Python 中的用户定义数据结构2025年3月17日 | 阅读 14 分钟 用户自定义数据结构在 Python 中不是内置的,但我们仍然可以实现它们。我们可以使用 Python 中现有的功能选项来创建新的数据结构。例如,当我们说 `list = []` 时,Python 就会将其识别为一个列表并调用所有与列表相关的操作。但是,当我们说“链表”或“队列”时,Python 就不知道这些是什么。在本文中,我们将讨论 Python 中的一些用户自定义数据结构。 1. 链表链表,顾名思义,是相互连接的。链表中的每个节点都包含两个部分:数据字段,存储数据/值;以及 next 字段,存储指向下一个节点的引用,从而将它们连接起来。它是一个线性数据结构,但元素不存储在连续的内存位置。 链表的重要特点
 此外,链表有三种类型
一个简单的链表看起来像这样 如上图所示,头节点是第一个节点,最后一个节点的下一个(引用)部分保存 None。 双链表看起来像这样 在双链表中,每个节点将有三个部分。头节点保存第一个节点的引用,第一个节点的“前一个”部分保存 None,最后一个节点的 next 字段指向 None。每个节点将保存两个引用以及数据,一个指向其前一个节点,下一个指向其后一个节点。 循环链表循环链表可以是单向的也可以是双向的 循环单链表  它是一个单链表,但列表中的最后一个节点保存第一个节点的引用,形成一个环。 循环双链表  它是一个双链表,但列表中的最后一个节点保存第一个节点的引用,第一个节点的“前一个”部分保存最后一个节点的引用,形成一个环。 示例程序输出 Displaying the linked list: 10 -> 20 -> 30 -> None Traversing from node to node: 10 20 30 After inserting 5 at the beginning: 5 -> 10 -> 20 -> 30 -> None After inserting 40 at the end: 5 -> 10 -> 20 -> 30 -> 40 -> None After inserting a node after 15: 5 -> 10 -> 15 -> 20 -> 30 -> 40 -> None After inserting a node before 30: 5 -> 10 -> 15 -> 20 -> 25 -> 30 -> 40 -> None 2. 栈栈是一种线性数据结构。它基于“LIFO”原则实现:后进先出。这意味着最后插入栈的元素将是第一个被删除的元素。栈只有一个开口,这意味着要插入或删除元素,我们需要使用同一端。当我们向栈中插入元素时,我们将元素一个接一个地插入——新元素在现有元素之上。插入所有元素后,如果我们要从栈中删除元素,最后插入的元素将是第一个出来的。 术语
Python 中用于栈的函数栈的实现我们可以实现一个栈
输出 The elements of the stack 1 2 3 The first element to come out: 3 The second element to come out: 2 Final stack: [1]
输出 Stack without pushing any elements: head None Stack after pushing elements: head 14 13 12 11 10 None After pop 3 times: 14 13 12 Stack: head 11 10 None Element at the top of the stack: 11 Pop till stack becomes empty: 11 10 Traceback (most recent call last): File "D:\Programs\DSA \Language\Python data structures programs\stacks.py", line 59, in 我们编写了两个方法 push 和 pop 来实现一个栈。我们需要确保两点
3. 队列队列是一种线性数据结构,类似于栈,但队列的实现原则是 FIFO - 先进先出。这意味着第一个插入队列的元素将是第一个从队列中出来的元素。 关于队列的重要事项
术语
我们可以在 Python 中实现一个队列
输出 Using lists: Queue: [] Inserting elements: Queue: [1, 2, 3, 4, 5] Deleting two elements: Final queue: [3, 4, 5] Using the deque class in the collection module Inserting elements: Queue: deque([6, 7, 8, 9, 10]) Deleting elements: Final queue: deque([8, 9, 10]) Using the Queue class in the queue module Inserting elements: Queue: 0 1 2 3 4 5 Is the queue full? True Deleting elements: Final queue: [2, 3, 4, 5] size of the queue: 4
在某些高优先级情况下,无论顺序如何,我们都必须首先处理某些方面。对于这种情况,有一种队列类型:优先级队列。 队列和优先级队列的区别
实施输出 Created Q: 3 2 19 90 11 Dequeue operation: The element to be deleted: 90 Final Queue: 2 3 11 19 4. 二叉树树是节点的层次表示。家谱是树的实时示例。每个节点只能有两个子节点。层次最高或最顶部的节点称为“根节点”。 关于二叉树的重要事项
输出 Preorder traversal: 4 3 2 3 5 Postorder traversal: 2 3 3 5 4 Inorder traversal: 2 3 3 4 5 BFS traversal: 4 3 5 2 3
这是一个 BST 的例子:  5. 图简而言之,G = (V, E)。这里 V 代表顶点,E 代表边。图是一种非线性数据结构。它由由边连接的节点/顶点组成。顶点和边都必须是有限集。一条边可以表示为 (u, v),其中 u 和 v 是边连接的两个顶点。 图可以是定向的或无定向的。在无定向图中,E = (u, v) 和 E = (v, u) 是相同的,而在定向图中,它们是不同的,因为方向很重要。因此,边表示为边连接的顶点的有序对。 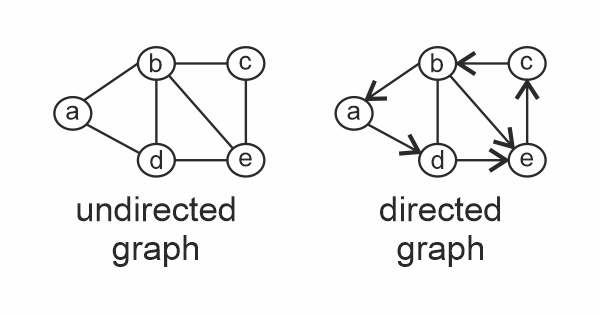 关于图的重要事项
邻接矩阵:邻接矩阵是一个 (V X V) 二维数组,其中 V 代表图中的顶点。在矩阵 adj[u][v] 中,如果图中存在 u 和 v 之间的边,则 adj[u][v] = 1,否则赋值为 0。
这是表示方式   这是一个非常简单的图的邻接矩阵实现代码  输出 0 3 0 12 4 3 0 5 0 0 0 5 0 0 2 12 0 0 0 7 4 0 2 7 0 邻接表 为了实现邻接表,我们使用一个链表数组/列表来表示图中的顶点和边。表示中使用的链表数量等于图中顶点的数量。
这是表示方式 

这是一个用邻接表表示图的简单代码输出 0: -> 2 -> 1 1: -> 4 -> 2 -> 3 -> 0 2: -> 4 -> 1 -> 0 3: -> 4 -> 1 4: -> 2 -> 3 -> 1 理解创建了一个大小等于图中顶点数的列表,所有值都为 None [None, None, None, None, None] 现在,当调用 edge(源, 目标) 时 使用类节点创建一个目标节点,其下一个指向数组中的源,然后将链表分配给数组中的源位置。 当调用 edge(0, 1) 时 [1 -> None, 0 -> None, None, None, None] edge(0, 2) [2 -> 1 -> None, 0 -> None, 0 -> None, None, None] edge(1, 3) [2 -> 1 -> None, 3 -> 0 -> None, 0 -> None, 1 -> None, None] 这样,所有相邻节点都连接到数组中的链表。 下一个主题查找只出现一次的数字 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India



