数据库中的反规范化2025年3月17日 | 阅读 3 分钟 当我们对表进行规范化(normalization)时,我们会将它们分解成多个更小的表。因此,当我们想要从多个表中检索数据时,我们需要执行某种连接(join)操作。在这种情况下,我们使用反规范化(denormalization)技术来消除规范化的缺点。 反规范化是数据库管理员用来优化其数据库基础设施效率的一种技术。该方法允许我们在规范化的数据库中添加冗余数据,以缓解数据库查询中将多个表的数据合并到一个表中的问题。反规范化概念基于规范化的定义,规范化被定义为为了特定目的而将数据库正确地组织成表。 注意:反规范化并不意味着不做规范化。它是在实现规范化之后使用的一种优化策略。例如,在进行规范化后,我们有两个表 students 和 branch。student 表具有属性 roll_no(学号)、stud-name(学生姓名)、age(年龄)和 branch_id(院系 ID)。 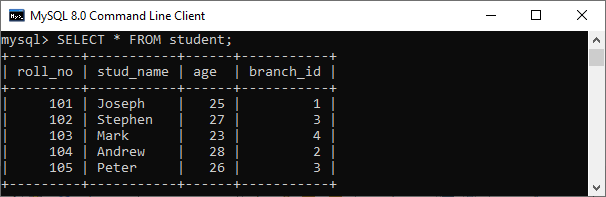 此外,branch 表通过 branch_id 与 student 表相关联,branch_id 是 student 表的外键。  当我们想检索所有学生姓名以及院系名称时,需要在这两个表之间进行JOIN 操作。假设我们只想更改学生姓名,那么如果表很小,那就很好了。这里的问题是,如果表很大,对表进行连接可能会花费很长时间。 在这种情况下,我们将通过反规范化、冗余和额外的努力来更新数据库,以最大化较少连接的效率优势。因此,我们可以将 branch 表中的院系名称数据添加到 student 表中,从而优化数据库。 反规范化的优点反规范化的优点如下: 1. 提高查询性能 规范化数据库中的查询通常需要连接大量的表,但我们已经知道,连接越多,查询速度越慢。为了克服这个问题,我们可以通过在父表和子表之间复制值来向数据库添加冗余,从而最大限度地减少查询所需的连接次数。 2. 使数据库更易于管理 应用程序不需要规范化数据库中的计算值。即时计算这些值将花费更长的时间,从而降低查询执行速度。因此,在反规范化中,查询可以更简单,因为我们需要查看的表更少。 3. 简化和加速报表生成 假设您需要非常频繁地获取某些统计数据。从实时数据生成这些数据需要很长时间,并且会减慢整个系统的速度。假设您想监控任何或所有客户在特定年份的收入。从实时数据生成此类报表将需要“搜索”整个数据库,从而显著降低其速度。 反规范化的缺点反规范化的缺点如下:
反规范化与规范化有何不同?反规范化与规范化的区别如下:
下一主题ER 模型与关系模型 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
