URL 是什么?4 Aug 2025 | 19 分钟阅读 URL 是一种统一资源标识符,是万维网上资源的地址以及访问它的协议。它用于指示 Web 资源的某个位置,以便访问网页。例如,要访问 TpointTech 网站,您将访问 URL www.TpointTech.com,这是TpointTech 网站的 URL。  URL 将用户导向在线上的特定资源,例如视频、网页或其他资源。当您在 Google 上搜索任何查询时,它将显示与搜索查询相关的所有资源的多个 URL。显示的 URL 是访问网页的超链接。 URL(统一资源定位符)包含以下信息:
URL 的其他信息通过以下示例进行说明: 例如:tpt.htm,它表示 tpt.htm 是位于 TpointTech.com 服务器上的一个文件。 http:// 或 https:// http 是一个协议,代表超文本传输协议。它告诉浏览器使用哪种协议来访问域中指定的信息。 https(超文本传输安全协议)是比 http 更高级的协议,因为它涉及安全性。它保证通过 HTTP 传输的信息是安全且加密的。冒号(:)和两个斜杠(//)用于将协议与 URL 的其余部分分开。 www. www 用于区分内容,代表万维网。URL 的这一部分很多时候可以省略,因为它不是必需的。例如,如果您输入“http://TpointTech.com”,您仍然会进入 TpointTech 网站。对于重要的子页面,此部分也可以被替换,这称为子域。 TpointTech.com TpointTech.com 是网站的域名,.com 称为 TLD 或后缀。它有助于识别网站的位置或类型。例如,“.org”代表组织,“.co.uk”代表英国,“.com”代表商业。有各种类型的域名后缀,您需要通过域名注册商注册名称才能获得域名。 tpt.htm tpt.htm 是网页的名称,.htm 是网页的文件扩展名,表示该文件是 HTML 文件。互联网上还有许多其他文件扩展名,例如 .php、.html、.xml、.jpg、.gif、.asp、.cgi 等。 URL 位于何处?URL 位于浏览器窗口顶部的地址栏或搜索栏中。除非您的浏览器处于全屏模式,否则 URL 在台式电脑和笔记本电脑上始终可见。在大多数智能手机和平板电脑上,当您向下滚动页面时,URL 会消失,仅在可见时显示域名。要显示地址栏,您需要向上滚动页面。并且,如果仅显示域名而您想查看完整地址,请点按地址栏以显示完整地址。 URL 中不能使用哪些字符?许多人知道 URL 中不允许有空格。URL 字符串只能包含符号 ! $-_+*'(),包括 字母数字字符,如 RFC 1738 文档所述。任何其他字符如果需要,都必须在 URL 中进行编码。 IP 地址是否与 Web 地址或 URL 相同?IP 地址与 Web 地址或 URL 不同,它是分配给网络上每个设备的唯一数字。域名被分配了万维网上唯一的 IP 地址,当输入 TpointTech.com 等 URL 时,DNS 会将其转换为 IP 地址,路由器使用该 IP 地址来查找 Web 服务器。与使用 IP 地址相比,域名更易于人类记忆。例如,记住 216.58.216.164 这样的 IP 地址很难,而记住“TpointTech.com”则容易得多。 为什么需要 URL?
什么是 URL 重定向?URL 重定向是 Web 服务器的一项功能,它会将您的 URL 指向另一个 URL。例如,假设您有一个旧 URL“myvlogsite.com”,并且您希望访问者直接访问新 URL *“TpointTech.com”*。重定向是最佳解决方案;当有人在浏览器中输入“myvlogsite.com”时,他们将被重定向到新 URL *“TpointTech.com”*。有各种类型的重定向供 Web 开发人员使用,例如 HTTP 3xx 系列状态码、手动重定向、JavaScript、元标记刷新、服务器端脚本、框架重定向等。此外,URL 重定向也可能被称为 URL 转发、域名转发、HTTP 代码 3xx 重定向和域名重定向。 Web 用户可能从一个 URL 重定向到另一个 URL 的原因有很多,如下所示:
URL 重定向也可能通过网络钓鱼等非法活动给用户及其计算机带来问题。此外,它还可以用于从 Web 浏览器中移除搜索结果,但如今大多数搜索引擎都能检测到这些类型的欺诈尝试。重定向网页,最常见的方法是使用几个 HTTP 协议 3xx 系列代码。该系列中的成员具有各种属性,如下所示:
不同类型的重定向1. 301 重定向 这是一种永久的未掩码重定向,它会自动指示 Web 浏览器从一个网站目标移动到另一个网站目标。它是实现重定向的最常见且对搜索引擎友好的方法之一。当您的网站永久移动到新地址时,应使用此方法。  2. 重定向也可以用于某些编程语言,如 PHP;程序员可以使用规范的 301 重定向来更改域中的多个页面。此外,301 重定向会传递 90% 以上的链接权重,因此它对 SEO 也有益。 3. 302 重定向 这是一种临时的未掩码重定向,并不常用。它是用于当某个 URL 暂时更改为不同地址时的 HTTP 状态码的名称。搜索引擎不会索引目标 URL,而是索引原始 URL,并在搜索结果中显示它。浏览器借助 302 重定向从一个 URL 重定向到另一个 URL。此外,它被认为是永久重定向,并且基于不同的 HTTP 状态码。在许多情况下,它可以为用户返回更清晰、更简单的 URL。要使用 302 重定向,其他技术和不同的搜索引擎有其特定的策略。 4. 303 重定向 303 重定向也称为 HTTP 303,是对 HTTP 状态码的响应。它是作为对 URI(统一资源标识符)的请求的响应而产生的特定类型的重定向。它也有自己的语法;W3C 指定如果对不同 URI 发出请求,则使用 GET 方法来访问所需的目标。 何时应使用重定向?1. 您有重复内容 重复内容是指在页面上出现多次的内容。Google 上有多个页面包含重复内容。在这种情况下,Google 很难理解哪个页面是正确的。您可以在重复内容上使用 301 重定向将其指向原始页面。这将为用户提供更好的体验,并有助于提高您的搜索引擎排名。 2. 您已更改域名 当您更改域名并且可能不想丢失任何已建立的链接时,使用重定向非常有用。 3. 您有多个域名 为了保护在线品牌,有些人购买多个域名。因此,他们需要将任何旧域名重定向到新域名。许多公司这样做是为了从常见的拼写错误中获得更多流量。此外,他们还可以防止竞争对手购买相似的域名,并将这些域名重定向到自己的网站。 URL 和 URI 的区别 URL 和 URI 之间有许多区别,如下所示:
URL 类型URL,或统一资源定位符,是查找特定文件、网页、图像或其他资源的必要工具,并访问它们。根据其结构和功能上的差异,URL 可分为四类:绝对 URL、相对 URL、静态 URL 和动态 URL。不同的 Web 用户,包括开发人员和 SEO 专家,都应该清楚所有类别。 1. 绝对 URL 计算中的资源总是包含在绝对 URL 中。它包括协议(如 http 或 https)、域名和完整的资源路径。它完全自给自足,可用于从任何地方访问资源,而无论当前页面如何。 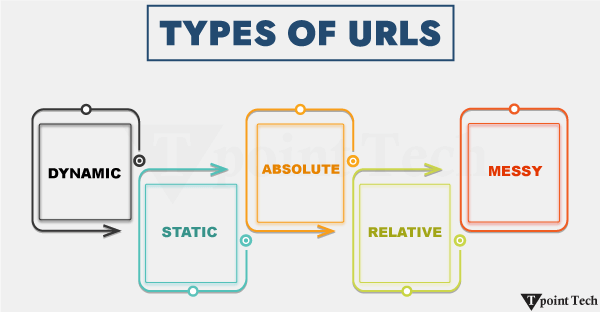 示例 绝对 URL 几乎总是在提供到页面外部的网站或资源的链接时使用。它们确保在 Web 的所有上下文中都有一个一致且无歧义的链接,因此它们是可靠的。 2. 相对 URL 相对 URL 是部分链接。它们省略协议和域名,并相对于当前文档的基础路径提供资源。相对 URL 在链接到同一网站的页面时特别有用。 示例 在迁移站点或进行结构更改时,它们很有用,因为域名更改不需要手动更改每个超链接,因为它是内部链接。 3. 静态 URL 静态 URL 指的是一个简单且随时间不变的 Web 地址。静态 URL 缺少动态内容或任何形式的查询参数。静态 URL 指向固定的公司信息或博客文章。 示例 静态 URL 易于阅读、共享且用户友好。它们被搜索引擎访问和青睐。静态 URL 的内容不会随时间变化,只有在手动更新时才会变化。 4. 动态 URL 动态 URL 是通过查询字符串发送的参数创建的。它们在从数据库提取信息的网站中最为流行,例如搜索结果或目录。 示例 动态 URL 的可读性以及其结构是可能对其 SEO 产生负面影响的两个因素。尽管存在缺点,动态 URL 允许使用单个模板的网站轻松提供各种内容。 URL 的组成部分URL 或统一资源定位符由识别和定位资源的各种元素组成。了解 URL 的每个部分以及 Web 地址,有助于用户和开发人员理解浏览器如何解释它们。 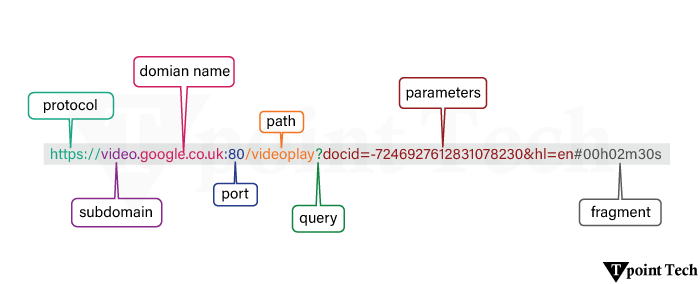 标准的 URL 可以分为以下几部分: 每个部分都有特定的作用,下面将详细解释。 1. 协议:协议是 Web 浏览器和服务器之间通信方法的标识符。它是用户和资源之间的屏障。
2. 子域:子域位于主域名前面,用于组织目的或分隔单个网站的不同部分。 常见示例包括:
3. 域名:域名是 URL 的人类可读部分,标识一个网站。它是与 IP 地址关联的名称。 示例 域名已注册并链接到特定的、唯一的 IP 地址。 4. 顶级域名 (TLD):TLD 或顶级域名是指域名中的最后一部分,它通常显示网站的性质或类别或地理位置。
5. 端口(可选):端口有助于识别服务器上连接的特定终结点。对于 HTTP 和 HTTPS 协议,浏览器会自动设置端口 80 和 443,但必要时可以使用其他端口。 示例 这告诉浏览器访问 8080 端口上的站点。 6. 路径:路径以精确的方式显示服务器上特定文件或资源的位置。 示例 它以分层方式显示站点上的目录和文件结构。 7. 查询字符串:查询字符串前面有一个问号?它由名称和值对组成,这些对之间用与号(&)分隔。这用于向服务器提供额外信息,尤其是在动态页面中。 示例 8. 片段标识符:片段以 # 开始,表示网页中的特定部分,主要用于文档内的导航目的。 示例 这告诉浏览器滚动到页面上标记为“introduction”的部分。 常见的 URL 错误URL 是指统一资源定位符,这意味着 URL 为 Web 上的一切都提供了地址。URL 的任何问题都可能导致可用性、搜索引擎功能和可访问性等功能出现故障。这些问题不仅会惹恼用户,还会损害您网站的形象和 SEO 分数。  1. 404 未找到 当浏览器可以连接到托管网站的服务器,但服务器上没有该网站的页面时,会发生 404 未找到错误。这是人们面临的最常见错误之一。 常见原因
如何修复 设置 301 重定向策略,通常设置为在内容移动时向客户端显示其内容仍然存在且已移动。此外,定期使用 Google Console 或检查器进行扫描。 2. 403 禁止访问 403 禁止访问错误意味着即使服务器运行正常,并且请求已被理解,但未授予对资源的访问权限,也没有提供对资源的访问。 常见原因
如何修复 通过更改服务器上相关的文件和目录权限,确保用户能够不受阻碍地访问资源。 3. 500 内部服务器错误 您的服务器遇到了错误,没有进一步的详细信息可用。服务器没有进一步的说明。最常见的服务器错误是 500 错误。 常见原因
如何修复 恢复适当的服务器权限,恢复适当的配置文件,或在沙箱中运行适当的脚本来识别错误。 4. 301/302 重定向错误 用户和搜索引擎经常遇到重定向。重定向分为两类:301 和 302。重定向类别 301 和 302 对于提高用户满意度至关重要。 常见问题
如何修复 实现重定向后测试其配置,并且不要添加不必要的链。使用浏览器的开发者工具进行验证,并结合在线上可用的各种重定向检查器。 URL 和安全通往敏感数据访问的门户统一资源定位符帮助用户浏览互联网和收集信息,但 URL 也带来一些风险。URL 可能导致网络钓鱼、恶意软件分发或未经授权的数据库访问。理解涉及的风险以及为避免这些风险可以采取的措施,对用户和 Web 开发人员都很重要。 下面从安全的角度介绍了一些 URL 问题以及防范措施: 1. 网络钓鱼 URL 网络钓鱼是一种社会工程攻击,攻击者会设计一个网页来收集用户的用户名、密码、信用卡号和其他个人信息。例如,网络钓鱼 URL 可能是模仿知名域名的域名。 示例 此示例声称是知名域名的登录页,但实际上并不属于该域名。它是一个旨在欺骗用户的域名。此类域名创建的唯一目的是捕获登录信息。通常,这些链接通过短信和电子邮件发送,其中伪造网页旨在欺骗用户提供密码。 保护技巧
2. URL 欺骗 URL 欺骗:创建一个 URL 或将其伪装成另一个 URL 以达到恶意目的的人被称为 URL 欺骗者。URL 缩短服务和点击欺骗的锚文本是实现 URL 欺骗的一些方式。例如,攻击者可以伪装成 www.bank.com,但 URL 链接到 www.banк.com,其中“k”被西里尔字母“к”替换。 如何保持安全
3. 通过 URL 参数进行 SQL 注入 SQL 注入是一种更高级、危险性更高的攻击,它允许黑客利用 Web 表单或 URL 字段在数据库中执行极具破坏性的命令。 示例 可以设想一个 Web 应用程序,在这种情况下,它使用输入来构建 SQL 查询而没有任何保护措施;其后果可能导致无限且不受限制的访问漏洞、数据泄露和数据销毁。这是网站安全风险中非常重要的一项。 预防策略
URL 编码和解码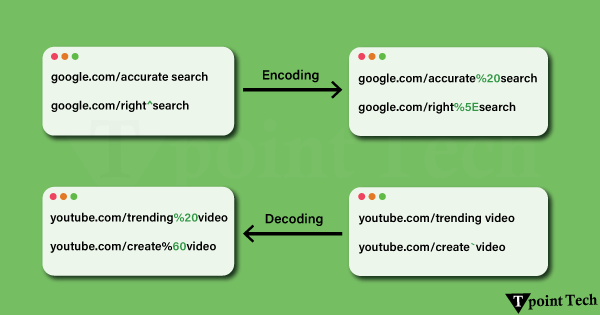 什么是 URL 编码? 编码意味着以安全地通过 Internet 发送字符的方式处理字符。例如,URL 编码仅限于 ASCII 字符集。 超出该范围的任何字符,或用于特定 URL 目的的字符,都需要进行编码以保持 URL 中数据的结构和可读性。处理 URL 也有一些保留字符需要处理。例如:
URL 编码示例 假设您有一个搜索查询 URL 在此,“web development”中的空格不允许直接出现在 URL 中。编码后,它变为 此格式现在可以安全地用于 Web 请求。 什么是 URL 解码? URL 解码反转编码。它将 URL 的编码字符改回原始格式。当您在浏览器中键入或粘贴编码的 URL 时,浏览器会自动对其进行解码,以便您可以与目标内容进行交互。 在 Web 编程中,解码在处理查询字符串、表单数据或 URL 参数时很有用。通常,需要对数据进行解码,以便可以正确显示或用于进一步的逻辑。
URL 编码和解码在通过 Web 进行数据交换中都至关重要,因为这两种概念都保护了通过 URL 交换的数据的完整性和安全性。 URL 的工作原理(幕后)当用户输入 URL(统一资源定位符)并点击 Web 浏览器时,会发送一个网页检索和显示请求,从而触发一系列复杂的 Web 页服务器交互,这些交互将在 Web 服务器上进行处理。 以下是查找、请求和创建网页的步骤的概览。第一步。 1. DNS 解析(域名系统) 域名顺序编号。大多数用户在域名 www.abc.com 中遇到 DNS 系统的标志。域名允许使用计算机服务器标识符。在用户服务器标识符的情况下,可以提及 IP(Internet Protocol)。 例如,IP 93.184.216.34。浏览器在上述 IP 检索阶段使用 DNS 服务器。
此 DNS 查询使浏览器知道应将请求发送到何处。 2. 浏览器建立连接 浏览器 使用 IP 地址建立连接,现在浏览器可以搜索所需的服务器。可以通过 TCP/IP 连接访问服务器,TCP/IP 是网络的骨干。
3. 发出请求 在 HTTPS 的情况下,会通过 TLS 进行预通信握手,以确保浏览器和服务器通信安全。 请求可能如下所示: 如果存在表单或登录,可能会发出 POST 请求,以向服务器提供所需的数据。 4. 服务器响应 服务器响应请求并完成请求处理。服务器提供的响应包括:
如果提供了必要的数据,浏览器将检索所需的信息。但是,它可能会提供错误信息,例如“404 页面未找到”。 5. 渲染页面 最后,浏览器开始渲染数据。它检索 HTML 文档以及任何补充资源,例如样式表、JavaScript 文件和图像。使用渲染引擎,构建 DOM(文档对象模型),应用样式,执行脚本,以向最终用户提供交互式网页。 下一主题如何将 iPhone 备份到电脑 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
