Python中的正则表达式后顾2025年1月5日 | 阅读 7 分钟 正则表达式,通常简称为 regex,是计算机科学中用于基于模式搜索和操作文本的强大工具。在 Python 中,`re` 模块提供了处理正则表达式的支持。 正则表达式是由字符组成的序列,用于定义搜索模式。此模式可以包含字面字符,例如字母或数字,以及在正则表达式语法中具有特殊含义的特殊字符。例如,`.` 字符匹配任何单个字符,`*` 匹配前一个字符的零个或多个出现,`d` 匹配任何数字。 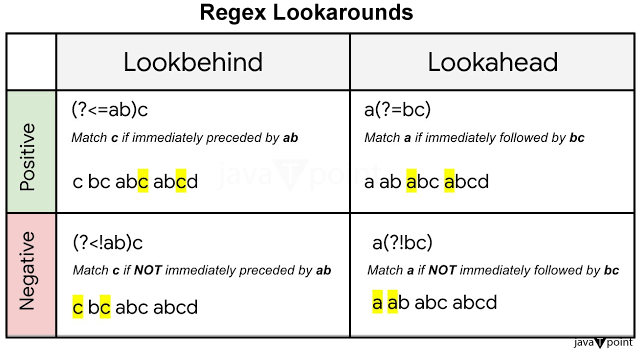 要在 Python 中使用正则表达式,您首先需要使用 `re.compile()` 函数编译模式,该函数返回一个正则表达式对象。然后,您可以使用此对象的各种方法在字符串中搜索匹配项、提取匹配的子字符串或执行替换。 `re.search()` 函数搜索字符串中模式的第一次出现,如果找到则返回一个匹配对象。`re.findall()` 函数返回字符串中模式的所有非重叠匹配项的列表。其他有用的函数包括 `re.match()`(匹配字符串开头处的模式)、`re.split()`(基于模式拆分字符串)和 `re.sub()`(将模式的出现替换为目标字符串)。 正则表达式用途广泛,可用于各种任务,包括验证输入、从文本中提取信息或基于模式转换文本。但是,它们也可能很复杂且难以理解,特别是对于复杂的模式。重要的是要明智地使用它们并彻底测试它们,以确保它们按预期运行。 总而言之,Python 中的正则表达式提供了一种强大的处理文本数据的方法,可以实现基于模式的灵活高效的文本处理。 正则表达式的后行断言是 Python 正则表达式引擎中的一项功能,它允许您指定一个需要被另一个模式预先存在的模式。当您只需要匹配前面有特定字符序列的模式,但又不想将这些字符包含在匹配项中时,后行断言非常有用。 Python 的正则表达式中有两种后行断言:
以下是每种类型的解释及示例: 正向后行断言 `(?<=...)`正向后行断言断言括号内的模式必须由后行断言中指定的模式预先存在。但是,它不将后行模式包含在匹配项中。 示例 输出 ['and', 'too'] 说明
在此示例中,正向后行断言可确保仅匹配 "sunny" 后面的单词,而不将 "sunny" 本身包含在结果中。 负向后行断言 `(?<!...)`负向后行断言断言括号内的模式不得由后行断言中指定的模式预先存在。 示例 输出 ['apple', 'banana', 'orange'] 说明
在此示例中,负向后行断言确保只匹配前面不是 "green" 的单词。 局限性
总之,Python 中的正则表达式后行断言是基于前导字符或模式匹配的强大工具。它们允许您定义复杂的匹配条件,而不将前导字符包含在匹配项中。但是,重要的是要注意它们的局限性,并在正则表达式中明智地使用它们。 应用
正则表达式先行断言与后行断言的区别正则表达式先行断言
正则表达式后行断言
关键区别
下一主题Python 中的日程库 |
简介 一个世纪以来,数学家和计算机科学家一直着迷于构成数学世界的素数。“Isprime()”是 Python 编程世界中使用的重要函数,对于轻松查找素数是必需的。这篇详细的文章讨论了...
阅读 3 分钟
在接下来的教程中,我们将讨论用于管理 Python 项目的项目模板。但在我们开始之前,让我们简要了解一下什么是项目模板以及使用项目模板的优势。什么是项目模板?项目模板是预定义的...
阅读 4 分钟
自然语言处理是一个领域,其中人类和机器可以以我们日常生活中通常使用的常规人类语言的形式进行交互。早些时候,我们习惯于用高级语言进行交流,该语言被转换为机器语言,以便...
阅读 8 分钟
Python 中的列表是什么?列表是一种可以存储多个元素的数据类型。我们可以使用方括号 `[]` 包围的变量来定义列表。数据项之间用逗号分隔。水果列表可以是...
阅读 4 分钟
简介 使用 os 和 shutil 模块,可以在 Python 中有效地重命名多个文件。首先,创建一个需要重命名文件名的列表。然后,使用 os.rename() 或 shutil.move() 等函数,对列表进行迭代重命名。两者...
阅读 4 分钟
简介:BeautifulSoup 是一个专为网页抓取而设计的 Python 库,是解析 HTML 和 XML 文档的强大工具。其核心功能之一是能够导航和提取文档树中的信息。在使用 BeautifulSoup 时,用于此目的的两个常用方法是...
阅读 3 分钟
介绍 Python 中的邻域变量在特性内部被描述,并且只能在该特性内部访问。在调用该特性后,它会被创建,并在该特性结束后被销毁。特性体内的变量,...
阅读 6 分钟
? 什么是 SystemExit 异常? Python 中的 SystemExit 异常是由 sys.exit() 功能开发出来的一种特殊情况。它是 BaseException 类的子类,表示 Python 解释器退出的请求。在此处...
11 分钟阅读
简介:在本教程中,我们将学习有关. 图像归一化是改变图像像素值的过程,以使图像更令人满意。图像归一化用于增加图像之间的对比度,有助于改进...
7 分钟阅读
简介 Python 字节码反汇编是 Python 编程中一个有趣的部分,它允许设计者深入了解 Python 代码的内部工作原理。字节码是 Python 解释器执行的 Python 代码的低级、平台无关的表示。虽然 Python 设计者通常...
阅读 13 分钟
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
