有限自动机字符串匹配2025年1月10日 | 阅读 10 分钟 字符串匹配算法是计算机科学和数据分析中用于在一个字符串(“文本”)中查找另一个字符串(“模式”)的出现或位置的技术。 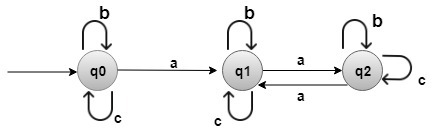 字符串匹配算法- 暴力匹配算法:这是最简单的方法,您将模式与文本的每个子字符串进行比较。
- Knuth-Morris-Pratt (KMP) 算法:KMP 比暴力匹配更有效。它预先编译模式的最长前缀-后缀数组,以避免不必要的比较,从而将总时间复杂度降低到 O(m + n)。
- Boyer-Moore 算法:Boyer-Moore 使用“坏字符”和“好后缀”启发式方法来跳过文本的部分内容,使其在实践中非常高效,尤其适用于长文本和模式。
- Rabin-Karp 算法:Rabin-Karp 使用哈希来快速比较模式与文本的潜在子字符串。其最坏情况下的时间复杂度为 O(m * n),但在某些输入情况下可能非常高效。
- Aho-Corasick 算法:该算法用于同时在文本中搜索多个模式。它构建一个有限自动机并有效地识别所有模式的出现。
- 正则表达式:许多编程语言提供用于字符串匹配的正则表达式库。正则表达式允许基于指定的模式语言进行复杂的模式匹配。
有限自动机类型- 确定性有限自动机 (DFA):在 DFA 中,对于每个状态和输入符号,只有一个转移到另一个状态。这意味着自动机的行为完全由其当前状态和输入符号决定。DFA 常用于识别正则语言等任务,例如文本处理中的简单模式匹配。
- 非确定性有限自动机 (NFA):在 NFA 中,对于给定的输入符号,一个状态可以有多个可能的转移。这种不确定性提供了更大的灵活性,但需要更复杂的算法来处理。NFA 通常用作理论构造,并可以使用幂集构造等算法转换为等效的 DFA。
有限自动机的关键概念和组成部分包括 - 状态:有限自动机有一组有限的状态,代表被建模系统的不同配置或情况。
- 转移:转移定义了自动机如何响应输入符号从一个状态移动到另一个状态。
- 起始状态:这是自动机开始其操作的初始状态。
- 接受(或最终)状态:这些状态表示成功或有效的结果。在某些应用中,到达接受状态表示已识别出特定的模式或输入。
有限自动机在计算机科学中有多种应用,包括 - 编译器设计中的词法分析:识别编程语言中的关键字、标识符和符号。
- 文本处理和搜索中的模式匹配。
- 硬件和软件验证中的模型检查。
- 自然语言处理和解析。
使用有限自动机进行字符串匹配是一种在文本(字符串)中查找模式(子字符串)出现的技术。它包括根据模式构建一个有限自动机(通常是确定性有限自动机或 DFA),然后使用该自动机高效地在文本中搜索模式。 以下是基本步骤 - 构建 DFA:构建一个表示您要搜索的模式的 DFA。该 DFA 将具有基于模式中字符的状态和转移。
- 使用 DFA 进行搜索:从 DFA 的初始状态开始,逐个处理文本中的每个字符。根据遇到的字符遵循 DFA 中的转移。
- 找到匹配:如果在处理文本时到达 DFA 中的接受状态,则表示在文本中找到了模式的匹配。
与暴力匹配等朴素方法相比,这项技术可以显著加快字符串匹配的速度,尤其是在对多个文本搜索相同模式时。 请记住,构建 DFA 的时间复杂度可能为 O(m*|Σ|),其中“m”是模式的长度,“|Σ|”是字母表的大小,但一旦构建了 DFA,在文本中搜索模式就非常高效,通常时间复杂度为 O(n),其中“n”是文本的长度。 字符串匹配算法的实际应用- 文本搜索:在 Google 等搜索引擎中,当您输入查询时,字符串匹配算法用于快速扫描数十亿个网页,并识别出包含您输入的字符确切或近似字符串的网页。这些算法通常会实现诸如索引之类的优化,通过预先排序和组织数据来加快搜索过程。
- 数据检索:在数据库管理系统中,字符串匹配可用于带有 LIKE 运算符的 SQL 查询,以检索与指定模式匹配的记录。例如,您可以使用 SELECT * FROM Customers WHERE LastName LIKE 'Sm%' 来检索姓氏以“Sm”开头的客户。字符串索引和哈希技术被用来提高此类操作的效率。
- 拼写检查和更正:拼写检查器使用字符串匹配将输入的单词与正确拼写的单词词典进行比较。算法根据在词典中找到的最接近的匹配项建议更正。Levenshtein 距离(一种字符串距离度量)通常用于衡量两个字符串之间的相似性并据此推荐更正。
- 模式识别:在 DNA 序列分析中,字符串匹配对于识别 DNA 序列中的特定模式(如基因或调控元件)至关重要。在图像处理中,字符串匹配可用于检测图像中的模式或模板,从而有助于对象识别等任务。
- 正则表达式:正则表达式是用于字符串模式匹配和文本操作的强大工具。它们在编程语言和文本编辑器中用于搜索、提取和替换与指定模式匹配的文本等任务。
- 网络安全:入侵检测系统使用字符串匹配将网络流量与已知的攻击模式或签名进行比较。如果找到匹配项,它可能会触发警报或采取措施来缓解威胁。基于签名的防病毒软件还使用字符串匹配来识别文件中的恶意软件签名。
- 生物信息学:在生物信息学中,字符串匹配用于序列比对。Smith-Waterman 和 Needleman-Wunsch 等算法比较生物序列(DNA、RNA、蛋白质)以查找相似性,这可以揭示进化关系和功能基序。
- 网页抓取:网页抓取工具使用字符串匹配来定位网页 HTML 源代码中的特定元素。
- 地理信息系统 (GIS):GIS 应用程序使用字符串匹配来搜索地理数据,例如地点、地标或地址。这有助于用户在地图上查找和分析空间信息。
- 音乐识别:在音乐分析中,字符串匹配可用于将短的音乐模式(如旋律或和弦进行)与已知音乐模式数据库进行比较。这通常用于音乐识别应用程序以识别歌曲或提供和弦建议。
有限自动机字符串匹配的复杂性使用有限自动机进行字符串匹配是一种高效且广泛使用的技术,其计算复杂性相对较低,尤其是在预处理模式以创建有限自动机时。关键优势在于模式预处理仅执行一次,从而使后续在文本字符串中的搜索速度非常快。 1. 预处理(构建有限自动机) 时间复杂度:O(m^3 * |Σ|),其中 m 是模式的长度,Σ 是字母表(可能的字符集)。 空间复杂度:O(m * |Σ|),其中有限自动机需要与模式大小和字母表大小成比例的空间。 实际上,由于 Aho-Corasick 算法等优化或有限自动机的有效表示,实际的时间和空间复杂度可能更低。 2. 搜索(使用有限自动机) 时间复杂度:O(n),其中 n 是文本字符串的长度。 空间复杂度:O(1),因为内存要求不取决于输入文本的大小。 关键在于,搜索(使用有限自动机)的时间复杂度与文本字符串的长度呈线性关系。这对于在不同文本字符串上使用相同模式进行多次搜索的字符串匹配来说是一个显着的优势,因为预处理步骤仅执行一次。 字符串匹配的有限自动机优于其他算法- 确定性和简洁性:DFA 是简单且确定性的状态机,易于理解和实现。这种简洁性带来了更短的代码和更少的实现错误可能性。
- 高效的预处理:DFA 具有一个预处理步骤(构建自动机),其时间复杂度为 O(m^3 * |Σ|),其中 m 是模式的长度,Σ 是字母表。虽然在预处理阶段这看起来比某些其他算法慢,但它是一次性成本。一旦构建了自动机,在多个文本字符串中搜索模式就非常高效,每次搜索的时间复杂度为 O(n),其中 n 是文本的长度。这在需要对多个文本搜索相同模式的场景中尤其有利。
- 内存效率:有限自动机的内存复杂度为 O(m * |Σ|),用于存储自动机,这相对较低,并且不取决于输入文本的大小。相比之下,Boyer-Moore 算法等其他算法需要额外的内存来构建用于模式预处理的辅助数据结构。
- 确定性搜索时间:使用有限自动机的搜索时间是确定性的,并且与文本长度呈线性关系。在最坏情况下,会检查整个文本,但没有回溯或可能导致搜索时间变为二次的最坏情况。
- 并行性:由于文本中的每个字符都可以独立处理,因此有限自动机可以有效地并行化。这使其适用于并行处理架构和多核 CPU。
- 处理多个模式:通过构建一个识别所有模式的单个自动机,有限自动机可以有效地同时搜索多个模式。
- 固定模式匹配:当您搜索固定模式(不经常更改的模式)时,有限自动机特别有用,因为预处理成本可以分摊到多次搜索中。
有限自动机在字符串匹配中的局限性- 有限的内存:有限自动机有有限数量的状态,它们根据输入字符从一个状态转换到另一个状态。一旦处理了一个字符并且自动机转换到新状态,它通常会忘记以前的状态。这种缺乏内存意味着有限自动机无法记住有关过去字符或它们在输入字符串中的位置的信息。
- 无法处理复杂模式:有限自动机非常适合识别简单模式或正则语言。它们在识别字符串是否遵循特定正则表达式模式(例如,识别有效的电子邮件地址或电话号码)等任务方面表现出色。但是,对于需要记住先前字符或匹配嵌套构造(例如,平衡括号)的更复杂模式或语言,有限自动机是不够的。
- 表达能力有限:有限自动机只能识别正则语言,它是形式语言层级的一个子集。与上下文无关、上下文敏感和递归可枚举语言相比,正则语言在表达能力上受到限制。这意味着有限自动机无法处理某些需要上下文敏感或上下文无关规则的高级字符串匹配任务。
- 性能限制:对于模式具有多种可能变体或长模式的字符串匹配任务,DFA 的状态数或 NFA 的转移数可能会显着增加。这可能导致具有许多状态和转移的大型自动机,这可能会增加内存和处理时间要求。
- 仅精确匹配:有限自动机主要用于精确字符串匹配,其目标是确定给定字符串是否与指定模式完全匹配。它们不适合需要近似匹配或模糊匹配的任务,这些任务需要容忍输入字符串中的细微差异或错误。
- 构建自动机的复杂性:为某些字符串匹配任务构建 DFA 或 NFA 可能很困难,并且需要深入理解正则表达式和自动机理论。为复杂模式创建自动机可能会导致状态图变得复杂且难以维护。
字符串匹配的有限自动机替代方案- 正则表达式:正则表达式(regex)是模式匹配的强大工具。它们使用语法来指定可以匹配字符串的模式。Regex 引擎的效率可能有所不同。简单模式可以快速匹配,但复杂模式或过度回溯的模式可能会导致性能问题,尤其是在处理大型输入时。
- Knuth-Morris-Pratt (KMP) 算法:KMP 算法是一种用于精确字符串匹配的高效算法。它使用预处理的模式在匹配期间跳过不必要的比较。KMP 的时间复杂度为 O(m + n),其中 m 是模式的长度,n 是输入字符串的长度。它表现良好,尤其适用于长模式。
- Boyer-Moore 算法:Boyer-Moore 算法是另一种用于精确字符串匹配的高效算法。它在匹配期间使用启发式方法在输入字符串中向前跳过。Boyer-Moore 对于搜索长度为 n 的字符串和长度为 m 的模式,其平均情况时间复杂度为 O(n/m)。在实践中,它表现得非常好,尤其适用于较长的模式。
- Rabin-Karp 算法:Rabin-Karp 算法使用哈希来高效地在文本中搜索模式。它也可以适应近似匹配。Rabin-Karp 对于搜索长度为 n 的字符串和长度为 m 的模式,其平均情况时间复杂度为 O((n-m+1)m)。对于某些模式和输入,其性能可能与其他算法具有竞争力。
- Aho-Corasick 算法:Aho-Corasick 算法专为多模式字符串匹配而设计,允许多个模式同时搜索。Aho-Corasick 的时间复杂度为 O(n + z + m),其中 n 是输入字符串的长度,m 是模式的总长度,z 是找到的匹配数。对于多模式匹配任务,它很高效。
- Trie 数据结构:Trie 是一种树状数据结构,用于基于字典的字符串匹配,通常用于拼写检查或自动完成。Trie 对于基于字典的匹配很高效,搜索长度为 m 的字符串的时间复杂度为 O(m)。当模式中存在许多公共前缀时,它们可以节省空间。
- 后缀树和后缀数组:后缀树和后缀数组是用于各种字符串处理任务(包括字符串匹配)的多功能数据结构。它们可以支持高效的子字符串搜索、近似匹配和其他高级字符串算法。它们的构建可能需要 O(n) 的时间和空间,但它们能够对各种字符串处理任务进行高效的查询。
| 