Snowflake 动态查询优化2025年8月2日 | 阅读 11 分钟 动态表查询的性能本节涵盖了为实现高查询时间性能而设计管道的内容。您的数据在通过多个系统时会呈现多种形式
这些是构成您管道的步骤。尽管动态表用于转换步骤,但您应该考虑它们在整个管道中的表现如何。 理解实体化从原始数据到建模数据的转换方式设计和实现会影响分析查询的执行情况。尽管从技术上讲是有效的,但将这些转换描述为原始数据上的一组视图可能无法满足成本和效率要求。 为了解决这个问题,可能需要通过预先计算结果、存储以便于访问并保持其准确性来实体化部分或全部数据模型。您仍然必须选择要实体化的模型,但动态表使此过程变得简单。 实体化边界实体化边界是将转换的实体化和非实体化部分分开的线。以下元素通常对于选择实体化边界很重要 滞后或新鲜度:您的结果根据您提供的数据过时的程度。此元素通常不会受到实体化屏障的显着影响。 响应时间:您可以通过实体化更多管道来缩短响应时间。新鲜度可能会稍长,但它始终至少与回答您问题所需的时间一样长。 成本:以下因素与您的工作负载成本相关 实体化成本根据转换的复杂性和源数据量而异。 存储成本:这些费用包括原始数据和已处理数据。 虽然实体化更多建模数据会增加实体化成本,但它也降低了分析成本并加快了响应时间。必须平衡上述考虑因素以确定理想的实体化边界。通常,满足您响应时间要求的最少量数据可以产生有效的结果。 如何实现一旦确定了实体化边界,您就可以根据它创建动态表和显示。与任何其他 Snowflake 查询一样,您可以优化非实体化转换的性能。一旦查询,常规表和动态表的功能类似,允许您使用规范化、预聚合和聚类等常见方法来提高性能。 Snowflake 查询优化技术总的来说,本文讨论的 Snowflake 查询性能优化策略可以分为三组 提高数据读取的效率。 有时,查询可能需要很长时间才能从表存储中读取数据。在查询配置文件中,此查询步骤显示为 TableScan。在 TableScan 期间,信息通过网络从表的存储位置下载到虚拟仓库的工作节点。增加虚拟仓库的大小或减少下载的数据量将加快此过程。 只要表的微分区紧密地聚集在过滤条件上,Snowflake 只读取查询中选择的列以及与查询过滤器相关的微分区。通过最小化查询下载的数据量,有四种方法可以加快 TableScan 速度
提高数据处理效率。在 TableScans 之后,会发生 Join、Sort 和 Aggregates 等操作,这些操作经常导致查询瓶颈。减少查询步骤、逐步处理数据以及应用您对数据的理解来提高效率都是优化数据处理的方法。 提高数据处理效率的方法包括
确保查询缓存得到有效使用。优化仓库的配置。Snowflake 的虚拟仓库可以轻松设置为处理具有更多并发性和规模的工作负载。 提高性能的关键设置包括
如何更好地优化 Snowflake 查询在优化 Snowflake 查询之前,使用查询分析来确定其真正的瓶颈至关重要。由于本例中的 Sort 步骤是瓶颈,我们应该专注于提高数据处理效率,并可能扩大仓库。如果 TableScan 是查询中最昂贵的节点,则优化查询的数据读取效率是最佳行动方案。 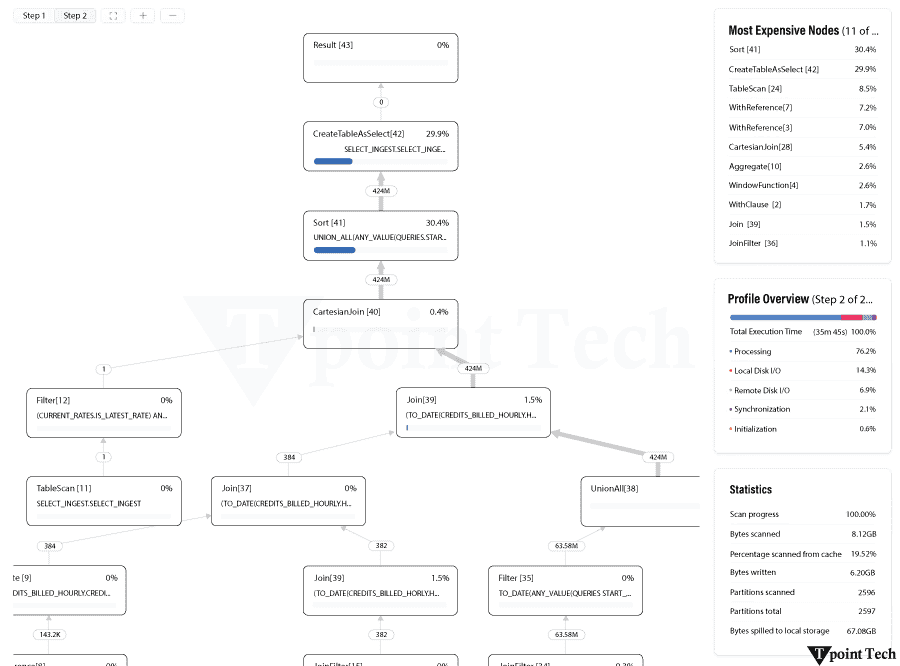 1. 选择更少的列。这是一个简单的,但如果可行,它会产生重大影响。一旦有用的列可能不再需要或被下游进程使用,并且查询要求会随着时间的推移而变化。微分区是 Snowflake 用于存储数据的混合列式文件结构。Snowflake 可以通过这种格式最大限度地减少必须从存储中读取的数据量。扫描是下载微分区数据的过程,列越少意味着通过网络传输的数据越少。 2. 利用查询剪枝要使用查询剪枝策略(该策略减少查询扫描的微分区数量),必须执行几个步骤。 您的查询中必须包含一个限制查询所需数据的过滤器。可以使用隐式连接过滤器或显式 where 过滤器。在过滤列上,您的表必须正确聚集。 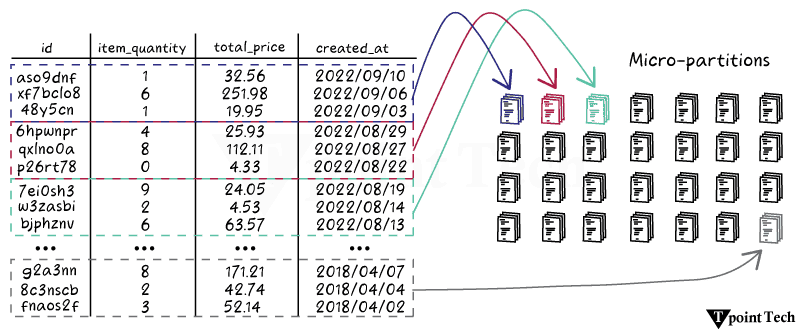 检查查询配置文件中的“扫描分区”和“总分区”统计信息,以查看是否可以提高剪枝性能。向查询添加 where 子句过滤将大大加快 TableScan(以及下游节点,因为它们处理的数据更少)。如果“扫描分区”接近“总分区”,并且您的查询已经具有 where 子句过滤,则 where 子句未被剪枝。 通过以下方式增强剪枝
3. 使用带聚类列的连接谓词。静态查询剪枝是大多数用户习惯的最流行的剪枝类型。这是一个简单的插图,类似于上面的插图 根据 Snowflake 的查询优化器,如果订单表按 order_date 聚类,则可以忽略大多数包含早于七天数据微分区(文件)。删除微分区将显著加快查询速度,因为扫描远程数据将花费大量处理时间。动态剪枝是 Snowflake 查询引擎鲜为人知的功能之一。动态查询剪枝在查询执行期间发生,而静态剪枝在执行之前在查询准备阶段发生。  考虑一个使用 MERGE 命令定期更新订单表中现有记录的过程。MERGE 需要我们想要更新的目标表(订单)与包含新或修改信息的源表之间的连接。 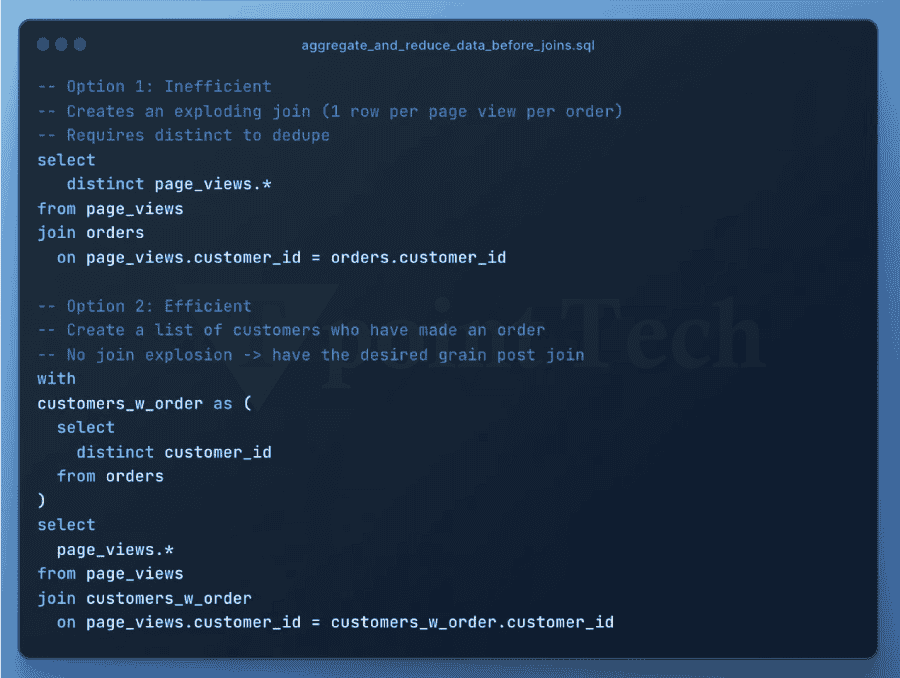 让我们用一个例子来说明这一点。假设我们在源表中有三条记录,我们需要在按订单日期分组的目标订单表中更新这些记录。通常,MERGE 过程会使用唯一键(例如订单键)来匹配两个表之间的记录。这些唯一键不需要任何查询剪枝,因为它们通常是随机的。 如果我们将 MERGE 条件更改为同时匹配订单键和订单日期上的记录,则动态查询剪枝可能会生效。Snowflake 可以识别当我们从源表读取数据时,我们正在更新的三个订单所涵盖的日期范围。 4. 利用预聚合数据创建数据行较少的“汇总”或“派生”表。预聚合表通常可以制作成使用更少的存储空间,同时仍然提供大多数查询所需的信息。因此,它们可以更快地进行查询。零售公司的一种流行方法是使用每日订单汇总表进行库存和财务报告,仅当需要按订单粒度时才查询原始订单数据库。 5. 简化!每个查询操作将数据传输到工作线程都需要时间。当合并和消除不必要的进程时,查询可以通过更少的网络传输执行。此外,它通过允许计算重用为 Snowflake 节省了更多的精力。CTE 和子查询通常不影响性能,因此,使用它们来帮助提高可读性。 6. 减少处理的数据量数据处理的每个阶段的数据越少,处理速度就越快。通过最小化查询每个阶段处理的行数和列数,可以提高性能。 7. CTE 有时可以更快地重复。之前的文章已经讨论过是否在 Snowflake 中使用 CTE。如果您在查询中多次引用 CTE,则查询配置文件中将出现 WithClause 操作(请参阅下面的示例)。在某些情况下,每次需要引用 CTE 时都重写它可能会更有效,甚至可能会减慢查询速度。 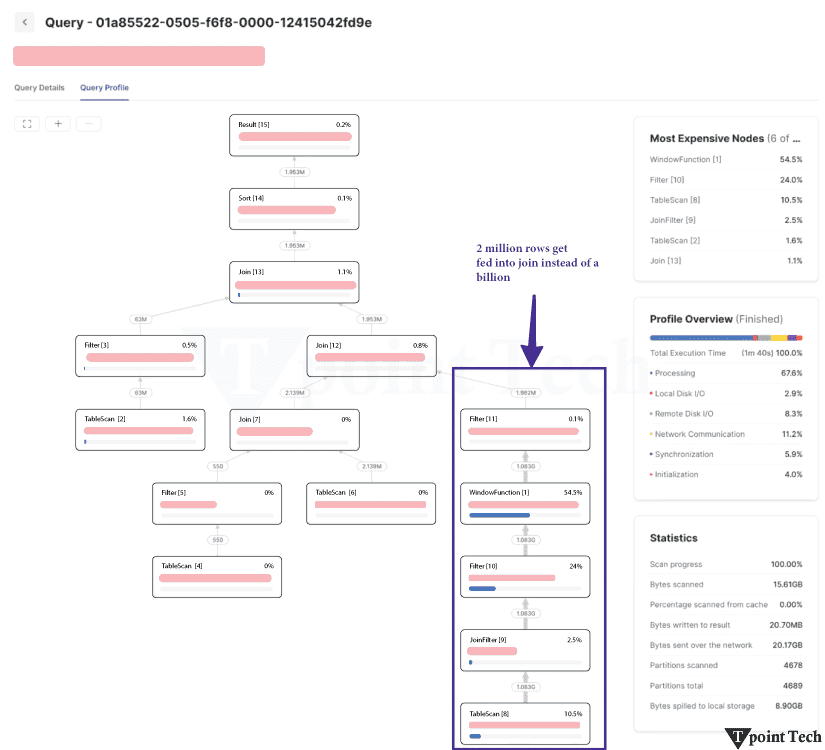 一旦达到一定的复杂程度,计算一次 CTE 然后将结果发送到下游引用将比多次重新计算更便宜。但是,由于这种行为不一致,最好尝试不同的方法。这是一个关系的说明 8. 消除不必要的排序由于排序是一个昂贵的过程,因此请务必消除任何不必要的排序 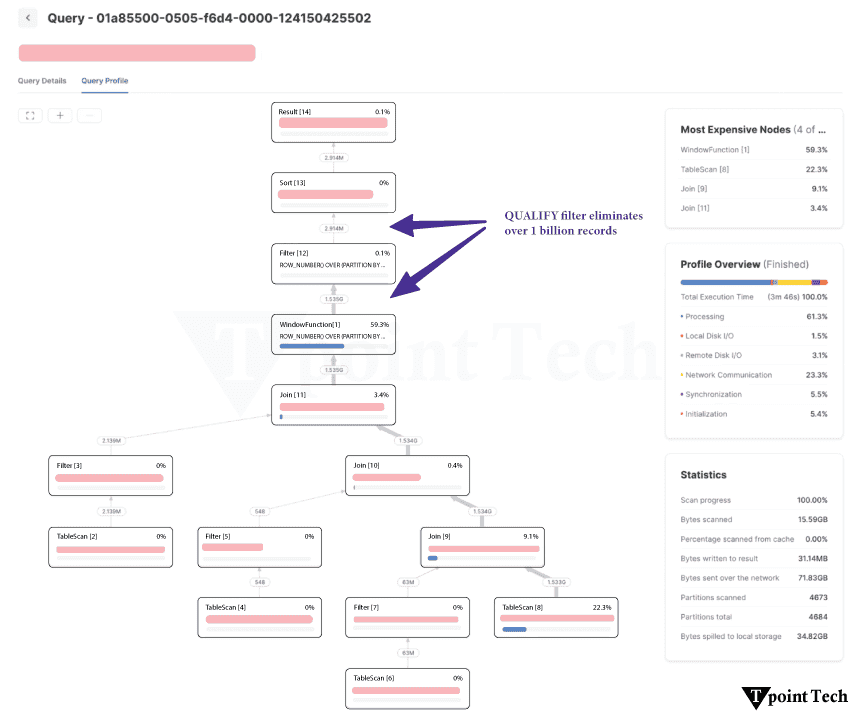 9. 优先使用窗口函数而不是自连接尽可能尝试使用窗口函数而不是自连接,因为后者会导致连接爆炸并且成本非常高。 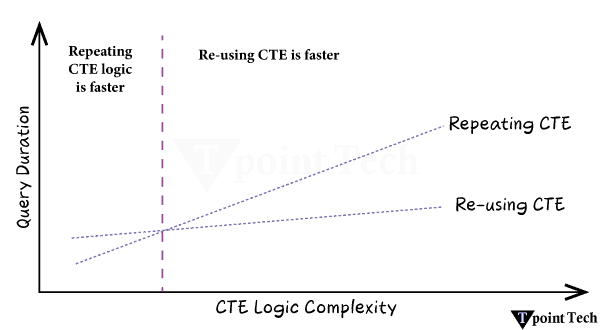 10. 避免使用带有 OR 条件的连接。因为它们作为带有后过滤操作的笛卡尔连接执行,所以带有 OR 连接条件的连接(如自连接)会导致连接爆炸。相反,使用两个左连接 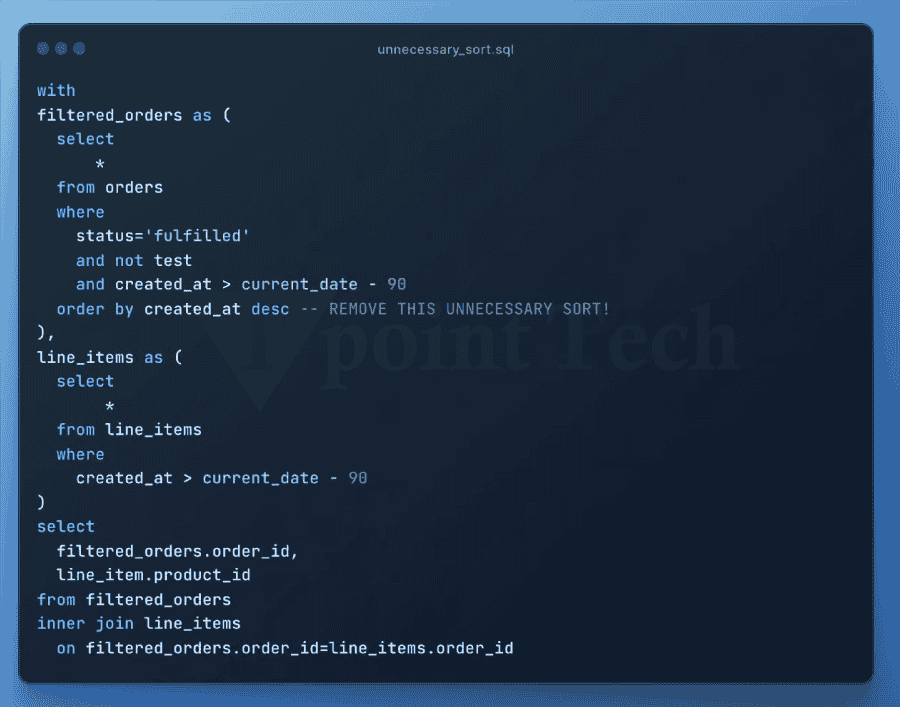 11. 利用您对数据的理解来帮助 Snowflake 有效地处理数据。您可以通过利用您对数据的理解来提高查询性能。 例如,如果查询对大量列进行分组,并且您知道某些列是冗余的,因为其他列已经反映了相同或更高的粒度,则从组中删除某些列然后在稍后阶段重新连接它们可能会更快。 如果分组或连接的列高度倾斜,这意味着少数唯一值出现最频繁,则 Snowflake 的速度可能会受到影响。按具有大量空值的列分组是一个典型的例子。通过过滤掉包含这些值的行并单独处理它们,可以实现更快的查询速度。 最后,范围连接在 Snowflake 和其他 数据仓库中可能会很慢。您可以通过利用您对数据中间隔长度的理解来减少连接爆炸。如果您遇到慢速范围连接性能问题,请阅读我们关于此主题的最新文章。 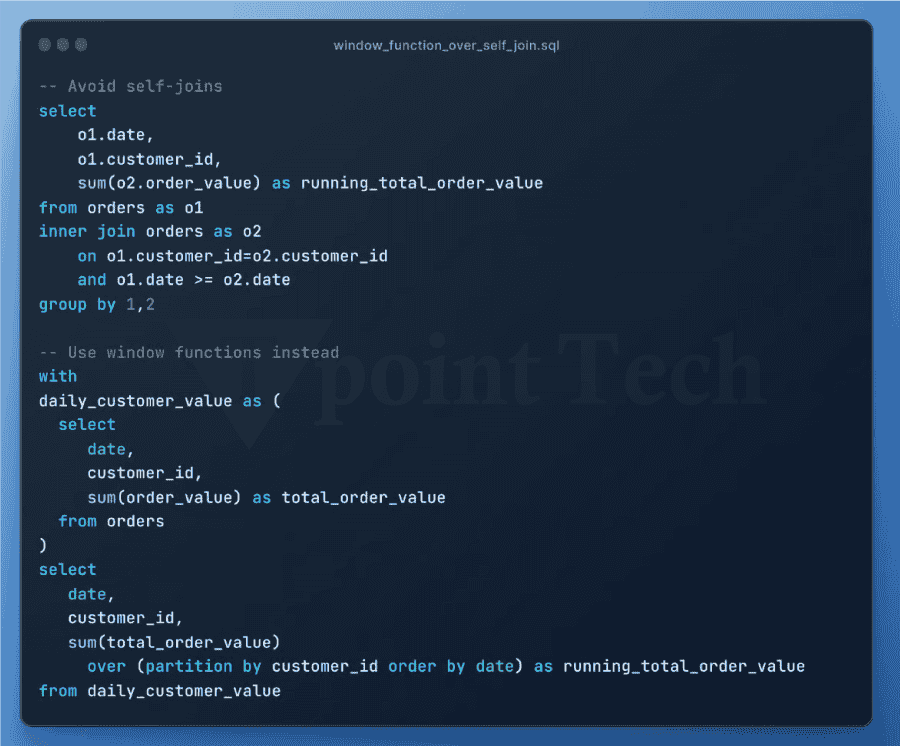 12. 避免复杂的视图最佳实践是避免在查询中构建和使用任何复杂的视图。视图应用于具有轻量级连接或简单数据更改(例如重命名列或执行简单的列计算)的数据模型。 13. 确保查询缓存得到有效使用。从外部存储读取的微分区可以使用每个虚拟仓库节点上的本地磁盘存储进行缓存。如果读取数据是主要的瓶颈,并且多个查询访问表中相同的数据集,则通过使用本地磁盘缓存而不是远程存储,可以加快查询速度。 Snowflake 不保证仓库暂停或恢复后缓存的持久性。缓存丢失意味着查询必须重新扫描表存储,而不是从速度明显更快的本地缓存访问数据。如果查询受到仓库缓存丢失的影响,提高自动暂停阈值将有所帮助。  此外,Snowflake 具有全局结果缓存,如果查询表中数据相同,它将在一天内为运行的类似查询提供结果。确保您在应该使用全局结果缓存时使用它,因为某些情况可能会阻止您使用它(例如,如果您的查询包含非确定性函数)。如果不是,您可能需要修改您的问题或联系支持部门报告问题。 14. 扩大仓库规模仓库规模(称为垂直扩展)决定了仓库中执行查询可用的总处理能力。 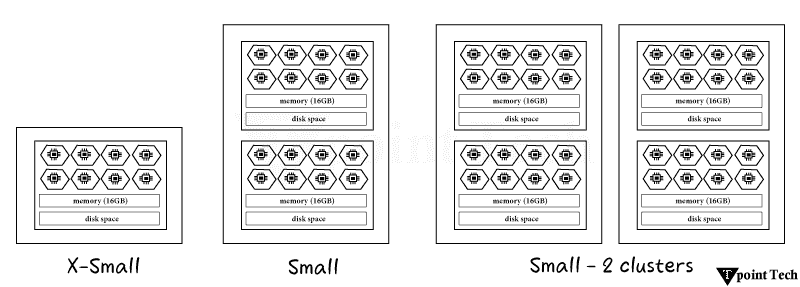 在以下情况下扩大虚拟仓库的规模
Snowflake 根据工作负载条件、查询复杂性和数据分布在运行时修改执行技术的能力称为“动态查询优化”。 Snowflake 动态查询优化的重要元素1. 自动剪枝查询 通过利用元数据,Snowflake 自动消除多余的分区(微分区),减少扫描的数据量。 2. 查询编译和优化
3. 自适应缓存机制
4. 扩展并发性
结论总之,我们可以得出结论,通过使用智能执行技术、缓存、自适应扩展和自动剪枝,Snowflake 的动态查询优化提高了查询性能。Snowflake 通过利用基于成本的优化、查询加速和有效的连接方法来保证更少的数据扫描和更快的执行。用户应使用查询配置文件监控执行计划,并优化查询结构、物化视图和聚类键以优化速度。Snowflake 的无服务器和自动扩展架构允许它自动适应工作负载的变化,从而确保有效和经济高效的查询执行。 下一主题 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
