Python 中的 ANOVA 检验2025年3月17日 | 阅读 10 分钟 以下教程基于数据分析;我们将详细讨论方差分析 (ANOVA),以及在 Python 编程语言中执行它的过程。ANOVA 通常用于心理学研究。 在以下教程中,我们将了解如何借助 SciPy 库执行 ANOVA,并在 Python 中“手动”评估它,利用 Pyyttbl 和 Statsmodels。 理解 ANOVA 测试我们可以将方差分析测试(也称为 ANOVA)视为 T 检验的推广,用于多个组。通常,我们使用独立 T 检验来比较两个组之间状态的均值。当我们需要比较两个以上组之间状态的均值时,我们使用 ANOVA 测试。 ANOVA 测试检查模型中某处是否存在平均值差异(检查是否存在总体效应);但是,此方法不会告诉我们差异的位置(如果存在)。我们可以通过进行事后检验来找到组之间差异的位置。 但是,在执行任何测试之前,我们首先必须定义零假设和备择假设
我们可以通过比较两种类型的变异来执行 ANOVA 测试。第一种变异是样本均值之间,另一种是每个样本内部。下面显示的公式描述了单向 ANOVA 测试统计量。 ANOVA 公式输出的 F 统计量(也称为 F 比率)能够分析多组数据,以确定样本之间和样本内部的变异性。 我们可以将单向 ANOVA 测试的公式写成如下所示  其中, yi - 第 ith 组中的样本均值 ni - 第 ith 组中的观测值数量 y - 数据的总均值 k - 组的总数 yij - k 组中的第 jth 个观测值 N - 总样本量 当我们绘制 ANOVA 表时,我们可以看到所有上述组件采用以下格式  通常,如果 F 的 p 值小于 0.05,则排除零假设,并维持备择假设。在零假设被拒绝的情况下,我们可以说所有集合/组的均值不相等。 注意:如果被测试组之间没有真实差异(即零假设),则 ANOVA 测试的 F 比率统计量将接近 1。ANOVA 测试假设在执行 ANOVA 测试之前,我们必须做出某些假设,如下所示
我们可以借助 Brown-Forsythe 检验或 Levene 检验等检验来检验方差同质性的假设。我们还可以借助直方图、峰度和偏度值,或借助 Kolmogorov-Smirnov、Shapiro-Wilk 或 Q-Q 图等检验来检验分数分布的正态性。我们还可以从研究设计中确定独立性假设。 值得注意的是,ANOVA 测试对违反独立性假设不稳健。这意味着,即使有人试图违反正态性或同质性假设,他们也可以进行测试并相信结果。 然而,如果独立性假设被违反,ANOVA 测试的输出是不可接受的。通常,如果组大小相等,则伴随同质性违反的分析被认为是稳健的。如果样本量大,则伴随正态性违反的 ANOVA 测试通常是可行的。 理解 ANOVA 测试的类型ANOVA 测试可分为三种主要类型。这些类型如下所示
单向 ANOVA 测试只有一个自变量的方差分析测试称为单向 ANOVA 测试。 例如,一个国家可以评估冠状病毒病例的差异,一个国家可以有多个类别进行比较。 双向 ANOVA 测试有两个自变量的方差分析测试称为双向 ANOVA 测试。此测试也称为因子 ANOVA 测试。 例如,扩展上述示例,双向 ANOVA 可以检查冠状病毒病例(因变量)在年龄组(第一个自变量)和性别(第二个自变量)方面的差异。双向 ANOVA 可用于检查这两个自变量之间的交互作用。交互作用表示差异在自变量的所有类别中不均匀。 假设老年组可能比青年组的冠状病毒病例总体更高;然而,这种差异在欧洲国家与亚洲国家可能有所不同。 n 向 ANOVA 测试如果研究人员使用两个以上的自变量,则方差分析测试被认为是n 向 ANOVA 测试。这里的 n 代表我们拥有的自变量的数量。此测试也称为 MANOVA 测试。 例如,我们可以同时使用国家、年龄组、性别、种族等自变量来检查冠状病毒病例的潜在差异。 ANOVA 测试将为我们提供一个单一的(单变量)F 值;然而,MANOVA 测试将为我们提供一个多变量 F 值。 理解 ANOVA 中的有重复和无重复通常,我们中的一些人可能会听到 ANOVA 测试中的有重复和无重复。让我们了解这些是什么 有重复的双向 ANOVA 测试当两个组及其成员执行多项任务时,进行有重复的双向 ANOVA 测试。 例如,假设冠状病毒疫苗仍在开发中。医生正在进行两种不同的治疗,以治愈两组感染病毒的患者。 无重复的双向 ANOVA 测试当只有一个组,并且我们正在对同一组进行双重测试时,进行无重复的双向 ANOVA 测试。 例如,假设疫苗已成功开发,研究人员正在对一组志愿者进行接种前后测试,以观察疫苗是否正常工作。 理解事后 ANOVA 测试在进行 ANOVA 测试时,我们试图确定组之间是否存在统计学上的显著差异。如果我们发现一个,那么我们将不得不测试组差异的位置。 因此,研究人员使用事后检验来检查哪些组彼此不同。 我们可以进行事后检验,这些检验是检查组之间平均值差异的 t 检验。我们可以进行多项多重比较检验来控制 I 型错误率,包括 Bonferroni、Dunnet、Scheffe 和 Turkey 检验。 现在,我们将只使用 Python 编程语言理解单向 ANOVA 测试。 理解 Python 中的单向 ANOVA 测试我们已将执行 ANOVA 测试的过程分为不同的部分。 导入所需的库为了开始使用 ANOVA 测试,让我们为项目导入一些必要的库和模块。 语法 假设让我们考虑问题的假设 “对于每种饮食,人们体重的均值是相同的。” 加载数据在以下问题中,我们将使用由谢菲尔德大学设计的饮食数据集。该数据集包含一个二进制变量作为性别,其中 1 代表男性,0 代表女性。 让我们考虑相同的以下语法 语法 理解数据集成功导入数据集后,让我们打印一些数据以了解其含义。 示例 - 输出 Person gender Age Height pre.weight Diet weight6weeks 0 25 41 171 60 2 60.0 1 26 32 174 103 2 103.0 2 1 0 22 159 58 1 54.2 3 2 0 46 192 60 1 54.0 4 3 0 55 170 64 1 63.3 现在让我们打印数据集中存在的总行数。 示例 - 输出 The total number of rows in the dataset: 546 检查缺失值现在,我们必须查看数据集中是否存在任何缺失值。我们可以使用以下语法进行检查。 示例 - 输出 [' ' '0' '1'] Person gender Age Height pre.weight Diet weight6weeks 0 25 41 171 60 2 60.0 1 26 32 174 103 2 103.0 我们可以观察到“性别”列中有两个条目包含缺失值。现在让我们找到数据集中缺失值的总百分比。 示例 - 输出 Percentage of missing values in the dataset: 2.56% 正如我们所观察到的,数据集中大约有 3% 的缺失值。我们可以忽略、删除或借助最接近的身高均值来分类其性别。 理解体重分布在以下步骤中,我们将使用 distplot() 函数绘制图表,以了解样本数据中的体重分布。让我们考虑代码片段。 示例 - 输出  我们还可以为数据集中的每个性别绘制分布图。这是相同的语法 示例 - 输出 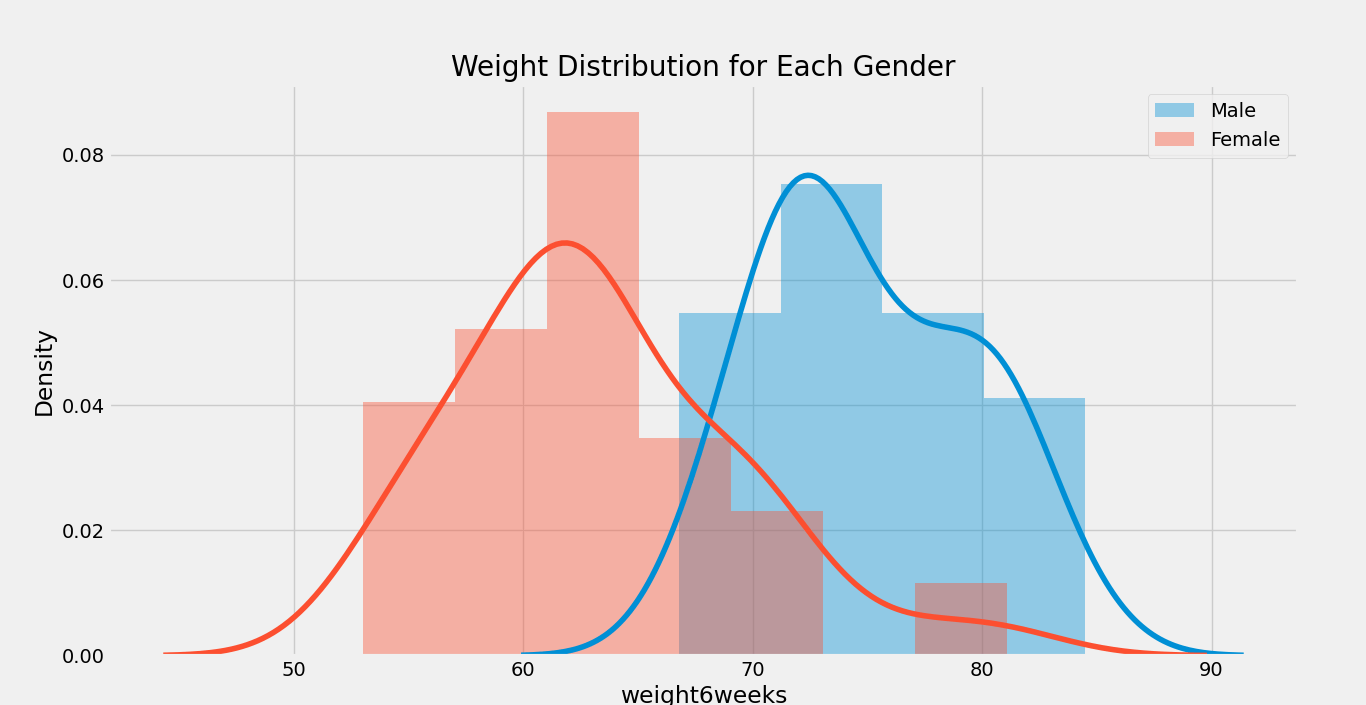 我们还可以使用以下函数显示每个性别的分布图。 示例 输出 图 1  图 2  现在,我们将使用下面给出的代码片段,根据“性别”列计算均值、中位数、非零计数和标准差 示例 - 输出 mean median count_nonzero std
gender
81.500000 81.5 2.0 30.405592
0 63.223256 62.4 43.0 6.150874
1 75.015152 73.9 33.0 4.629398
正如我们所观察到的,我们已经根据性别估计了所需的统计测量值。我们还可以根据性别和饮食对这些统计测量值进行分类。 示例 - 输出 mean median count_nonzero std
gender Diet
2 81.500000 81.50 2.0 30.405592
0 1 64.878571 64.50 14.0 6.877296
2 62.178571 61.15 14.0 6.274635
3 62.653333 61.80 15.0 5.370537
1 1 76.150000 75.75 10.0 5.439414
2 73.163636 72.70 11.0 3.818448
3 75.766667 76.35 12.0 4.434848
我们可以观察到,饮食中女性的体重略有差异;然而,这似乎不影响男性。 执行单向 ANOVA 测试单向 ANOVA 测试的零假设是  该测试试图检查此假设是否正确。 让我们考虑最初确定 95% 的置信水平,这也意味着我们将只接受 5% 的错误率。 示例 - 输出 ANOVA table for Female
----------------------
sum_sq df F PR(>F)
Diet 559.680764 1.0 7.17969 0.010566
Residual 3196.086677 41.0 NaN NaN
ANOVA table for Male
----------------------
sum_sq df F PR(>F)
Diet 559.680764 1.0 7.17969 0.010566
Residual 3196.086677 41.0 NaN NaN
在上面的输出中,我们可以观察到两个 p 值 (PR (> F)):男性和女性。 对于男性,我们不能接受低于 95% 置信水平的零假设,因为 p 值大于 alpha 值,即 0.05 < 0.512784。因此,在提供这三种饮食类型后,男性的体重没有发现差异。 对于女性,由于 p 值 PR (> F) 低于错误率,即 0.05 > 0.010566,我们可以拒绝零假设。此声明表明我们非常确信女性在饮食方面存在身高差异。 因此,现在我们了解了饮食对女性的影响;但是,我们不清楚饮食之间的差异。因此,我们将借助 Tukey HSD(诚实显著性差异)检验进行事后分析。 让我们考虑相同的以下代码片段。 示例 - 输出 Multiple Comparison of Means - Tukey HSD, FWER=0.05
=====================================================
group1 group2 meandiff p-adj lower upper reject
-----------------------------------------------------
1 2 -3.5714 0.5437 -11.7861 4.6432 False
1 3 -8.7714 0.0307 -16.848 -0.6948 True
2 3 -5.2 0.2719 -13.2766 2.8766 False
-----------------------------------------------------
Unique diet groups: [1 2 3]
从上面的输出中我们可以观察到,我们只能拒绝第一种和第三种饮食类型之间的零假设,这意味着饮食 1 和饮食 3 的体重存在统计学上的显著差异。 下一主题Python 程序计算复利 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
