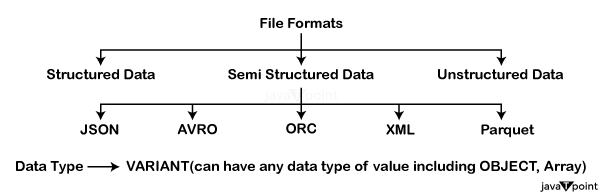
Snowflake 对各种结构化和半结构化文件格式以及各种压缩选项的支持,为不同的数据存储和处理需求提供了灵活性。通过有效利用这些格式,用户可以优化存储成本,提高查询性能,并高效管理大量数据。 创建命名文件格式在 Snowflake 中,命名文件格式定义了在将数据加载到表中时如何解析和处理数据文件。您可以通过 Snowflake Web 界面或 SQL 命令创建和管理命名文件格式。这两种方法都提供了灵活性,以适应不同的工作流程和偏好。 使用 Snowflake Web 界面Snowflake Web 界面提供了一个图形用户界面 (GUI) 来创建和管理文件格式。这项技术非常适合喜欢可视化方法并希望避免编写 SQL 命令的客户。 步骤:
创建命名文件格式您可以使用两种主要方法创建命名文件格式:Snowflake Web 界面(Snowsight 或经典控制台)和 SQL 命令。每种方法都提供了不同的配置和管理文件格式的方法。 通过 Snowsight 创建命名文件格式
通过经典控制台创建命名文件格式导航到数据库
选择文件格式
创建文件格式
使用 SQL 创建命名文件格式您还可以使用 SQL 命令创建命名文件格式。此方法对于自动化和脚本编写非常有用。创建文件格式的通用 SQL 语法是 将 <file_format_name> 替换为您要分配给文件格式的名称,将 <format_type> 替换为文件格式的类型(例如,“CSV”、“JSON”、“AVRO”),并添加格式所需的任何特定选项或参数。 使用命名文件格式的好处
覆盖默认文件格式和 COPY 选项在 Snowflake 中,虽然命名文件格式提供了一种标准化处理文件格式的方法,但您可能偶尔需要为特定的数据加载操作覆盖这些默认设置。这提供了灵活性和自定义功能,使您能够解决独特的数据处理要求并处理异常。 默认文件格式
覆盖默认文件格式选项 加载数据时,您可以直接在 COPY INTO 命令中覆盖命名文件格式的默认设置。如果您需要为特定文件或数据集调整格式而无需修改命名文件格式本身,这将非常有用。 覆盖默认文件格式选项的语法 示例 1:覆盖 JSON 文件格式的默认选项 如果默认 JSON 文件格式期望 UTF-8 编码,但您的文件采用不同的编码,您可以在 COPY INTO 命令中直接指定编码 覆盖 COPY 选项除了覆盖默认文件格式选项外,您还可以指定各种 COPY INTO 命令选项以自定义数据加载过程。这些选项包括处理错误、管理文件压缩和控制数据解析行为。
覆盖 COPY 选项的语法 覆盖 Snowflake 中的默认文件格式和 COPY INTO 选项提供了处理特定数据加载场景和根据需要自定义处理的灵活性。通过有效利用这些覆盖,您可以适应文件格式的差异,管理错误,并确保数据准确高效地加载到 Snowflake 表中。 下一主题Snowflake-数据治理 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
