C语言数据结构与算法 | 第一部分2025年3月17日 | 阅读 12 分钟 数据结构-数组、动态数组和链表DSA 是任何编程语言中非常重要的概念。假设我们有很多书,我们需要一个书架来整理所有书。我们会先检查有多少本书,然后我们会假设未来可能还会买多少本书。然后,我们会考虑一个合理的预算来购买书架。我们会检查哪些书架坚固且寿命长。最后,我们会买最好的一个。 在编程中,**书本指的是我们在编写代码时需要处理的海量数据,我们正在编写的程序就是房间**,而在我们的程序中,**我们需要找到一个好的存储位置来高效地整理所有数据**。杂乱的房间永远不是好事。 在这个系列教程中,我们将涵盖 C 语言中的所有数据结构,然后是另一个主题-算法。 数据类型和数据结构这两个词可能都有“数据”这个词,但它们并不相同。简单来说,我们可以说**数据类型是变量的特征**。它表示特定变量可以存储哪种类型的数据/值。C 语言是一种静态语言。因此,我们需要在使用程序中的每个变量之前声明它的数据类型。 **另一方面,数据结构是由不同数据类型的数据组成的集合和组织方式,我们可以从中处理和检索数据**。它涉及数据在计算机内存中的排列。 int、float 等是数据类型,栈、队列等是数据结构的例子。 C 语言中有不同类型的数据结构。我们需要学习它们,以便知道何时需要使用哪种数据结构。 下图是根据变量的组织方式在 C 语言中进行分类的流程图 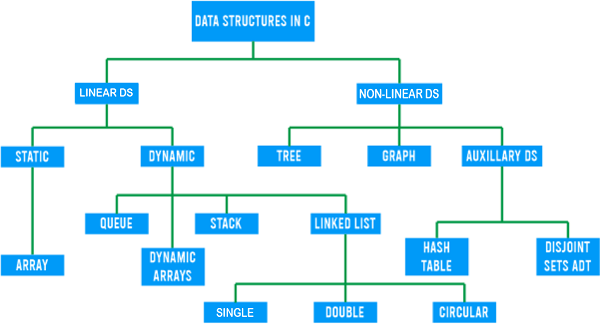 术语
事实
数组数组是位于连续内存位置的同构元素集合。可以使用索引(0 到 size-1)访问数组的元素。它可以是多维的。它可以存储基本数据类型和派生数据类型的元素,但所有元素都必须属于同一数据类型。创建数组的目的是用一个名称表示多个相同数据类型的元素。 基本语法 注意事项
这是一个包含数组所有基本操作的程序 输出 a[5] = 10 20 30 40 50 Out of index a[5]: 0 Array elements are stored in contiguous locations: 000000000062FDF0 000000000062FDF4 000000000062FDF8 000000000062FDFC 000000000062FE00 Pointer indication: a[0] = 10 *a = 10 Traversing using pointer: 10 20 30 40 50 By commutative property a[i] = i[a] = a[2] = 30 2[a] = 30 Multi-dimensional array(4 X 4): 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Sum of elements of b[5] = 15 Sorting the array x: 1 2 4 7 9 -------------------------------- Process exited after 0.8778 seconds with return value 2 Press any key to continue . . . 链表链表是一种线性数据结构,与数组类似,但元素不是存储在连续的内存位置。链表中的每个节点/元素有两个部分-一个包含数据,另一个包含指向下一个节点位置的指针。这些指针将节点连接起来,形成一个线性链表。第一个节点的地址存储在 head 中。 注意事项
在 C 语言中,链表是使用结构创建的,它也与数组一样是同构的,这意味着它的节点只能存储相同数据类型的数据。  一个简单的链表如下所示  如上图所示,head 是第一个节点,最后一个节点的 next(引用)部分持有 None。 双向链表如下所示  在双向链表中,每个节点将有三个部分。Head 持有第一个节点的引用,第一个节点的“previous”部分持有 None,最后一个节点的 next 字段指向 None。每个节点将持有两个引用以及数据,一个指向其前一个节点,一个指向后继节点。 循环链表循环链表可以是单向的或双向的 单向循环链表  这是一个单向链表,但列表中的最后一个节点像一个圆一样持有第一个节点的引用。 双向循环链表  这是一个双向链表,但列表中的最后一个节点持有第一个节点的引用,并且第一个节点的“previous”部分持有最后一个节点的引用,就像一个圆一样。 这里有一个程序,展示了我们可以对单向链表执行的一些基本操作 输出 The created Linked List: HEAD -> 1 -> 2 -> 3 -> NULL Insertions: After inserting 5 at the beginning: HEAD -> 1 -> 2 -> 3 -> NULL -----> HEAD -> 5 -> 1 -> 2 -> 3 -> NULL After inserting 10 after 2 node: HEAD -> 1 -> 2 -> 3 -> NULL ----> HEAD -> 1 -> 2 -> 10 -> 3 -> NULL After inserting 17 at the end: HEAD -> 1 -> 2 -> 10 -> 3 -> NULL ----> HEAD -> 1 -> 2 -> 10 -> 3 -> 17 -> NULL Deletions: After deleting the 1st node: HEAD -> 1 -> 2 -> 10 -> 3 -> 17 -> NULL ----> HEAD -> 2 -> 10 -> 3 -> 17 -> NULL After deleting the last node: HEAD -> 1 -> 2 -> 10 -> 3 -> 17 -> NULL ----> HEAD -> 1 -> 2 -> 10 -> 3 -> NULL After deleting node from 3 position: HEAD -> 1 -> 2 -> 10 -> 3 -> NULL ----> HEAD -> 1 -> 2 -> 3 -> NULL 动态数组一旦声明了一个数组,它的size就会固定。这是一个缺点,因为我们可能在运行时需要更多的内存。因此,引入了动态数组。
有 4 个内置的动态内存分配函数可用 1. malloc()
2. calloc()
在 malloc() 和 calloc() 中,内存都是在一个地方连续分配的。因此,可以创建动态数组。 这是一个示例程序,展示了 malloc() 和 calloc() 分配之间的区别 输出 Enter the number of elements in the first D-array: 5 Enter the number of elements in the second D-array: 5 Initial values: By malloc(): 11901584 0 11862352 0 1936028257 By calloc(): 0 0 0 0 0 Memory allocations: By malloc(): 11867904 11867908 11867912 11867916 11867920 By calloc(): 11867936 11867940 11867944 11867948 11867952 3. free()
4. realloc()
假设我们创建了一个大小为 n 的常规数组,并且我们决定在运行时不需要第一个元素。我们将所有元素向左移动,移除第一个元素。这不会改变数组的大小,空位永远不会消失。 对于动态数组,我们可以使用 realloc() 来收缩数组。这里有一个演示此现象的示例 输出 Enter the size: 6 The memory allocations in a regular array: 6487264 6487268 6487272 6487276 6487280 6487284 The memory allocations in the dynamic array: 12130048 12130052 12130056 12130060 12130064 12130068 After removing the first element: Regular array: 6487264 6487268 6487272 6487276 6487280 6487284 Dynamic array: 12130048 12130052 12130056 12130060 12130064 -------------------------------- Process exited after 2.795 seconds with return value 1 Press any key to continue . . .
结论这是关于 C 语言数据结构与算法的第一个教程。 在本教程中,我们涵盖了
实现了带有所有基本操作和解释的程序,以便更好地理解。在下一个教程中,我们将继续学习栈和队列。 下一主题C语言数据结构与算法|第二部分 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
