机器学习中的数据预处理2025年9月2日 | 9分钟阅读 数据预处理是准备原始数据并使其适合机器学习模型的过程。它是创建机器学习模型时的第一个也是至关重要的一步。 在创建机器学习项目时,并非总能遇到干净且格式化的数据。在进行任何数据操作时,都必须清理数据并以格式化的方式处理。因此,我们使用数据预处理任务。 为什么我们需要数据预处理?机器学习一直致力于数据预处理,因为现实世界中的数据往往是不完整的、不一致的且有噪声的。它包括清理、转换和结构化数据,使其可用于建模。这包括填充缺失值、消除错误、缩放特征和编码分类变量。 预处理可以使特征具有相同的尺度,提高模型的准确性,并加快训练速度。它也适用于通过降维来消除不相关或冗余的特征。预处理确保 机器学习算法能够更好地学习模式,因为它创建了一个一致且结构化的数据库,从而产生更准确的预测和更可靠的数据。 数据预处理的步骤数据预处理是一个多步骤活动,旨在提高数据的质量、结构和相关性,以便输入到机器学习模型中。每个步骤都处理一个特定的挑战,并遵循以下顺序。 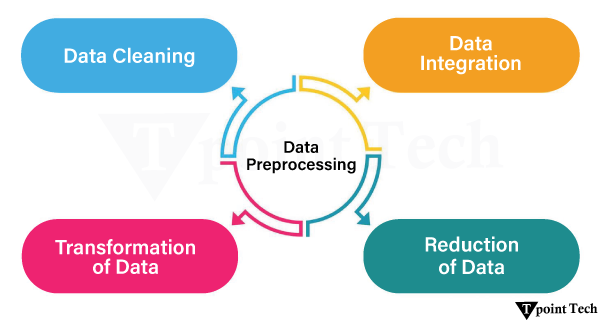 步骤 1:数据清洗数据清洗包括错误识别和纠正、不一致性的消除以及完整性。数据的低质量有可能误导分析并对模型性能产生负面影响。 主要活动是
示例 输出 name age purchase_amount date_of_purchase 0 John 28.0 100.500000 2023-12-01 1 Jane 34.0 84.075000 2023-12-02 2 Jack 28.0 85.300000 2023-12-01 4 None 22.0 50.000000 2023-12-03 步骤 2:数据集成数据集成是将来自多个源的数据集成到一个统一的数据集中。它将涵盖列和结构(模式匹配和数据去重)的匹配和对齐。此过程将数据最终确定为完整、一致且已准备好进行分析。 示例 输出 customer_id name age purchase_amount purchase_date 0 1 John 28 100.5 2023-12-01 1 3 Jack 29 85.3 2023-12-02 步骤 3:数据转换数据转换是数据转换过程,其中原始数据被修改以适应分析或机器学习架构。缩放和标准化通常与之一起进行,将数值带入熟悉的范围,特别是对于对尺度敏感的算法。它还提供了一种编码分类变量的选项,即标签编码或独热编码等,以便模型能够最有效地处理非数字数据。 示例 输出 category numeric_column scaled_numeric_column category_A category_B category_C 0 A 10 -1.069045 1.0 0.0 0.0 1 B 15 0.267261 0.0 1.0 0.0 2 A 10 -1.069045 1.0 0.0 0.0 3 C 20 1.603567 0.0 0.0 1.0 4 B 15 0.267261 0.0 1.0 0.0 步骤 4:数据缩减数据缩减包括通过删除关键信息不多的特征或记录来简化数据集。它可以快速分析和计算,成本更低,并增强训练。一些常见的方法包括特征选择,只保留关键变量;主成分分析,在保持接近或相似的方差的同时大大减小维度;以及通过选择代表性子集来对大量数据进行采样。 示例 输出 Selected features (SelectKBest): [[ 10 100] [ 20 200] [ 30 300] [ 40 400] [ 50 500]] PCA reduced data: [[-2.82842712e+01 1.31838984e-15] [-1.41421356e+01 -2.06060810e-16] [ 0.00000000e+00 -1.24790386e-16] [ 1.41421356e+01 -2.06060810e-16] [ 2.82842712e+01 1.31838984e-15]] 数据预处理的常用技术原始数据预处理保证了数据的质量、一致性以及为进一步分析或机器学习模型做准备。以下提供了一些处理数据集问题的典型方法。 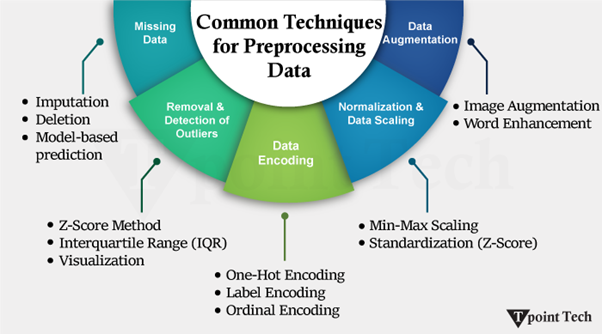 1. 缺失数据值的缺失可能会对模型产生负面影响。典型的策略是 插补:使用均值、中位数或众数填充缺失数据。更复杂的方法使用模型来估计缺失值。 删除:删除行或列的值。 基于模型的预测:当涉及复杂模式时,使用其他特征来插补缺失值。 2. 异常值检测与删除异常值可能导致偏差。它们可以通过以下方法识别和处理 Z-Score 方法:数据在正负3个标准差之外的数据被标记为异常值。 四分位距 (IQR):确定不在 IQR 的 1.5 倍和 Q1 或 Q3 之间的值。 可视化:箱线图、散点图和直方图可以显示极端值。 3. 数据编码分类数据应转换为数字形式,以便使用 ML 模型 独热编码:为每个类别创建二进制列。 标签编码:为每个类别分配不同的整数值。 序数编码:它以数字形式对有序类别进行编码。 4. 数据归一化和缩放缩放可确保数值特征落在相同的尺度上 Min-Max 缩放:将尺度缩放到 0 到 1。 标准化 (Z-Score):通过将数据标准化为均值 = 0 和标准差 = 1 来进行标准化。 5. 数据增强主要应用于图像和文本数据,以人工方式增加数据集的大小 图像增强:通过旋转、翻转、缩放和添加噪声来生成变化。 词语增强:通过替换、同义词替换或回译来创建变体。 数据预处理工具虽然可以使用纯 Python 代码进行数据预处理,但已经出现了许多强大的工具来加速操作、提高效率和扩展性。这些工具使数据清理、转换和组织等常见任务变得容易。 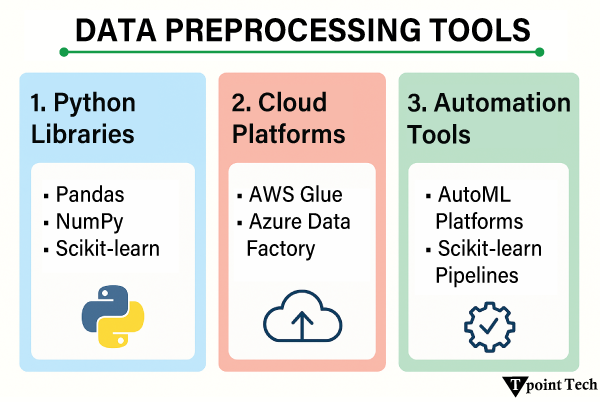 1. Python 库Pandas: Python 中最流行的数据操作和清理库。它具有灵活的数据结构 DataFrame 和 Series,可以高效地处理结构化数据。流行的操作包括值管理、数据合并、数据过滤和重组。 NumPy:数值函数的底层库。它使人们能够处理多维数组和矩阵,以及一系列数学运算。许多其他 Python 数据处理工具都构建在 NumPy 之上,例如 Pandas。 Scikit-learn:在机器学习特性方面非常受欢迎,并提供许多预处理工具。它包括缩放、分类变量编码、缺失数据、特征提取等。 2. 云平台处理相当大的数据集时,本地系统可能不足。可以通过云平台解决数据预处理问题,并具有扩展的可能性。 AWS Glue:一个完全托管的 ETL(提取、转换、加载)服务,可以自动发现、组织和准备数据,以便进行分析。它可以与 Amazon Web Services(如 S3 和 Redshift)结合使用。 Azure Data Factory:微软提供的大规模数据管道构建云服务。它托管 ETL 和 ELT 框架,通过使用图形界面促进数据迁移、数据转换和数据工作流编排。 3. 自动化工具自动执行重复步骤的预处理可以减少错误并节省时间,尤其是在大规模机器学习项目中。 AutoML 平台:这些工具,如 Google AutoML、Azure AutoML 和 H2O.ai AutoML,可以自动化机器学习管道的组件,例如特征选择、数据转换甚至模型选择。 Scikit-learn Pipelines:Scikit-learn 具有一个管道系统,可以将多个预处理步骤组合到一个一致的工作流中。这使得在训练和预测过程中预处理保持一致。 数据预处理的用途数据预处理可以将原始的、脏乱的数据进行清理,修复任何低效之处,从而提高决策的准确性、可靠性和效率。它在各个领域都很重要 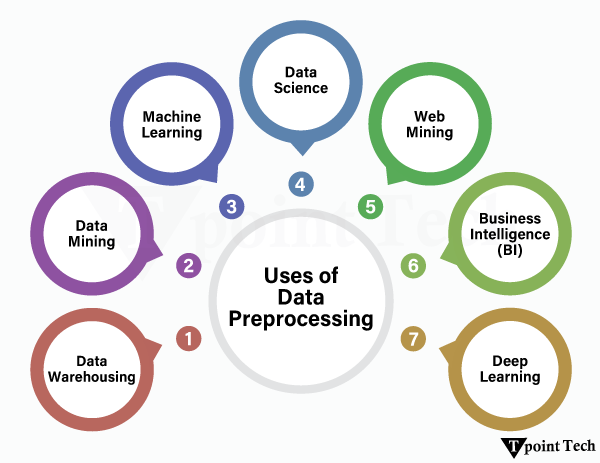 数据仓库:清理、混合和排序来自不同信息源的数据,以存储在单个点。这带来了数据的一致性,消除了不一致性,并提高了数据在大型查询、报告和分析中的可靠性。 数据挖掘:将原始数据转换为适当的格式,以识别未知的模式、趋势和关系。此步骤提高了算法的准确性,使用户能够更轻松地在大型数据集中找到有用的业务/研究答案。 机器学习:它处理包含空值的 Pdata 点,将数字转换为其标准形式,对分类数据进行编码,并将数据划分为训练集、验证集和测试集。在这种情况下,必要的预处理将直接影响模型的性能、准确性和泛化能力。 数据科学:消除重复项和不准确之处,使数据变得相关且组织良好,用于统计、探索性工作、预测或建模。这提高了研究结果的可靠性并有利于研究质量。 网络挖掘:处理 Web 服务器日志文件、点击流和用户活动数据,以开发行为模式。然后将此类信息应用于特定的营销、增强网站的可用性以及个性化建议。 商业智能 (BI):精炼和组织企业数据,以提供仪表板、关键绩效指标 (KPI) 和分析报告。这将使管理者和利益相关者能够做出明智的、数据驱动的业务决策。 深度学习:缩放、归一化或增强数据,以提高训练大型神经网络的性能。充分的预处理还将确保模型适应相关模式,并且不受噪声或无关变化的干扰。 数据预处理的优点以下列出了一些数据预处理的主要优点 
数据预处理的缺点除了优点之外,数据预处理还存在一些主要的缺点,如下所述 
结论机器学习模型训练所使用的数据的质量和结构对于这些模型的质量、性能、准确性和泛化至关重要。因此,数据预处理对于生成和处理高质量、结构良好的数据至关重要。它解决了缺失值、异常值、变量格式不匹配、分类编码和类别不平衡等问题,使数据适合模型。 下一主题监督机器学习 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
