DBMS 中的 COMMIT 协议2025年3月17日 | 阅读 12 分钟 本文详细讨论了分布式提交协议、事务基础以及事务状态。让我们开始讨论,首先了解事务和事务状态。 什么是事务?根据通用计算理论(操作系统),我们可能会有一个部分执行的程序,因为原子性的级别是指令,这意味着要么指令被完全执行,要么不执行。 然而,从数据库管理系统(DBMS)的角度来看,用户执行的一个逻辑任务(操作)总是原子性的,这意味着不存在部分执行的情况。 假设我们要从 X 的银行账户向 Y 转账 10000 卢比。要完成以下任务需要以下指令:
如果在执行第三条指令后发生故障,系统的最终状态将是不一致的,因为 X 的账户将扣除 10000 卢比,但 Y 的账户将不会收到这笔款项。 为了使系统保持一致,这里 X + Y == X' + Y'。 为了解决这个部分执行问题,我们提高了原子性级别,并将逻辑操作的所有指令分组为一个称为事务的单元。因此,事务被正式定义为“执行逻辑工作单元的一组逻辑上相关的指令”。 事务状态事务一次最多可以处于五种状态之一。
现在让我们开始讨论我们的主要议程。 分布式数据库管理系统 - COMMIT 协议在本地数据库系统中,事务管理器只需将其提交事务的决定通知恢复管理器。然而,在分布式系统中,事务管理器应一致地执行提交决定,并将其传达给正在进行事务的所有参与者所在的各个站点。每个站点的处理在达到部分提交事务状态时结束,然后等待所有其他站点达到其部分提交状态。一旦收到所有站点都已准备好的信号,它就开始提交。在分布式系统中,要么所有站点都提交,要么没有站点提交。 为了保证原子性,执行的最终结果必须被执行事务 T 的所有站点接受。T 必须在所有位置提交或在所有位置中止。事务协调器 T 必须执行提交协议以保证此属性。 分布式数据库管理系统提交协议总共有三种:
1. 单阶段提交分布式单阶段提交是最简单的提交协议。考虑事务在控制站点和多个从属站点上执行的场景。以下是单阶段分布式提交协议遵循的步骤:
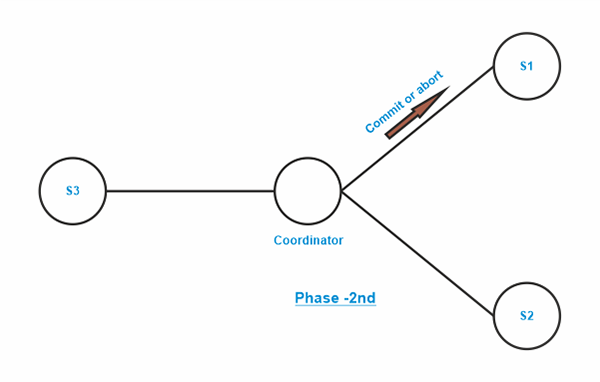
2. 两阶段提交本节将介绍的两阶段提交协议 (2PC) 是最简单和最受欢迎的提交方法之一。分布式两阶段提交可以降低单阶段提交方法的易受攻击性。以下是两阶段的操作: 考虑一个在站点 Si 上执行并由事务协调器 Ci 协调的事务 T。 当 T 完成时,或者当 T 执行过的所有站点都通知 Ci T 已完成时,Ci 启动 2PC 协议。 阶段 1 - 获取决定
阶段 2 - 记录决定
在向协调器发送 ready T 消息之前,T 执行过的站点可以随时无条件中止 T。发送消息后,事务将被视为处于“就绪状态”。ready T 消息本质上表示站点承诺执行协调器的提交 T 或中止 T 的指令。在做出此类承诺之前,必须将必要的数据保存在稳定存储中。否则,如果站点在发送 ready T 后崩溃,它可能无法兑现其承诺。此外,在事务完成之前,必须保留作为事务一部分获取的任何锁。 由于需要达成一致才能提交事务,一旦至少一个站点以 abort T 作为响应,T 的命运就已决定。由于协调器站点上的 Si 是 T 执行过的站点之一,协调器有权单方面决定终止 T。协调器将决定(commit 或 abort)写入日志并强制其写入稳定存储,这构成了涉及 T 的决定的最终确定。在某些 2PC 协议实现中,站点会在第二阶段结束时向协调器发送“acknowledge T”消息。协调器在收到所有站点的“acknowledge T”消息时,会将“complete T”记录添加到日志中。 错误处理2PC 协议对不同类型的故障有不同的反应。 A. 参与站点故障 - 当站点发生故障时,协调器 Ci 执行以下操作:如果站点在发送 ready T 消息之前发生故障,协调器会认为该站点向 Ci 响应了 abort T 消息。在收到该站点的 ready T 消息后,如果该站点发生故障,协调器将照常继续执行提交协议的其余部分,而不关心该站点的故障。 一旦参与站点 Sk 从故障中恢复,它必须检查其日志,了解在故障发生时仍在处理的事务的状态。假设 T 是其中一个这样的事务。我们检查以下每种情况:
B. 协调器故障 - 如果协调器在 T 的提交协议执行期间发生故障,参与站点必须决定事务 T 的命运。我们将看到,有时参与站点无法决定提交还是中止 T。因此,这些站点被迫等待故障协调器成功恢复。
阻塞问题 - 例如,如果使用了锁,T 可能持有活动站点上数据的锁。这种情况是不可取的,因为 Ci 可能需要数小时或数天才能再次运行。此时,其他事务可能需要等待 T。因此,数据项可能不仅在失败站点 (Ci) 上不可用,在活动站点上也可能不可用。这种情况被称为“阻塞问题”,因为 T 在等待站点 Ci 恢复时被阻塞。 C. 网络分区 - 当网络分区发生时,有两种结果:
因此,2PC 协议的主要缺点是协调器故障可能导致阻塞,在这种情况下,提交 T 或中止 T 的决定可能需要延迟到 Ci 恢复。 恢复和并发控制当发生故障的站点恢复时,我们可以进行恢复,例如,通过采用恢复策略。为了处理分布式提交协议,恢复过程必须以不同的方式处理“不确定事务”(定义为日志记录中存在 ready T>,但不存在 commit T> 或 abort T> 记录的事务)。如“错误处理”部分所述,恢复的站点必须联系其他站点以了解这些事务的提交-中止状态。 然而,如果按照上述方式进行恢复,正常的事务处理在该站点上不能开始,直到所有不确定事务都已提交或回滚。确定不确定事务的状态可能需要一些时间,因为可能需要联系多个站点。此外,如果使用 2PC 且协调器发生故障,并且没有其他站点知道未完成事务的提交-中止状态,则恢复可能会被阻塞。因此,执行重启恢复的站点可能会在相当长一段时间内不可用。 3. 三阶段提交在特定假设下,可以通过三阶段提交 (3PC) 协议扩展两阶段提交协议,以克服阻塞问题。 特别假设不会发生网络分区,并且失败的站点数量不会超过 k 个,其中 k 是预设的数字。在这些假设下,协议通过添加涉及多个站点参与提交决定的第三阶段来防止阻塞。 协调器首先确保至少有 k 个其他站点知道它计划提交事务,然后才立即将其提交决定记录在持久存储中。万一协调器发生故障,幸存的站点将首先选择一个替代者。 新的协调器从剩余站点检查协议的状态;如果协调器已经做出了提交决定,那么它通知过的其他 K 个站点中至少有一个在线,并将确保提交决定得到执行。如果某个站点知道前协调器打算完成事务,则新的协调器将从第三阶段开始重新执行。否则,新的协调器将中止该事务。  3PC 协议的优点在于,只要失败的站点少于 k 个,就不会发生阻塞,但缺点是网络分区可能被误认为超过 k 个站点失败,从而导致阻塞。此外,协议必须正确设计,以防止在网络分区(或超过 k 个站点失败)的情况下出现不一致的结果,例如在一个分区中提交了事务,而在另一个分区中中止了事务。由于其开销,3PC 协议并不常用。 分布式三阶段提交协议的三个阶段如下: 第一阶段 - 获取初步决定
2PC 的第二阶段在 3PC 中分为第二阶段和第三阶段。 第二阶段 - 第二阶段涉及协调器做出类似于 2PC 的决定(称为预提交决定),并将其记录在多个(至少 K 个)站点中。 第三阶段 - 第三阶段涉及协调器通知所有参与站点是提交还是中止。 在 3PC 下,即使协调器发生故障,也可以利用预提交决定的知识来完成决定。 只要 < K 个站点处于不活动状态,就可以防止阻塞问题。 下一主题DBMS 中的异常 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India