YOLO:你只看一次 - 实时物体检测17 Mar 2025 | 4 分钟阅读 目标检测这是一项计算机视觉任务,用于对视频或图像中的对象进行分类和识别。这种目标检测算法主要可分为两种类型。
 单阶段检测器单阶段检测器(一次只看一遍)使用完整的 CNN 来处理图像。在此过程中,它仅使用一次通过来做出预测并识别对象的。与其他方法相比,其准确性较低。 双阶段检测器双阶段检测器使用两次输入图像通过,并对对象的存在和位置做出预测。这具有更高的准确性。考虑到准确性,通常单阶段检测器用于实时应用;而双阶段检测器则用于需要更高准确性的场景。 什么是 YOLO? YOLO 是一种用于目标检测的卷积神经网络(CNN)算法。与其他目标检测算法不同,YOLO 不需要区域提议或多个阶段。相反,它将输入图像划分为一个网格,并为每个网格单元预测边界框和类别概率。这使其比其他目标检测算法更快、更有效。它使用单阶段方法来预测输入图像中对象的边界框和类别概率。 YOLO V2它于 2016 年推出,是 YOLO 算法的更新版本。它也称为 YOLO9000,旨在实现更快的速度和更高的准确性。使用锚框是 YOLO v2 的主要升级之一。具有不同纵横比和尺度的边界框集合称为“锚框”。YOLO v2 通过组合锚框和预测的偏移量来创建最终边界框,从而进行边界框预测。因此,该算法可以处理更大范围的项目大小和纵横比。 YOLO v2 的另一个发展是引入了批量归一化,这有助于提高模型的准确性和稳定性。YOLO v2 中的另一项技术是多尺度训练,它包括在不同尺度的图像上训练模型并平均预测。这提高了对小型目标检测的有效性。 以下是 YOLO v2 与原始模型和其他现代模型相比所产生的发现。  YOLO V3它是 YOLO V2 的升级版本,于 2018 年推出,旨在提高算法的速度和准确性。它使用一种称为 Darknet-53 的新卷积神经网络架构。具有不同尺度和纵横比的锚框是 YOLO v3 的一个特点。由于 YOLO v2 中的锚框大小相同,算法在检测不同大小和形状的对象时遇到了困难。为了更好地匹配检测到的对象的尺寸和形状,YOLO v3 更改了锚框的纵横比和尺度。 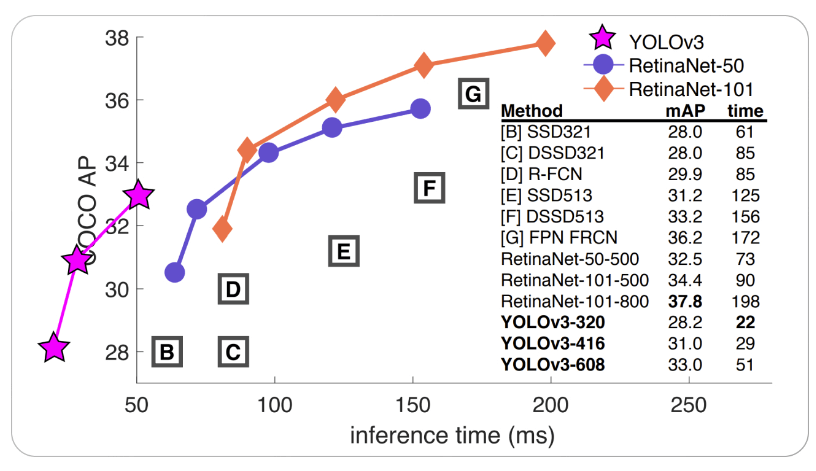 YOLO V4它是 YOLO 的第四个版本,由 Bochkovskiy 等人在 2020 年提出。与 YOLO v3 相比,YOLO v4 的主要进步是使用了称为 CSPNet(下图所示)的新 CNN 架构。“Cross Stage Partial Network”的首字母缩写是指一种专门为目标检测任务创建的 ResNet 变体。它具有相对较浅的结构,只有 54 个卷积层。然而,它可以在多个目标检测基准上产生最先进的结果。  两者都使用锚框,但具有不同的尺度以更好地匹配所检测对象的尺寸和形状,并且 YOLO V4 引入了“k-means 聚类”,两者都使用相似的损失函数,而 YOLO V4 提出了一个名为“GHM loss”的新损失函数。 YOLO V5它由开发 YOLO 算法的同一团队构建。基于先前版本的成功,此版本添加了额外的更新功能。与 YOLO 一样,YOLOV5 使用 EfficientDet 架构,该架构基于 EfficientNet 且更复杂,因为它能获得更高的准确性。YOLO V4 和 YOLO V5 使用相似的损失函数;然而,YOLO V5 引入了“CIoU loss”来提高模型性能。  YOLO V6YOLO V6 由 Li 等人在 2022 年推出,YOLO VS 使用 EfficientDet 架构。YOLO V6 使用 EfficientNet-L2。这是 YOLO V5 和 YOLO V6 之间的唯一区别。  YOLO V7YOLO 的最新版本,即第七个版本,在早期版本的基础上进行了多项改进。使用锚框是关键改进之一。 锚框是一组具有不同纵横比的预设框,用于识别各种形状的对象。YOLO v7 使用九个锚框,比早期版本可以检测到更多种类的对象形状和大小,这有助于减少误报的数量。在 YOLO v7 中实现一种名为“focal loss”的新损失函数是一项重大改进。早期版本的 YOLO 使用标准的交叉熵损失函数,该函数在识别小型对象方面效果不佳。Focal loss 通过降低易于分类的示例的损失并强调难以检测的示例来解决这个问题。 此外,YOLO v7 比早期版本具有更高的分辨率。与处理 416x416 像素图像的 YOLO v3 相比,它以 608x608 像素的分辨率处理图像。YOLO v7 凭借其更高的分辨率,能够更精确地检测小型对象。 YOLOV7 的优点
YOLO V8Ultralytics 已确认将推出 YOLO v8,该版本有望在其前代产品的基础上提供更多功能并提高性能。YOLO v8 中的新 API 简化了 CPU 和 GPU 设备上的训练和推理,同时该框架仍支持早期的 YOLO 版本。开发人员仍在编写科学出版物,其中将提供有关模型设计和性能的详细解释。 |
散点图是一种数据可视化方法,用于显示两个数值变量之间的关系。在 Python 中,有一个名为 DataFrame 的类,可以使用 pandas 绘制散点图,此类的成员称为 plot。通过使用...
阅读 6 分钟
| 获取城市天气报告 在本教程中,我们将使用 Django 创建一个天气应用程序;此应用程序将显示所搜索城市的天气。这是一个简单的 Django 项目,可帮助初学者理解 Django 的基本概念。我们还将...
7 分钟阅读
在本教程中,我们将学习如何将人类语言文本转换为类似人类的语音。有时我们更喜欢听内容而不是阅读。我们可以在听关键文件数据时进行多任务处理。Python 提供了许多 API 将文本转换为语音。这个...
阅读 4 分钟
确定星座 一旦我们有了用户的出生日期,我们就可以继续确定他们的星座。程序逻辑将使用预定义的每个星座的日期范围与提供的日期进行比较。例如,我们可以推断用户是...
阅读 4 分钟
本教程的问题陈述是,如果我们给定一个长度为 n 的已排序数组和一个整数 x,那么我们需要找到 x 在给定数组中的较低插入索引。任何元素的较低插入索引是...
5 分钟阅读
Python 提供了内置方法来向列表中追加或添加元素。我们还可以将一个列表追加到另一个列表中。这些方法如下所示。 append(elmt) - 它在列表末尾追加值。 insert(index, elmt) - 它在指定位置插入值...
阅读 2 分钟
break 是 Python 中循环的控制语句。它用于管理循环的顺序。假设我们想结束一个循环并继续执行后面的代码;break 可以帮助我们做到这一点。当一个...
阅读 2 分钟
理解二维码 二维码是一种机器可读的条形码,以二维像素化形式设计。二维码可用于存储各种数据。“QR”是“快速响应”(Quick Response)的缩写。二维码于1994年由日本工程师原昌宏(Masahiro Hara)发明...
5 分钟阅读
Selenium 是一个强大的自动化工具,广泛用于网络应用程序测试和网络抓取。虽然 Selenium 提供了与 Web 元素交互和导航网页的各种策略,但有时您需要更高级的功能来执行特定任务。其中一项此类高级功能是...
阅读 4 分钟
在本文中,我们将讨论 Python 中的 Wikipedia 模块,并讨论如何使用 Python 脚本利用 Wikipedia 模块。我们将从 Wikipedia 获取大量信息。引言 互联网是信息最重要的来源。所有知识都只是...
阅读 6 分钟
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
