使用OpenCV-Python进行行人检测2025年4月11日 | 阅读 8 分钟 行人检测是几乎所有现代应用的关键组成部分,包括自动驾驶汽车或城市安全系统。由于行人检测涉及诸如尺寸变化等操作,OpenCV 中丰富的特性使得在利用 Python 绑定进行有效检测成为可能。CV 开发者现在可以设计在实时和高效率参数内运行的解决方案,从而应用 OpenCV。在本节中,我们将解释基本技术,并说明行人检测中涉及的潜在困难以及 OpenCV-Python 的改进。 识别行人的主要策略对于任何行人检测方法来说,一个具有挑战性的任务是,有许多因素会影响行人的外观,例如一个人的服装、遮挡、天气条件和光照。使用 OpenCV 进行行人检测主要有两种方法: 经典方法过去,行人检测是通过手动设计的特征和分类器来执行的。OpenCV 提供了几种经典的行人检测方法,在需要低计算容量的应用中可以使用。这些方法包括: 1. 方向梯度直方图 (HOG) HOG 描述符表示图像的梯度,以寻找物体的形状和结构;然而,它在检测行人时最有效。HOG 算法将图像分解为单元格,计算单元格内容的梯度直方图,并缩放结果直方图。图像的所有单元格信息被累积起来以描绘图像。当与 SVM(支持向量机) 分类器集成时,它可以成功地识别行人。 2. Haar 级联 Haar 级联是另一种经典的物体检测方法,常用于人脸检测。例如,OpenCV 有一个用于检测行人的 Haar 级联分类器,但它已经预先训练好。它通过对图像使用滑动窗口方法来工作,然后将每个窗口分离出来以确定它是否包含行人。然而,与当今的 深度学习 技术相比,Haar 级联速度相对较慢,精度也较低。尽管有效,但 Haar 级联通常比现代的基于深度学习的方法慢且精度较低。 基于深度学习的方法目前,随着深度学习的发展,行人检测变得更加高效。尽管 OpenCV 支持集成 ML 模型,但这些模型在复杂环境中表现出优越的性能。一些著名的模型包括: 1. YOLO (You Only Look Once) YOLO 是一个实时强大的物体检测模型,可以在一帧中检测出行人等多个物体。特别是 YOLO,它将图像分割成一个网格,对于网格中的每个单元格,它会预测以下内容:物体的边界框和类别概率。该方法以其更快、更高效的计算而闻名,因此适用于自动驾驶汽车等需要实时功能的应用程序。 2. SSD (Single Shot Multibox Detector) SSD 是另一种实时且非常准确的物体检测模型,能够检测行人。它使用的机制是在不同尺度的图像上使用 卷积神经网络(CNN) 来发现不同大小的物体。特别是,在图像中有小型行人或背景行人时,SSD 表现良好。 3. Faster R-CNN Faster R-CNN 是一个两阶段的物体检测方法。首先,它建议行人可能存在的区域,然后它进一步预测这些区域的边界框。 OpenCV 与深度学习模型的集成cv2.dnn 是 OpenCV 的深度学习模块,允许加载和运行在 TensorFlow、Caffe 和 PyTorch 中训练的模型。这种灵活性使得开发者能够将当前最先进的模型集成到他们的 OpenCV 代码中进行行人检测。例如,你可以使用 YOLO 或 SSD(一个流行的深度学习物体识别模型),并结合 OpenCV 来运行实时行人检测。 在 OpenCV 中实现基于深度学习的检测步骤步骤 1:加载预训练模型 值得一提的是,你可以使用 cv2.dnn.readNet() 函数将几乎任何神经网络(如 YOLO 或 SSD)加载到 OpenCV 中。Caffe、TensorFlow 等格式都得到支持,并且 OpenCV 附带这些格式以配合预训练模型使用。 步骤 2:准备图像/帧 预处理图像对于深度学习模型至关重要。使用 OpenCV 的 cv2.dnn.blobFromImage() 函数将输入帧调整到所需大小,标准化像素值,并将图像转换为正确的格式。 步骤 3:运行推理 预处理后,下一步是执行推理(检测)。使用 net.forward() 将输入通过深度学习模型运行,并获取输出预测,包括边界框、类别 ID 和置信度分数。 步骤 4:后处理 一旦做出预测,就会应用非极大值抑制(NMS)等后处理步骤来删除重复的检测,并只保留最相关的边界框。 使用 OpenCV 在 Python 中实现行人检测程序现在我们将查看下面一段代码,演示如何使用 OpenCV 模块在 Python 中实现行人检测程序。 代码 输出 Requirement already satisfied: opencv-python in /usr/local/lib/python3.10/dist-packages (4.10.0.84) Requirement already satisfied: opencv-python-headless in /usr/local/lib/python3.10/dist-packages (4.10.0.84) Requirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (1.26.4) i2.jpg i2.jpg(image/jpeg) - 145520 bytes, last modified: 11/22/2024 - 100% done Saving i2.jpg to i2.jpg 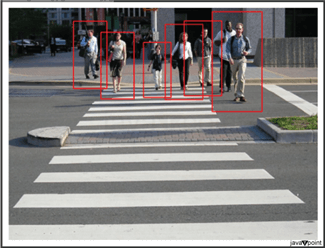 说明 安装和导入库
上传和读取图像
显示图像颜色的转换
设置行人检测器
检测行人
绘制边界框
显示输出
实时检测优化为了实现 OpenCV 的实时行人检测,可以应用几项优化:
行人检测在各行业的应用1. 自动驾驶汽车 这是自动驾驶汽车在道路上与众多行人安全行驶所必需的。特别是,行人的实时识别使汽车能够避免事故并提高道路安全。 2. 监控和安全系统 在公共集会区域、限制进入的敏感区域或甚至被隔离的区域,行人检测在监控人群、观察任何可疑人员或识别任何不安全角色方面都可能非常有用。当与面部识别或跟踪结合时,它成为安全方面不可或缺的工具。 3. 医疗保健、日常护理和辅助生活 通过使用行人检测,可以有效地观察有特殊需求的患者,例如老年人,并在需要时给予他们及时的关注。 4. 零售和营销 在零售场景中,行人检测可以计算访客数量并评估人流量模式,从而微调商店布局和设计,增强顾客体验,并分析商店的受欢迎程度。 面临的挑战尽管行人检测取得了进展,但在实际应用中仍有几项挑战需要解决:
结论行人检测程序采用 OpenCV HOG + SVM 检测功能,该功能经过预训练,通过在检测到的图像周围绘制边界框来区分行人。它们接收输入图像,进行分析,识别人的形状,并显示结果,这使其非常适合安全系统和监控摄像头等实际应用。 通过理解底层技术、解决挑战和应用优化,开发人员可以构建强大而高效的系统,用于各种领域的实时行人检测。随着行人检测技术的不断发展,将机器学习和人工智能集成到基于 OpenCV 的系统中只会提高它们的准确性和功能。 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
