Amazon SageMaker Python SDK入门2025年4月11日 | 阅读 6 分钟 AWS 上的 SageMaker Python SDK用于创建解决方案的建议库是来自 Amazon 的 SageMaker Python SDK。AWS Web 门户、Boto3 和 CLI 是与 SageMaker 通信的其他方法。 原则上,SDK 应该提供最佳的开发体验,然而我发现立即上手需要一个学习过程。 本文将通过一个简单的回归任务演示关键的 SDK API。 回归任务:预测燃油消耗我选择了一个回归任务,并将问题分解为三个阶段:
将工件存储在 S3 中可确保其可被方便地重用、共享或部署。 SageMaker 准备和指令S3 和 Docker 容器是 SageMaker 中两个主要组件。S3 既是训练工件(如模型)的导出目的地,也是训练数据的主要存储库。预处理器和 Estimator 是 SDK 提供的用于预处理数据和训练模型的核心接口。这两个 API 都是 SageMaker Docker 容器的包装器。当使用 Preprocessor 创建预处理任务或使用 Estimator 创建训练作业时,内部会发生以下情况:
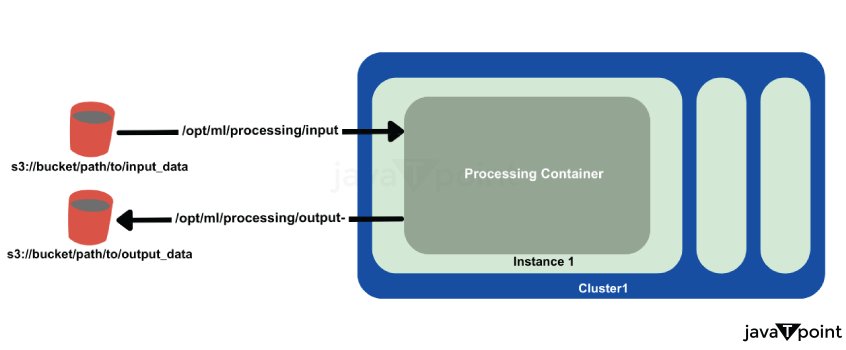 SageMaker 预处理容器以下图示了到预处理容器和从预处理容器的数据传输。 SageMaker 容器 熟悉 SageMaker 容器中的环境变量和预定义路径至关重要。 容器内的关键路径包括:
项目文件夹结构下图描绘了项目文件夹结构。主脚本是 Python Notebook auto_mpg_prediction.ipynb,其单元格在 SageMaker Studio 中执行。训练和预处理脚本位于 scripts 文件夹中。 初始操作首先,让我们初始化一个 SageMaker 会话,然后执行获取默认存储桶、执行角色和区域所需的样板操作。还为重要的 S3 位置创建了前缀,以便数据可以存储在那里,并且可以导出预处理的特征和模型。 输出 Region: us-west-2 Bucket: <bucket-name> Role: arn:aws:iam::123456789012:role/service-role/AmazonSageMaker-ExecutionRole 说明 为了执行 SageMaker 操作,此代码初始化了一个 SageMaker 会话,并获取了必要的配置信息,包括 AWS 区域、默认 S3 存储桶和 IAM 执行角色。它指定了 S3 中用于存储原始数据和预处理数据的路径,并提供了辅助函数 get_s3_path() 来即时创建完整的 S3 URL。此配置确保了 SageMaker、S3 和其他 AWS 服务之间的无缝连接。 将原始数据传输到 S3下一步是将我们的原始数据移动到 S3。在生产环境中,ETL 操作通常会将 S3 存储桶指定为最终数据目的地。下面的函数用于获取原始数据,将其分为测试集、验证集和训练集,然后将每个集合上传到默认存储桶中的相应 S3 URL。 输出 Uploaded train.csv to s3://<bucket-name>/auto_mpg/data/bronze/train/ Uploaded val.csv to s3://<bucket-name>/auto_mpg/data/bronze/val/ Uploaded test.csv to s3://<bucket-name>/auto_mpg/data/bronze/test/ 说明 此函数使用指定的会话和存储桶位置,下载 MPG 数据集,使用训练-验证-测试方法进行拆分,并将每个拆分发布到 S3。为了有效地管理空间,它在上传后会删除本地文件。 阶段 1:特征工程预处理步骤使用 Scikit-learn 库实现。此阶段的目标是:
SageMaker Python SDK 提供了 Scikit-learn Preprocessors 和 PySpark Preprocessors,它们都预装了 Scikit-learn 和 PySpark。然而,我发现无法同时使用自定义脚本或依赖项,因此我使用了 Framework Preprocessor。 为了使用 Scikit-learn 库实例化 Framework Preprocessor,我将 Scikit-learn Estimator 类提供给了 estimator_cls 参数。Preprocessor 的 .run 方法包含一个 code 参数,用于指定入口点脚本,还有一个 source_dir 参数,用于指示包含所有自定义脚本的目录。 请注意,使用 ProcessingInput 和 ProcessingOutput API 如何将数据传入和传出预处理容器。此处指定了容器 (/opt/ml/*) 和用于数据传输的 S3 路径。请注意,与使用 .fit 方法执行的 Estimators 不同,Preprocessors 使用 .run 方法。 输出 Job started. Path to preprocessed train features: s3://<bucket-name>/auto_mpg/data/gold/train/train_features.npy Path to saved preprocessor model: s3://<bucket-name>/auto_mpg/models/preprocessor/preprocessor-<timestamp>.joblib 说明 此代码使用 Scikit-learn 容器实例化 SageMaker FrameworkProcessor,以执行自定义预处理作业。它将 S3 中的未处理数据导入容器,在其上运行脚本,然后将模型工件和预处理的特征导出回 S3。 阶段 2:模型训练训练过程类似于预处理步骤,利用了 SDK 中的 Estimator 类。我决定在此回归任务中使用 XGBoost 算法。 训练模型 本示例侧重于 XGBoost 算法的超参数调优。在定义了超参数后,我们可以实例化 XGBoost Estimator 并继续模型训练。 输出 Training complete! Model artifacts can be found at: s3://<bucket-name>/auto_mpg/models/ml/xgboost-<timestamp>/output/model.tar.gz 说明 此代码使用角色、实例类型、输出路径、源目录、训练脚本和超参数,在 SageMaker 中初始化了一个 XGBoost Estimator。接下来,它使用 S3 中的预处理数据来训练模型。训练完成后,训练好的模型将被保存到指定的 S3 存储中。 阶段 3:模型推理为了测试我们训练好的模型,我们将调用一个 SageMaker Predictor,该 Predictor 使用提供的测试数据向推理端点发送请求。 输出 Predictions: [21.5, 19.2, 24.3, ...] 说明 对于实时预测,此代码使用 SageMaker Predictor 调用 "xgboost-endpoint" 端点。输入数据以 CSV 格式序列化发送,并打印出预期值,例如 [21.5, 19.2, 24.3,...]。 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
